
Using Ollama in ServBay
ServBay brings powerful local AI capabilities directly into your development environment, allowing you to easily run various open-source large language models (LLMs) on macOS via Ollama. This document will guide you through enabling, configuring, and managing Ollama and its models in ServBay, so you can get started right away.
Overview
Ollama is a popular tool that streamlines the process of downloading, setting up, and running large language models on your local machine. ServBay integrates Ollama as a standalone package, providing a graphical management interface that allows developers to:
- Start, stop, or restart the Ollama service with a single click.
- Configure Ollama parameters through an intuitive graphical interface.
- Browse, download, and manage supported LLM models.
- Develop, test, and experiment with AI applications locally—no reliance on cloud services required.
Prerequisites
- ServBay is installed and running on your macOS system.
Enabling and Managing Ollama Service
You can easily manage the Ollama package through ServBay's main interface.
Access the Ollama Package:
- Open the ServBay application.
- In the left sidebar, click on
Packages. - In the expanded list, locate and click the
AIcategory. - Select
Ollama.
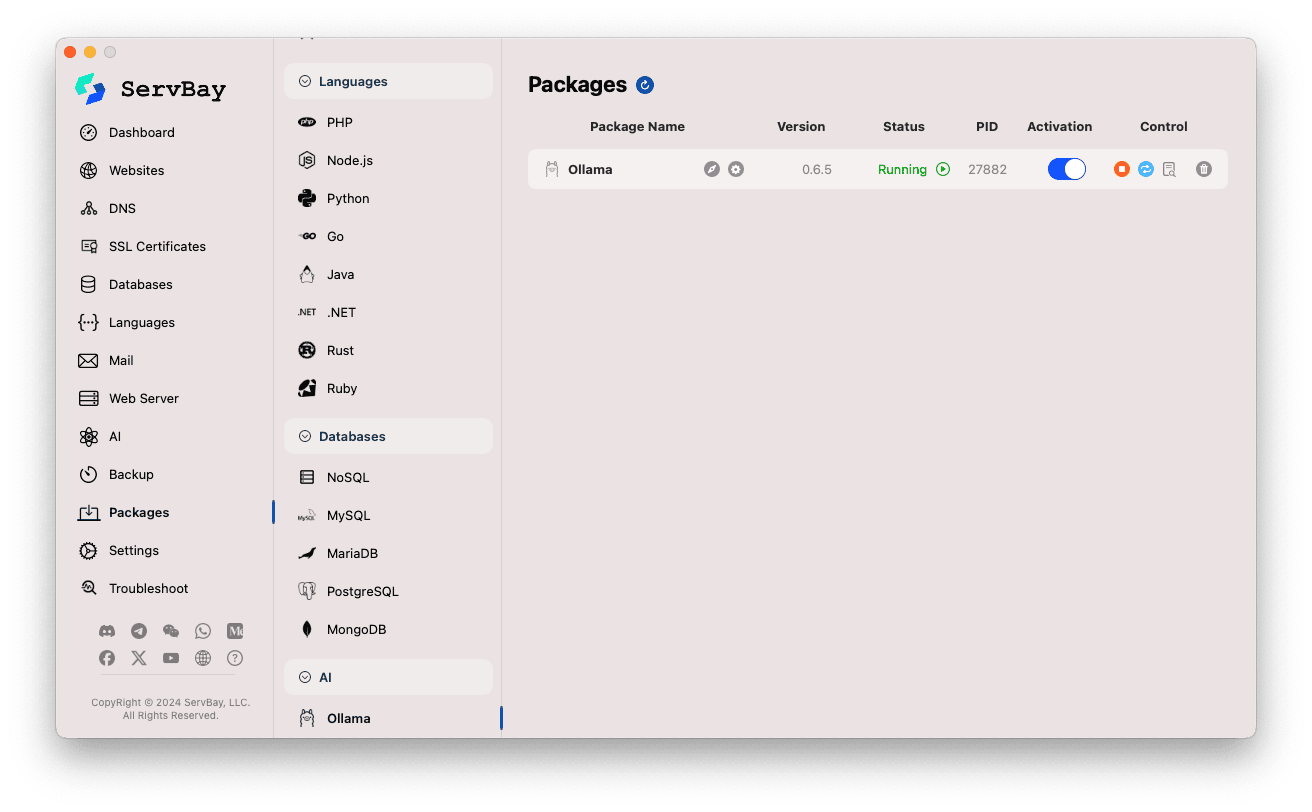
Manage the Ollama Service:
- On the right, you'll see status information for the Ollama package, including the version (e.g.,
0.6.5), current status (RunningorStopped), and process ID (PID). - Use the control buttons on the right:
- Start/Stop: Orange circle button to start or stop the Ollama service.
