
Ollama gebruiken in ServBay
ServBay integreert krachtige lokale AI-mogelijkheden in je ontwikkelomgeving, waardoor je met Ollama eenvoudig diverse open-source grote taalmodellen (LLM) op macOS kunt draaien. Dit document begeleidt je bij het inschakelen, configureren en beheren van Ollama en de modellen ervan in ServBay, en laat je snel aan de slag gaan.
Overzicht
Ollama is een populair hulpmiddel dat het proces van grote taalmodellen downloaden, instellen en lokaal uitvoeren vereenvoudigt. ServBay integreert Ollama als een losstaand softwarepakket met een grafische beheerinterface, waarmee ontwikkelaars eenvoudig kunnen:
- Ollama met één klik starten, stoppen en herstarten.
- Ollama-parameters instellen via een visuele interface.
- Ondersteunde LLM-modellen bladeren, downloaden en beheren.
- Lokaal AI-applicaties ontwikkelen, testen en experimenteren zonder afhankelijk te zijn van clouddiensten.
Vereisten
- ServBay moet geïnstalleerd en actief zijn op je macOS-systeem.
Ollama-service inschakelen en beheren
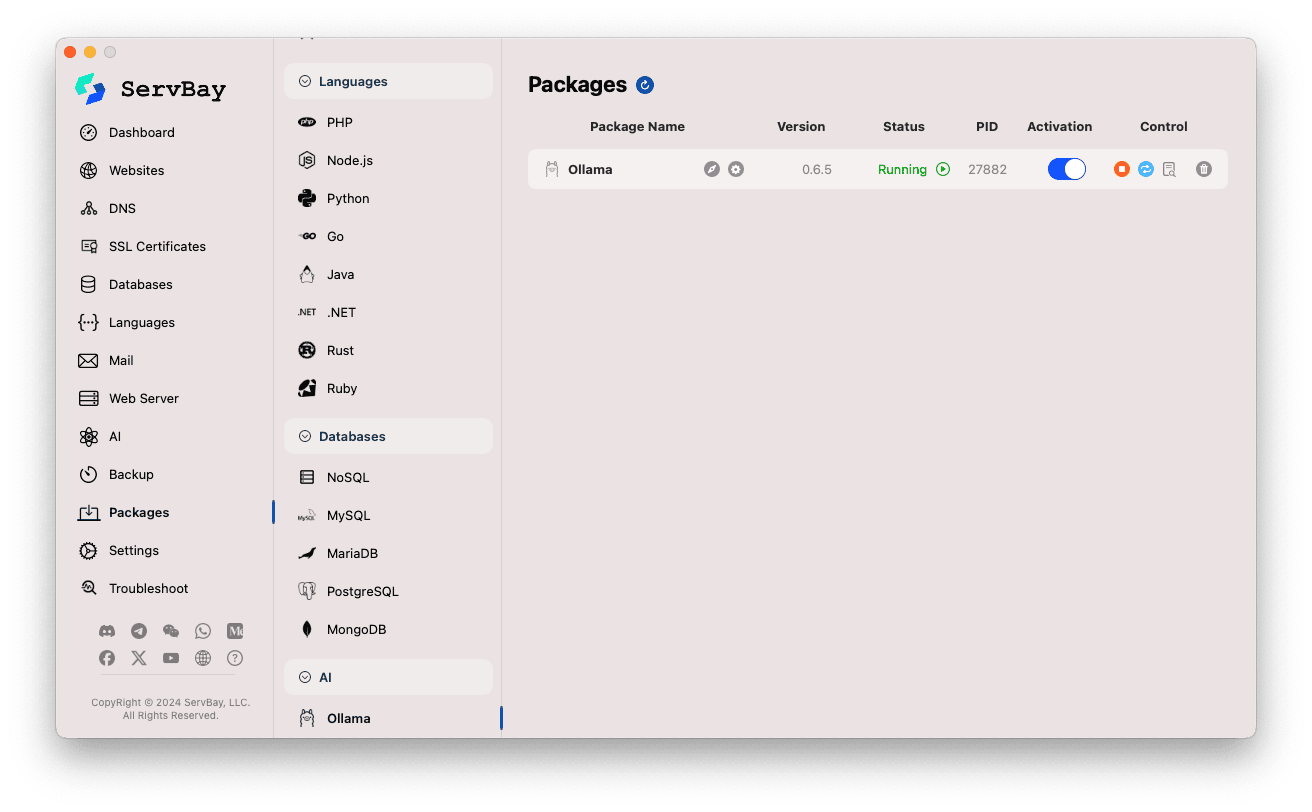
Je beheert het Ollama-pakket eenvoudig via de hoofdinterface van ServBay.
