
ServBayでOllamaを活用する
ServBayは強力なローカルAI機能を開発環境に統合し、Ollamaを通じてmacOS上でさまざまなオープンソースの大規模言語モデル(LLM)を簡単に実行できます。本ドキュメントでは、ServBayでOllamaとそのモデルを有効化・設定・管理し、すぐに使い始める方法をご案内します。
概要
Ollamaは、ローカルPCでの大規模言語モデルのダウンロード・セットアップ・実行を簡素化する人気ツールです。ServBayはOllamaを独立したパッケージとして統合しており、開発者向けに以下を提供します:
- ワンクリックでOllamaサービスの起動・停止・再起動
- GUIでOllamaの各種パラメータを設定
- 対応LLMモデルの閲覧・ダウンロード・管理
- クラウドサービスを必要とせず、ローカルでAIアプリの開発・テスト・検証が可能
前提条件
- お使いのmacOSシステムにServBayがインストールされ、起動していること
Ollamaサービスの有効化と管理
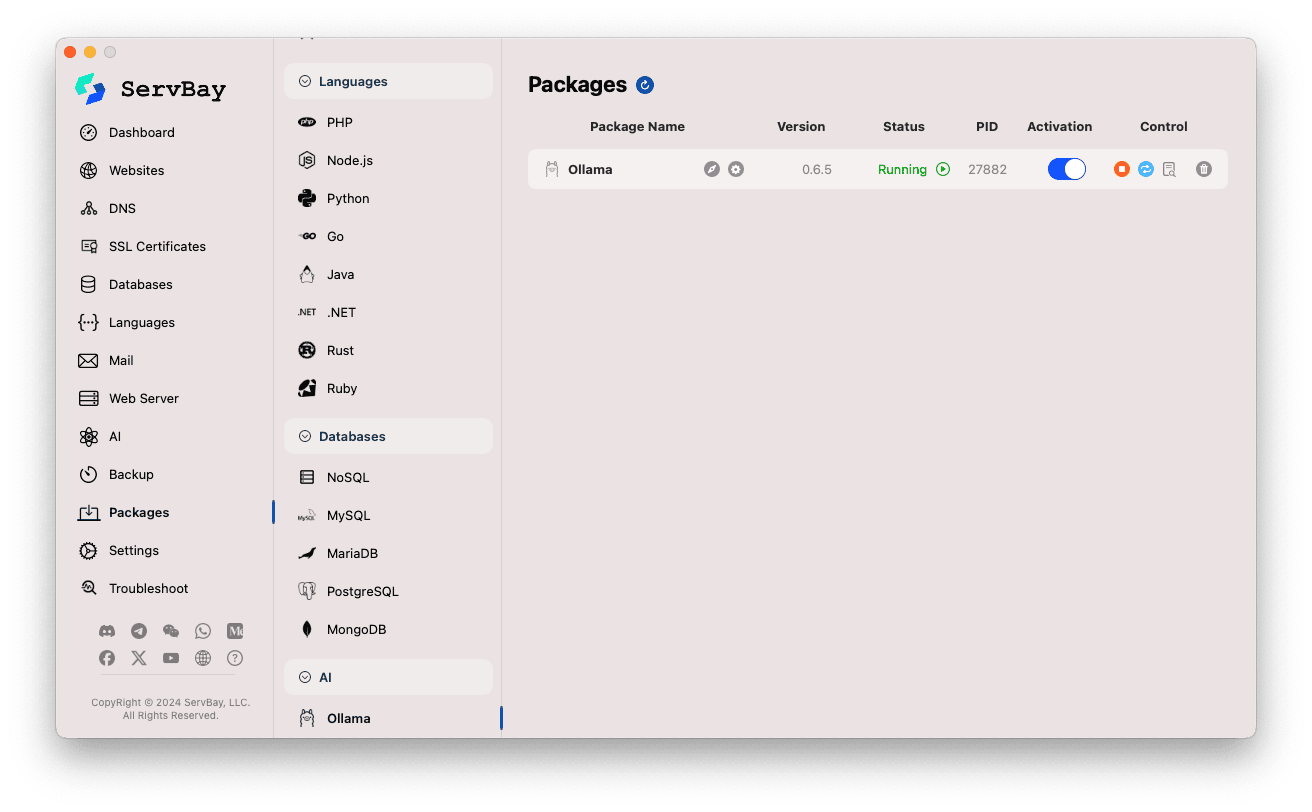
ServBayのメイン画面からOllamaパッケージを簡単に管理できます。
Ollamaパッケージへアクセス:
- ServBayアプリを開きます。
- 左側のナビゲーションバーで「ソフトウェアパッケージ (Packages)」をクリック。
- 展開メニューから「AI」カテゴリを選択。
- 「Ollama」をクリック。
Ollamaサービスの管理:
- 右側エリアにOllamaパッケージのステータス(バージョン例:
0.6.5、稼働状態RunningまたはStopped、プロセスID(PID)など)が表示されます。 - サイドのコントロールボタンを活用してください:
- 起動・停止: オレンジ色の丸いボタンでOllamaサービスの開始/停止が可能です。
- 再起動: 青のリフレッシュボタンでサービスの再起動。
- 設定: 黄色いギアボタンでOllama設定画面に移動。
- アンインストール: 赤いゴミ箱ボタンでOllamaパッケージの削除(操作は注意してください)。
- 詳細情報: グレーの情報ボタンから追加情報やログの表示が可能な場合もあります。