- Restart: Blue refresh button to restart the service.
- Configure: Yellow gear button to go to Ollama's configuration page.
- Delete: Red trash can button to uninstall the Ollama package (use with caution).
- More Info: Gray info button may provide additional details or access to logs.
- On the right, you'll see status information for the Ollama package, including the version (e.g.,
Configuring Ollama
ServBay provides a graphical interface for tailoring Ollama's settings to suit your needs.
Access the Configuration Panel:
- Open the ServBay application.
- In the left sidebar, click
AI. - In the expanded list, select the
Settingscategory. - Click
Ollama.
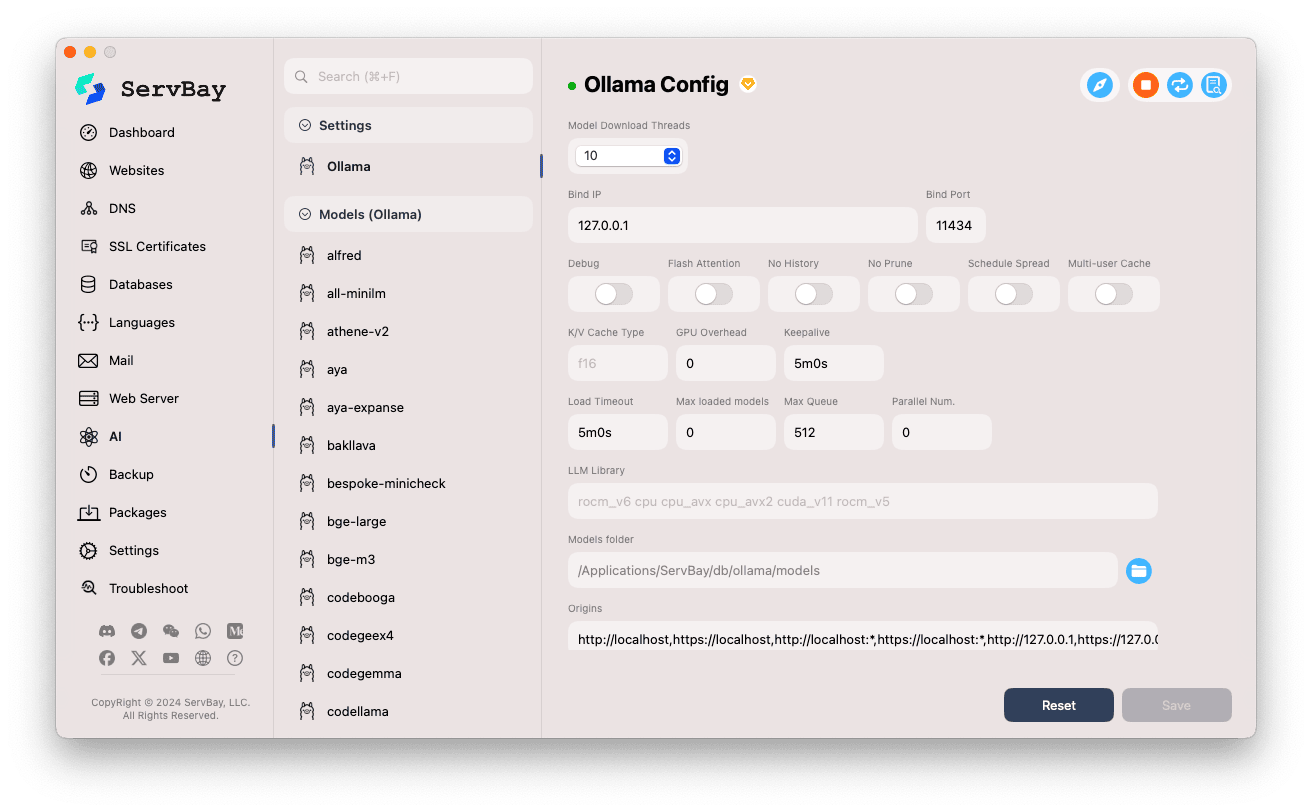
Adjust Configuration Options:
- Model Download Threads: Set the number of threads to use for concurrent model downloads. Increasing threads can speed up downloads.