Ollama-pakket openen:
- Start de ServBay-applicatie.
- Klik aan de linkerzijde van de navigatiebalk op
Pakketten. - Zoek onder de uitgevouwen lijst naar de categorie
AIen klik daarop. - Kies vervolgens
Ollama.
Ollama-service beheren:
- Aan de rechterzijde zie je statusinformatie van het Ollama-pakket, inclusief versienummer (zoals
0.6.5), huidige status (RunningofStopped), en proces-ID (PID). - Gebruik de controleknoppen aan de rechterkant:
- Start/Stop: De oranje ronde knop start of stopt de Ollama-service.
- Herstarten: De blauwe ververs-knop herstart de Ollama-service.
- Configuratie: De gele tandwielknop brengt je naar de configuratiepagina van Ollama.
- Verwijderen: De rode prullenbak verwijdert het Ollama-pakket (wees voorzichtig!).
- Meer Info: De grijze infoknop biedt extra informatie of toegang tot logbestanden.
- Aan de rechterzijde zie je statusinformatie van het Ollama-pakket, inclusief versienummer (zoals
Ollama configureren
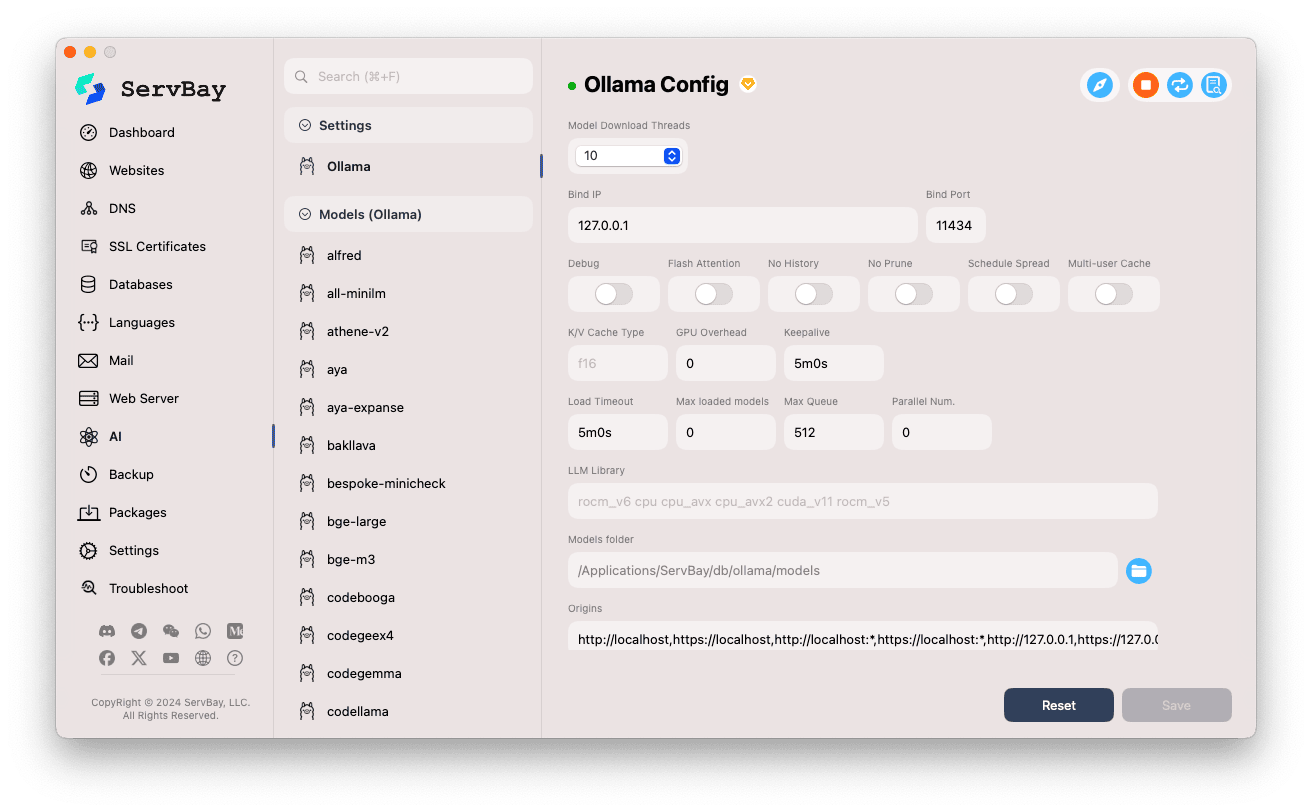
ServBay biedt een grafische interface om de bedrijfsparameters van Ollama aan te passen aan je eigen behoeften.
Configuratie openen:
- Start de ServBay-applicatie.
- Klik links in het navigatiemenu op
AI. - Open de categorie
Instellingenin de uitklaplijst. - Klik op
Ollama.
Instellingen aanpassen:
- Model Download Threads: Stel het aantal gelijktijdige downloads in voor hogere snelheid.
- Bind IP: IP-adres waarop de Ollama-service luistert. Standaard