- 右側エリアにOllamaパッケージのステータス(バージョン例:
Ollamaの設定
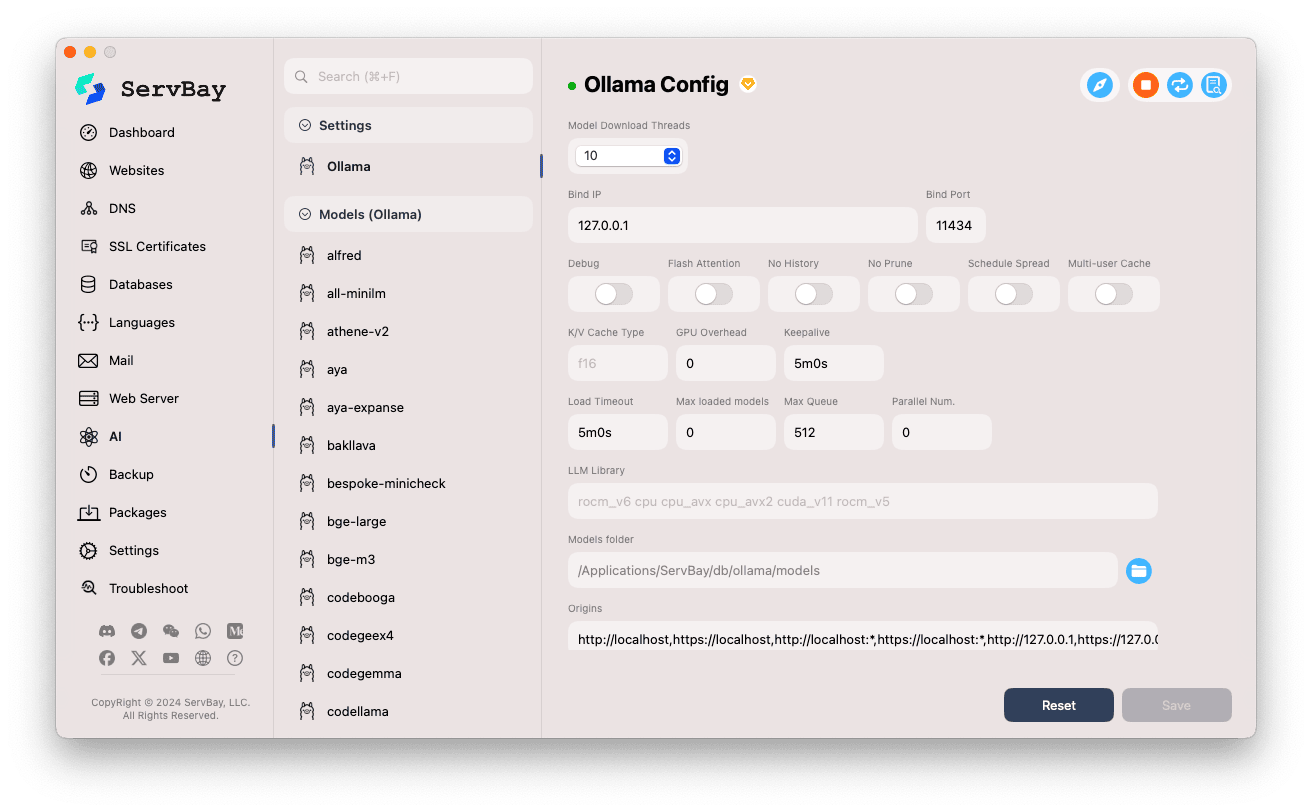
ServBayのGUIで、Ollamaの詳細な動作パラメータをニーズに合わせて調整できます。
設定画面にアクセス:
- ServBayアプリを開きます。
- 左のナビゲーションバーから「AI」をクリック。
- 展開された一覧で「設定(Settings)」カテゴリを探してクリック。
- 「Ollama」を選択。
各種設定項目の調整:
- Model Download Threads: モデルの同時ダウンロードスレッド数(ダウンロード速度を上げる場合に増やします)
- Bind IP: Ollamaサービスが待ち受けるIPアドレス。デフォルトは
127.0.0.1でローカルアクセスのみ有効。 - Bind Port: サービスの待ち受けポート。デフォルトは
11434。 - ブール(ON/OFF)オプション:
Debug: デバッグモードを有効化Flash Attention: Flash Attention最適化機能(ハードウェア対応が必要な場合あり)No History: セッション履歴を記録しないNo Prune: 未使用モデルの自動クリーニングを無効化Schedule Spread: スケジュール戦略に関連Multi-user Cache: 複数ユーザー利用時のキャッシュに関連
- K/V Cache Type: キー・バリュー型キャッシュ方式。利用メモリや処理パフォーマンスに影響。
- GPU関連:
GPU Overhead: GPUのオーバーヘッド設定Keepalive: GPUの待機維持時間
- モデルロード & キュー:
Load Timeout: モデルロードのタイムアウト時間Max loaded models: 同時ロード可能な最大モデル数Max Queue: リクエスト待機キューの最大長Parallel Num.: 並列リクエスト処理数
- LLM Library: 利用するLLM基盤ライブラリのパスを指定
- Models folder: Ollamaがモデルをダウンロード・保存するローカルフォルダ。標準は
