
ServBay에서 Ollama 사용하기
ServBay는 강력한 로컬 AI 기능을 개발 환경에 통합하여, macOS에서 Ollama를 통해 다양한 오픈소스 대형 언어 모델(LLM)을 쉽게 실행할 수 있도록 도와줍니다. 이 문서에서는 ServBay에서 Ollama와 모델을 활성화, 설정, 관리하는 방법과 시작하는 절차를 안내합니다.
개요
Ollama는 로컬 컴퓨터에서 대형 언어 모델을 다운로드, 설정, 실행하는 과정을 간소화해주는 인기 툴입니다. ServBay는 Ollama를 독립 패키지로 통합하여, 개발자가 그래픽 인터페이스를 통해 다음을 쉽게 수행할 수 있습니다.
- Ollama 서비스를 원클릭으로 시작, 중지, 재시작
- GUI로 Ollama의 각종 매개변수 설정
- 지원 LLM 모델을 탐색, 다운로드 및 관리
- 클라우드에 의존하지 않고 로컬에서 AI 개발, 테스트, 실험 진행
사전 준비사항
- macOS 시스템에 ServBay가 설치 및 실행 중이어야 합니다.
Ollama 서비스 활성화 및 관리
ServBay의 메인 인터페이스에서 Ollama 패키지를 쉽게 관리할 수 있습니다.
Ollama 패키지 접근:
- ServBay 앱을 실행합니다.
- 좌측 네비게이션 바에서
패키지(Packages)를 클릭합니다. - 펼쳐진 목록에서
AI카테고리를 찾아 클릭합니다. Ollama를 클릭합니다.
Ollama 서비스 관리:
- 우측 영역에서 Ollama 패키지의 상태 정보(버전 예:
0.6.5, 실행 상태:Running또는Stopped, 프로세스 ID(PID))를 확인할 수 있습니다. - 우측 제어 버튼 사용:
- 시작/중지: 주황색 원 버튼으로 Ollama 서비스를 시작 또는 중지할 수 있습니다.
- 재시작: 파란색 새로고침 버튼으로 Ollama 서비스를 재시작합니다.
- 설정: 노란색 기어 버튼으로 Ollama 설정 페이지로 이동합니다.
- 삭제: 빨간색 휴지통 버튼으로 Ollama 패키지를 제거합니다(신중히 사용).
- 추가 정보: 회색 정보 버튼은 추가 정보 또는 로그 접근을 제공합니다.
- 우측 영역에서 Ollama 패키지의 상태 정보(버전 예:
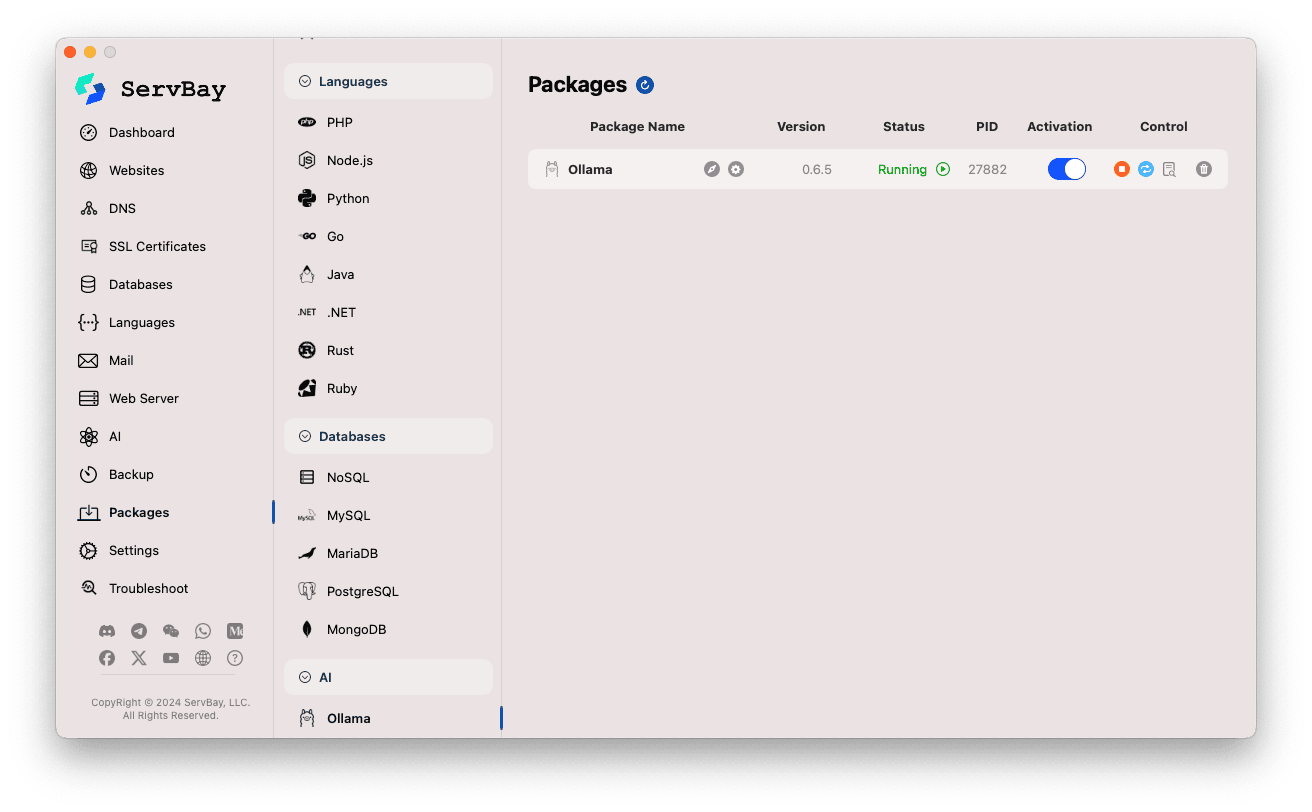
Ollama 설정