127.0.0.1, enkel lokaal toegankelijk. - Bind Port: Poort waarop Ollama draait, standaard
11434. - Boolean switches:
Debug: Activeer debug-modus.Flash Attention: Mogelijke optimalisatie in te schakelen (vereist hardware-ondersteuning).No History: Schakelt de logging van de sessiegeschiedenis uit.No Prune: Voorkomt automatisch opruimen van ongebruikte modellen.Schedule Spread: Geavanceerde scheduler-optie.Multi-user Cache: Instellingen m.b.t. cache voor meerdere gebruikers.
- K/V Cache Type: Key/Value-cachetype, voor prestatie en geheugenbeheer.
- GPU gerelateerd:
GPU Overhead: GPU-overheadinstellingen.Keepalive: Tijd dat de GPU actief blijft.
- Model laden en wachtrij:
Load Timeout: Time-out voor modelladen.Max loaded models: Maximum aantal modellen gelijktijdig in het geheugen.Max Queue: Maximale lengte van de verzoekswachtrij.Parallel Num.: Aantal parallelle aanvragen die verwerkt worden.
- LLM Library: Pad naar de te gebruiken LLM-bibliotheek.
- Models folder: Lokale map waar Ollama modellen downloadt en opslaat (standaard
/Applications/ServBay/db/ollama/models). Klik op het mapicoon om deze locatie in Finder te openen. - origins: Toegestane bronnen voor toegang tot de Ollama API (CORS-instellingen). Standaard zijn lokale adressen opgenomen (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1, enz.). Voeg hier extra domeinen toe als je vanuit andere webapplicaties Ollama wilt bereiken.
Instellingen opslaan: Sla je aanpassingen op met de knop
Saverechtsonder zodat wijzigingen actief worden.