- Bind IP: The IP address Ollama listens on. Default is
127.0.0.1, allowing only local access. - Bind Port: The port used by the Ollama service. Default is
11434. - Boolean Switches:
Debug: Enable debug mode.Flash Attention: Possibly enables Flash Attention optimization (dependent on hardware support).No History: Disable session history recording.No Prune: Prevent automatic removal of unused models.Schedule Spread: Related to scheduling policies.Multi-user Cache: Related to caching for multiple users.
- K/V Cache Type: Select key/value cache type, which impacts performance and memory usage.
- GPU Options:
GPU Overhead: GPU overhead configuration.Keepalive: Duration to keep GPU resources active.
- Model Loading and Queuing:
Load Timeout: Timeout for model loading.Max loaded models: Maximum number of models loaded into memory at once.Max Queue: Maximum length of the request queue.Parallel Num.: Number of parallel request handlers.
- LLM Library: Specify the underlying LLM library path to use.
- Models folder: Local directory for storing downloaded models. Default is
/Applications/ServBay/db/ollama/models. Click the folder icon to open this directory in Finder. - origins: Configure the sources allowed to access the Ollama API (CORS settings). By default, common local addresses are included (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1, etc.). To allow access from other web app domains, add their addresses here.
Save Configuration: After making changes, click the
Savebutton in the lower right corner to apply them.
Managing Ollama Models
ServBay streamlines the discovery, download, and management of Ollama models.
Open Model Management Interface:
- Open the ServBay application.
- In the left sidebar, click
AI. - In the expanded list, click
Models (Ollama).
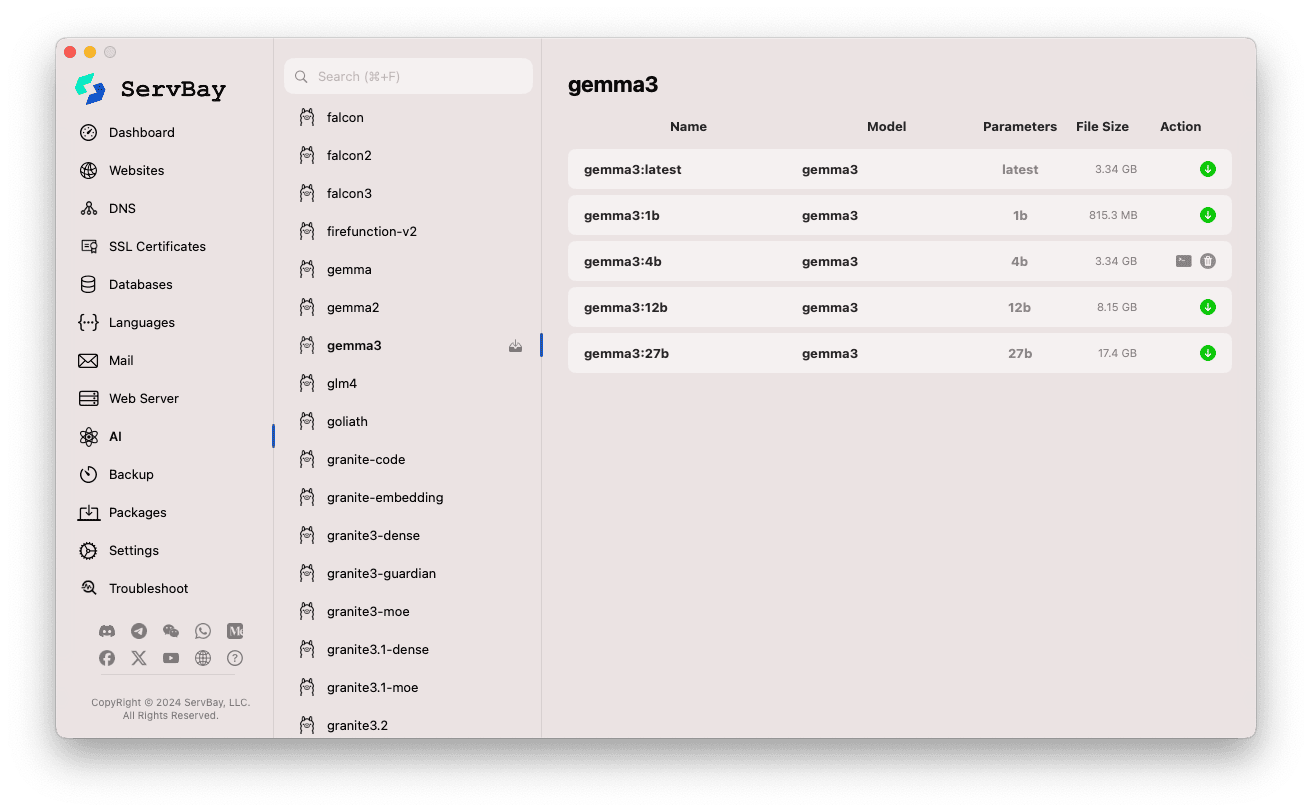
Browse and Download Models:
- On the left, you'll find a list of Ollama-supported model repositories (such as
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistral, etc.). Click a repository name (e.g.,gemma3). - On the right, you'll see its available variants or versions, typically distinguished by parameter size (like
latest,1b,4b,12b,27b). - Each entry displays model name, base model, parameter count, and file size.