ServBay는 Ollama의 실행 파라미터를 조정할 수 있는 그래픽 인터페이스를 제공합니다.
설정 페이지 접근:
- ServBay 앱을 실행합니다.
- 좌측 네비게이션 바에서
AI를 클릭합니다. - 펼쳐진 목록에서
설정(Settings)카테고리를 클릭합니다. Ollama를 클릭합니다.
설정 항목 조정:
- Model Download Threads: 모델 동시 다운로드 스레드 수를 설정하여 다운로드 속도를 높일 수 있습니다.
- Bind IP: Ollama 서비스가 리슨하는 IP 주소(기본값
127.0.0.1로 오직 로컬 접속만 허용). - Bind Port: Ollama 서비스가 리슨하는 포트(기본값
11434). - 불리언 스위치 옵션:
Debug: 디버그 모드 활성화Flash Attention: Flash Attention 최적화(하드웨어 지원 필요)No History: 세션 기록 비활성화No Prune: 미사용 모델 자동 정리 방지Schedule Spread: 스케줄링 관련 옵션Multi-user Cache: 다중 사용자 캐싱 관련
- K/V Cache Type: Key/Value 캐시 타입(성능 및 메모리 사용량에 영향)
- GPU 관련:
GPU Overhead: GPU 부하 설정Keepalive: GPU Keepalive 시간
- 모델 로딩 및 큐:
Load Timeout: 모델 로딩 제한 시간Max loaded models: 메모리에 동시에 적재하는 모델의 최대 수Max Queue: 최대 요청 큐 길이Parallel Num.: 동시 처리 요청 수
- LLM Library: 사용할 LLM 라이브러리 경로 지정
- Models folder: Ollama가 모델을 다운로드 및 저장하는 로컬 디렉터리(기본값
/Applications/ServBay/db/ollama/models). 폴더 아이콘을 눌러 Finder에서 바로 열 수 있습니다. - origins: Ollama API에 접근할 수 있는 출처(CORS 설정) 지정. 기본적으로
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1등 로컬 주소가 포함되어 있습니다. 다른 도메인에서 접근하려면 여기에 해당 주소를 추가해야 합니다.
설정 저장: 변경 사항을 적용하려면 우측 하단의
Save버튼을 클릭하세요.