Ollama-modellen beheren
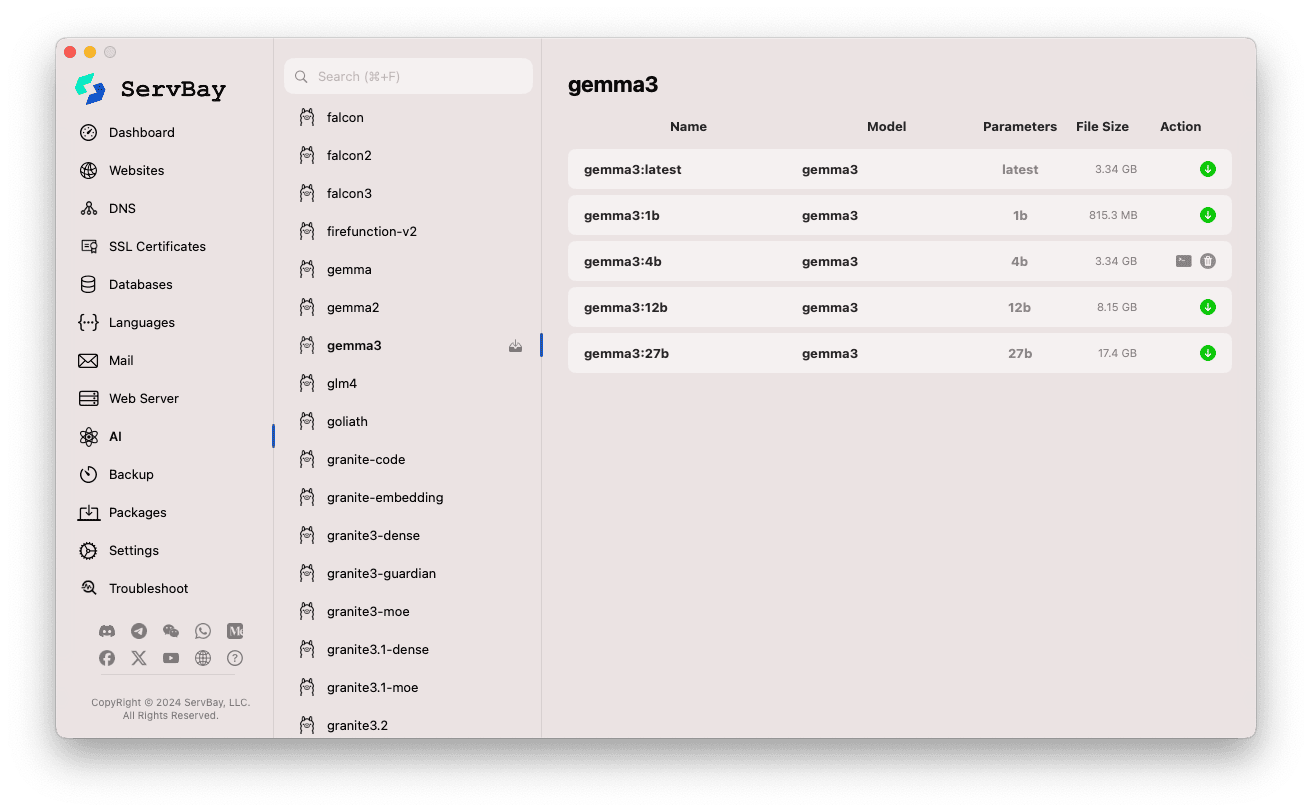
ServBay maakt het ontdekken, downloaden en beheren van Ollama-modellen eenvoudig.
Modellenbeheer openen:
- Start de ServBay-app.
- Klik links op
AIin de navigatiebalk. - Kies
Models (Ollama)onder de uitklaplijst.
Modellen bekijken en downloaden:
- Links zie je lijsten van modelbibliotheken die Ollama ondersteunt (zoals
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistraletc.). Klik bijvoorbeeld op een bibliotheeknaam zoalsgemma3. - Rechts verschijnen verschillende varianten/versies per model, meestal onderscheiden op parameters (bijv.
latest,1b,4b,12b,27b). - Elke regel toont modelnaam, basismodel, aantal parameters en bestandsgrootte.
- Klik op de groene downloadpijl rechts om een model te downloaden. De voortgang verschijnt in de interface. Verhoog het aantal download threads bij
Instellingenom sneller te downloaden. - Voor reeds gedownloade modellen is de downloadknop grijs of inactief.
- Links zie je lijsten van modelbibliotheken die Ollama ondersteunt (zoals
Gedownloade modellen beheren:
- Gedownloade modellen zijn duidelijk gemarkeerd (bijv. grijze downloadknop of een verwijderknop).