- To download a model, click the green download arrow on the right. The progress will be displayed. You can speed up downloads by adjusting the "Download Threads" setting under
Settings. - For downloaded models, the download button turns gray or disabled.
- On the left, you'll find a list of Ollama-supported model repositories (such as
Manage Downloaded Models:
- Downloaded models are clearly marked in the list—for example, with a grayed-out download button or a delete icon.
- You can remove a local model and free disk space by clicking its delete (trash can) icon.
Using the Ollama API
Once started, Ollama provides a REST API on the configured Bind IP and Bind Port (default: 127.0.0.1:11434). You can interact with your downloaded models using any HTTP client (such as curl, Postman, or programming language libraries).
TIP
ServBay conveniently offers a domain with SSL/TLS encryption: https://ollama.servbay.host
You can access Ollama's API via https://ollama.servbay.host instead of using the raw IP:Port address.
Example: Interacting with the downloaded gemma3:latest model using curl
Make sure you've already downloaded the gemma3:latest model via ServBay and that Ollama is running.
bash
# Using the HTTPS endpoint provided by ServBay
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# Or using the classic IP:port method
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'Explanation:
http://127.0.0.1:11434/api/generate: Ollama's API endpoint for text generation.-d '{...}': Send a POST request with JSON payload:"model": "gemma3:latest": The model to use (must be downloaded)."prompt": "Why is the sky blue?": Your question or prompt for the model."stream": false: If set tofalse, waits for a complete response. Iftrue, the API streams generated tokens.
Expected Output:
You’ll see a JSON response in your terminal, with the response field containing the model’s answer to "Why is the sky blue?".
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... other metadata
}CORS Note: If you’re accessing the Ollama API from JavaScript running in the browser, make sure your web app’s origin (e.g., http://myapp.servbay.demo) is included in Ollama’s origins configuration list; otherwise, requests may be blocked by the browser’s CORS policy.
Use Cases
Running Ollama locally in ServBay brings many advantages:
- Local AI Development: Develop and test LLM-based applications entirely on your machine, with no dependence on external APIs or cloud services.
- Rapid Prototyping: Quickly try out various open-source models to validate ideas.
- Offline Use: Interact with LLMs even without an internet connection.
- Data Privacy: All data and interactions stay on your local machine—no risk of sensitive data being transferred to third parties.
- Cost-Effective: Avoid pay-as-you-go charges typical of cloud AI services.
Notes & Considerations
- Disk Space: LLM files are typically large (several GBs to tens of GBs). Make sure you have sufficient free disk space. Models are stored by default at
/Applications/ServBay/db/ollama/models. - System Resources: Running LLMs is CPU and RAM intensive. If your Mac has a compatible GPU, Ollama can use it for acceleration, which will also consume GPU resources. Ensure your Mac is adequately equipped for your chosen models.
- Download Time: Download duration depends on your internet speed and the model size.
- Firewall: If you change the
Bind IPto0.0.0.0to allow access from other devices, ensure your macOS firewall allows incoming connections to Ollama’s port (11434).
Summary
By integrating Ollama, ServBay greatly simplifies the deployment and management of local large language models on macOS. Its intuitive graphical interface enables developers to start services, adjust configurations, download models, and rapidly begin local AI development and experiments, further enhancing ServBay as an all-in-one local development environment.