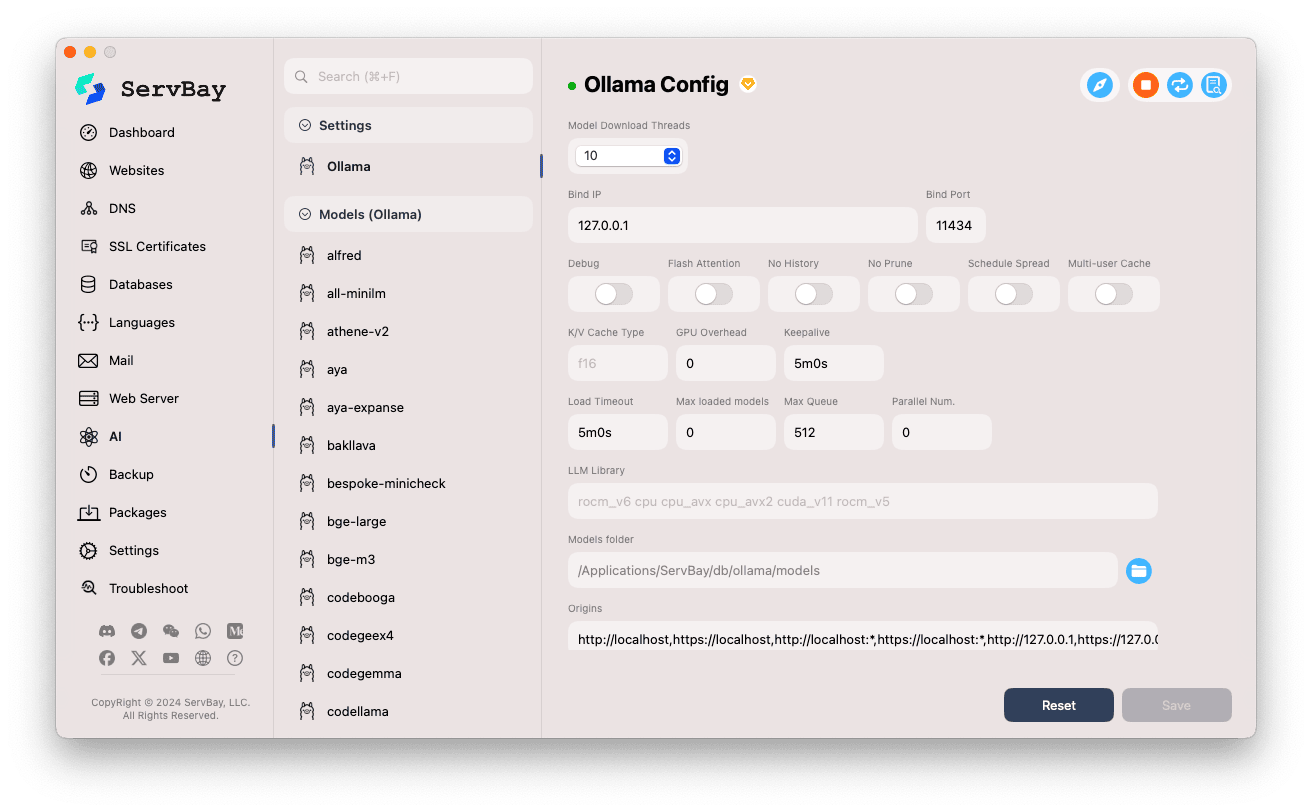
Ollama 모델 관리
ServBay는 Ollama 모델 검색, 다운로드, 관리를 아주 쉽게 만들어줍니다.
모델 관리 페이지 접근:
- ServBay 앱을 실행합니다.
- 좌측 네비게이션 바에서
AI를 클릭합니다. - 펼쳐진 목록에서
Models (Ollama)를 클릭합니다.
모델 탐색 및 다운로드:
- 왼쪽에는 Ollama가 지원하는 다양한 모델 라이브러리(예:
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistral등)가 표시됩니다. 원하는 모델 라이브러리(예:gemma3)를 클릭합니다. - 우측에는 해당 라이브러리의 다양한 변형 또는 버전이(일반적으로 파라미터 크기별로
latest,1b,4b,12b,27b등) 나열됩니다. - 각 행에는 모델명, 기반 모델, 파라미터 크기, 파일 크기가 표시됩니다.
- 맨 오른쪽의 녹색 다운로드 화살표를 클릭하면 해당 모델 다운로드가 시작됩니다. 다운로드 진행 상황은 화면에서 실시간 확인 가능.
설정에서다운로드 스레드 수를 조정해 더 빠른 다운로드가 가능합니다. - 이미 다운로드된 모델은 다운로드 버튼이 비활성화(회색)로 변경됩니다.
- 왼쪽에는 Ollama가 지원하는 다양한 모델 라이브러리(예:
다운로드한 모델 관리:
- 다운로드된 모델은 목록에서 별도 표시(다운로드 버튼이 회색이거나 삭제 버튼이 표시됨)됩니다.