/Applications/ServBay/db/ollama/models。フォルダアイコンからFinderで直接開けます。 - origins: Ollama APIへアクセスを許可するリファラー(CORSクロスオリジン設定)。デフォルトでよく使われるローカルアドレス(
http://localhost、https://localhost、http://127.0.0.1、https://127.0.0.1など)が含まれます。他ドメインのウェブアプリからアクセスしたい場合はここに対象アドレスを追加してください。
設定の保存: 項目を編集したら、画面右下にある「Save」ボタンをクリックし反映させます。
Ollamaモデルの管理
ServBayならOllamaモデルの検索・ダウンロード・管理が直感的に行えます。
モデル管理画面へアクセス:
- ServBayアプリを開きます。
- 左側ナビゲーションで「AI」をクリック。
- 展開リストから「Models (Ollama)」を選択。
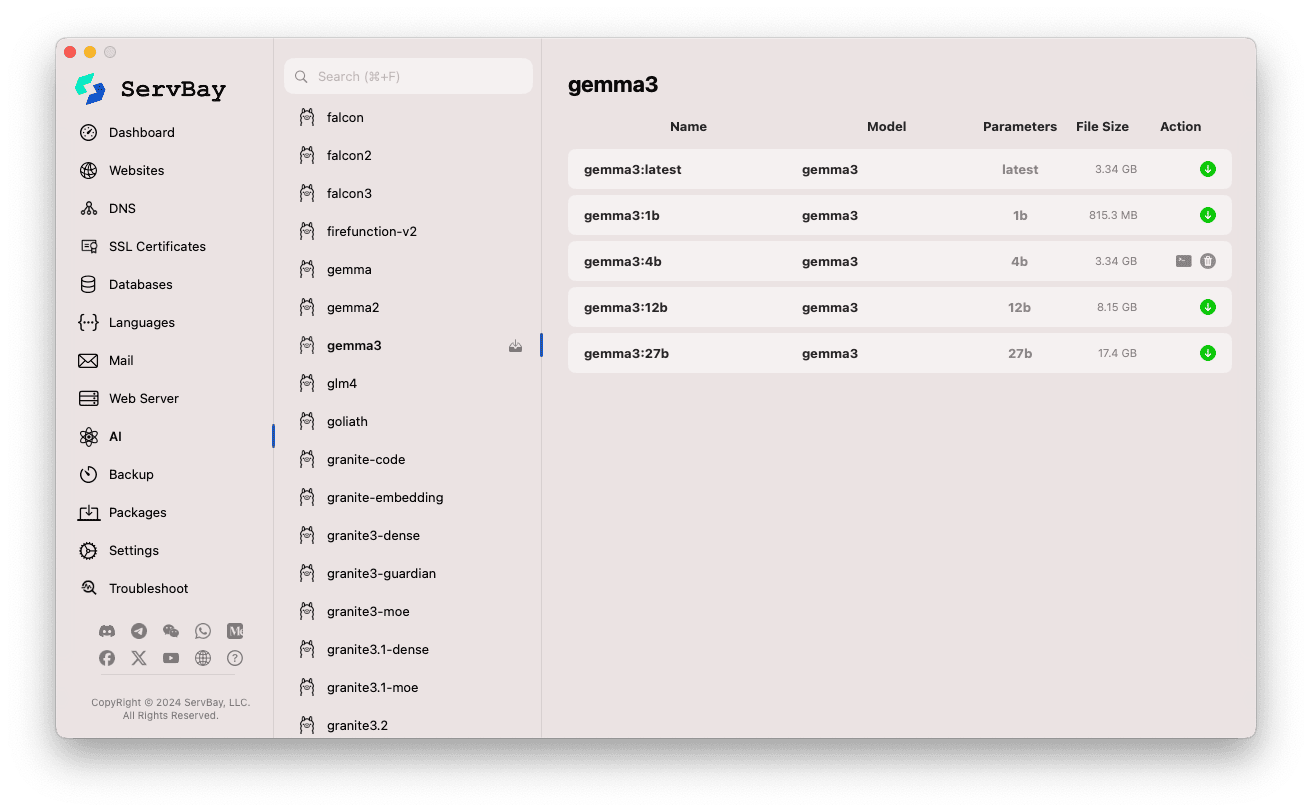
モデルの閲覧とダウンロード:
- 左側にはOllamaで利用できる各種モデルライブラリ(例:
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistralなど)が表示されます。モデル名(例:gemma3)をクリックしてください。 - 右エリアにはライブラリ内の各バージョンやバリエーションがリストアップされます(
latest,1b,4b,12b,27bなどパラメータ規模ごと)。 - 各行にはモデル名・ベースモデル・パラメータ量・ファイルサイズが掲載。
- 一番右の緑色ダウンロード矢印ボタンをクリックするとそのモデルのダウンロードを開始できます。進行状況は画面に表示。
Settingsでダウンロードスレッド数を調整することで速度アップも可能です。 - すでにダウンロード済みのモデルはボタンがグレーまたは非アクティブになっています。
- 左側にはOllamaで利用できる各種モデルライブラリ(例:
ダウンロード済みモデルの管理:
- 取得済みモデルは明確に表示され(たとえばダウンロードボタンがグレー、または削除ボタンが出現します)