- Klik op de prullenbak om lokale modelbestanden te verwijderen en schijfruimte vrij te maken.
Gebruikmaken van de Ollama API
Na het opstarten luistert Ollama op het ingestelde Bind IP en Bind Port (standaard 127.0.0.1:11434) voor REST API-aanvragen. Je kunt elk HTTP-clienthulpmiddel zoals curl, Postman of programmeerbibliotheken gebruiken om met gedownloade modellen te communiceren.
TIP
ServBay biedt een handige domeinnaam https://ollama.servbay.host voor SSL/TLS-encrypted, HTTPS-toegang.
Je kunt dus eenvoudig de API benaderen via https://ollama.servbay.host in plaats van te werken met IP:poort.
Voorbeeld: Interactie met het gedownloade model gemma3:latest via curl
Controleer of je via ServBay het model gemma3:latest hebt gedownload en Ollama draait.
bash
# Gebruik de door ServBay aangeboden https-URL
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# Of traditioneel via IP en poort
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'Uitleg bij het commando:
http://127.0.0.1:11434/api/generate: Het API-eindpunt voor het genereren van tekst via Ollama.-d '{...}': Verstuurde POST body met JSON-gegevens."model": "gemma3:latest": Specificeer de te gebruiken (en reeds gedownloade) modelnaam."prompt": "Why is the sky blue?": De vraag of prompt aan het model."stream": false: Metfalsewacht je op een volledig gegenereerd antwoord; bijtrueontvang je een stream van tokens.
Verwachte uitvoer:
Je terminal toont een JSON-reactie met het veld response waarin het antwoord van het model op "Why is the sky blue?" staat.
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... overige metadata
}Let op CORS: Als je vanuit JavaScript in de browser Ollama's API aanspreekt, moet het oorsprongsadres van jouw webapp (bijv. http://myapp.servbay.demo) aan de origins-lijst zijn toegevoegd in de Ollama-configuratie. Anders blokkeert de browser het verzoek wegens CORS-beperkingen.
Toepassingsmogelijkheden
Ollama lokaal in ServBay draaien biedt veel praktische voordelen:
- Lokale AI-ontwikkeling: Geen externe API's of cloud-diensten vereist, direct lokaal bouwen en testen van LLM-apps.
- Snelle prototyping: Snel wisselen tussen modellen en nieuwe ideeën valideren.
- Offline gebruik: Gebruik LLM's zelfs zonder internetverbinding.
- Dataprivacy: Alle gegevens en interacties blijven op je eigen computer, geen zorgen over datatransfer naar derden.
- Kostenefficiënt: Geen pay-per-use kosten van cloud-AI-diensten.
Aandachtspunten
- Schijfruimte: Grote taalmodellen zijn fors (meerdere GB’s tot tientallen GB’s). Zorg voor voldoende vrije ruimte. Modellen worden standaard opgeslagen onder
/Applications/ServBay/db/ollama/models. - Systeembronnen: LLM’s zijn veeleisend voor CPU en geheugen (RAM); als je Mac een compatibele GPU heeft, kan Ollama deze voor versnelling gebruiken — wat extra GPU-bronnen vereist. Controleer of je Mac voldoende krachtig is voor jouw modelkeuze.
- Downloadtijd: Het downloaden van modellen kost tijd, afhankelijk van netwerkverbinding en modelgrootte.
- Firewall: Als je
Bind IPop0.0.0.0hebt gezet voor LAN-toegang, controleer dan of de macOS-firewall inkomende verbindingen op de Ollama-poort (11434) toestaat.
Samenvatting
Dankzij de integratie van Ollama vereenvoudigt ServBay het lokaal uitrollen en beheren van grote taalmodellen op macOS aanzienlijk. Met een intuïtieve grafische interface start je eenvoudig services, pas je configuraties aan, download je modellen en begin je direct aan de ontwikkeling en experimenten met AI-toepassingen. Dit versterkt de rol van ServBay als alles-in-één omgeving voor lokale softwareontwikkeling.