- 삭제(휴지통 아이콘) 버튼을 눌러 로컬에 저장된 해당 모델 파일을 제거하여 디스크 공간을 확보할 수 있습니다.
Ollama API 사용하기
Ollama를 실행하면 설정한 Bind IP와 Bind Port(기본값 127.0.0.1:11434)에서 REST API 서비스를 제공합니다. 모든 HTTP 클라이언트(예: curl, Postman 또는 프로그래밍 언어 라이브러리)로 다운로드한 모델과 상호작용 할 수 있습니다.
TIP
ServBay는 사용자 편의를 위해 SSL/TLS 암호화로 HTTPS 접속 지원이 되는 도메인 https://ollama.servbay.host를 제공합니다.
사용자는 Ollama API 접속 시 IP:포트 대신 https://ollama.servbay.host 도메인으로 접근할 수 있습니다.
예시: curl로 다운로드한 gemma3:latest 모델과 상호작용
먼저 ServBay로 gemma3:latest 모델을 다운로드하고 Ollama 서비스가 실행 중임을 확인하세요.
bash
# ServBay에서 제공하는 https 사용
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# 또는 전통적인 IP:포트 방식
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'명령 설명:
http://127.0.0.1:11434/api/generate: Ollama 텍스트 생성 API 엔드포인트-d '{...}': POST 요청 바디로 JSON 데이터 전송"model": "gemma3:latest": 사용 모델명 지정(반드시 다운로드되어 있어야 함)"prompt": "Why is the sky blue?": 모델에 질문 또는 프롬프트 입력"stream": false:false시 응답 전체를 한 번에 반환,true면 토큰별로 스트리밍 반환
예상 응답:
터미널에서 아래와 같이 response 필드에 "Why is the sky blue?"에 대한 모델의 답변이 포함된 JSON 응답을 볼 수 있습니다.
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... 기타 메타데이터
}CORS 주의: 브라우저에서 자바스크립트 코드로 Ollama API에 접근하려면 웹앱의 소스 주소(예: http://myapp.servbay.demo)가 Ollama 설정의 origins에 추가되어 있어야 하며, 그렇지 않으면 CORS 정책에 의해 브라우저가 요청을 차단할 수 있습니다.
응용 사례
ServBay에서 Ollama를 로컬로 실행하면 다음과 같은 이점이 있습니다.
- 로컬 AI 개발: 외부 API나 클라우드가 필요 없이 LLM 기반 애플리케이션을 로컬에서 개발 및 테스트 가능
- 빠른 프로토타입 설계: 다양한 오픈소스 모델로 아이디어를 빠르게 검증
- 오프라인 사용: 네트워크 연결 없이도 LLM과 상호작용
- 데이터 프라이버시: 모든 데이터와 상호작용이 로컬 기기에 한정되어 외부 전송 걱정 없음
- 비용 절감: 종량제 클라우드 AI 서비스 비용을 절약
참고 사항
- 디스크 공간: 대형 언어 모델은 보통 수 GB~수십 GB이므로 충분한 디스크 공간 확보가 필요합니다. 모델은 기본적으로
/Applications/ServBay/db/ollama/models경로에 저장됩니다. - 시스템 자원: LLM 실행 시 CPU, 메모리(RAM) 사용량이 많으며, 호환 GPU가 있다면 Ollama가 이를 활용해 가속할 수 있습니다. Mac 사양이 실행하려는 모델에 적합한지 확인하세요.
- 다운로드 시간: 모델 크기와 네트워크 속도에 따라 다운로드 시간이 걸릴 수 있습니다.
- 방화벽:
Bind IP를0.0.0.0으로 변경해 네트워크 내 다른 기기에서 접근하도록 할 경우, macOS 방화벽에서 Ollama가 사용하는 포트(11434)의 인바운드 연결 허용이 필요합니다.
요약
ServBay는 Ollama 통합을 통해 macOS에서 로컬 대형 언어 모델 배포 및 관리를 매우 간단하게 만들어줍니다. 직관적인 GUI 덕분에 서비스 실행, 설정 조정, 모델 다운로드, 로컬 AI 개발 및 실험이 빠르게 가능하며, ServBay가 원스톱 로컬 개발 환경으로서의 가치를 한층 더 높여줍니다.