- ゴミ箱マーク等の削除ボタンから、ローカルのモデルファイルを削除しストレージを空けることができます。
Ollama APIの活用
Ollamaが起動すると、設定した Bind IP と Bind Port (既定値 127.0.0.1:11434)でREST APIサービスを提供します。任意のHTTPクライアント(curl、Postman、プログラミング言語のHTTP/RESTライブラリ等)でダウンロード済みモデルを操作できます。
TIP
ServBayはSSL/TLS暗号化に対応したhttps://ollama.servbay.hostという専用HTTPSドメインを用意しています。
APIへのアクセスはIP:ポート形式だけでなくhttps://ollama.servbay.hostドメインでも利用可能です。
例:ダウンロード済みgemma3:latestモデルをcurlで操作する
予めServBay経由でgemma3:latestモデルを取得し、Ollamaサービスが稼働していることをご確認ください。
bash
# ServBay提供のhttpsを利用
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# または従来のIP:ポート方式
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'コマンドの解説:
http://127.0.0.1:11434/api/generate: Ollamaのテキスト生成APIエンドポイント-d '{...}': POSTリクエストボディにJSONを指定"model": "gemma3:latest": 利用するモデル名(ダウンロード済み必須)"prompt": "Why is the sky blue?": モデルに質問やプロンプトを投げる"stream": false:falseは一括応答、trueでストリーミング応答
想定される出力:
ターミナルには、responseフィールドに "Why is the sky blue?" へのモデル回答が入ったJSONが表示されます。
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... その他のメタデータ
}CORSに関する注意:
ブラウザのJavaScriptコードからOllama APIにアクセスする場合は、ご自身のWebアプリのオリジン(例: http://myapp.servbay.demo)がOllamaのoriginsリストに追加されていることをご確認ください。未登録の場合、CORSポリシーによりブラウザでアクセスがブロックされます。
ユースケース
ServBayでローカルOllamaを実行することで、以下の利点を享受できます:
- ローカルAI開発: 外部APIやクラウド不要で、ローカル完結型LLMアプリ開発・テストが可能
- 迅速なプロトタイピング: 多種多様なOSSモデルをすばやく試してアイディア検証
- オフライン利用: ネットワーク接続なしでもLLMと対話
- データプライバシー: すべてのデータとやり取りがローカルPC内にとどまるため、第三者流出の心配なし
- コスト効果: 従量課金型クラウドAIサービス利用コスト不要
注意事項
- ディスク容量: 大規模言語モデルは1ファイル数GB~数十GBになる場合があります。十分な空きディスクをご用意ください。デフォルト保存先は
/Applications/ServBay/db/ollama/modelsです。 - システムリソース: LLM実行にはCPU、メモリ(RAM)への高負荷がかかります。M1/M2などGPU搭載Macであれば、OllamaがGPUによる高速化を活用できる場合があります。ご利用モデルの必要要件にご注意ください。
- ダウンロード時間: モデル取得にはネットワーク速度とサイズに応じて時間がかかります。
- ファイアウォール:
Bind IPを0.0.0.0に設定してLAN内の他端末からもOllamaへアクセス可能にした場合は、macOSのファイアウォールでOllamaのポート(11434)への外部接続許可を構成してください。
まとめ
ServBayはOllama統合によって、macOS環境でのローカル大規模言語モデルの配備や管理を飛躍的に簡単化しました。直感的なGUIを通じて、サービスの起動・設定・モデル取得もスムーズに行え、ローカルAIアプリ開発・実験のスタートをサポートします。これにより、ServBayはオールインワンのローカル開発プラットフォームとしての価値をさらに高めています。
