
Menggunakan Ollama di ServBay
ServBay mengintegrasikan kapabilitas AI lokal yang kuat ke dalam lingkungan pengembangan Anda, memungkinkan Anda dengan mudah menjalankan berbagai model bahasa besar (LLM) open-source melalui Ollama di macOS. Dokumen ini akan memandu Anda dalam mengaktifkan, mengonfigurasi, mengelola Ollama dan model-modelnya, serta mulai menggunakannya di ServBay.
Gambaran Umum
Ollama adalah alat populer yang menyederhanakan proses mengunduh, menyiapkan, dan menjalankan model bahasa besar di komputer lokal Anda. ServBay mengintegrasikan Ollama sebagai paket mandiri dengan antarmuka manajemen grafis, sehingga pengembang dapat dengan mudah:
- Memulai, menghentikan, atau me-restart layanan Ollama dengan sekali klik.
- Mengonfigurasi berbagai parameter Ollama melalui antarmuka grafis.
- Menelusuri, mengunduh, dan mengelola model LLM yang didukung.
- Mengembangkan, menguji, dan bereksperimen dengan aplikasi AI secara lokal, tanpa ketergantungan pada layanan cloud.
Prasyarat
- ServBay telah terinstal dan berjalan di sistem macOS Anda.
Mengaktifkan dan Mengelola Layanan Ollama
Anda dapat dengan mudah mengelola paket Ollama melalui antarmuka utama ServBay.
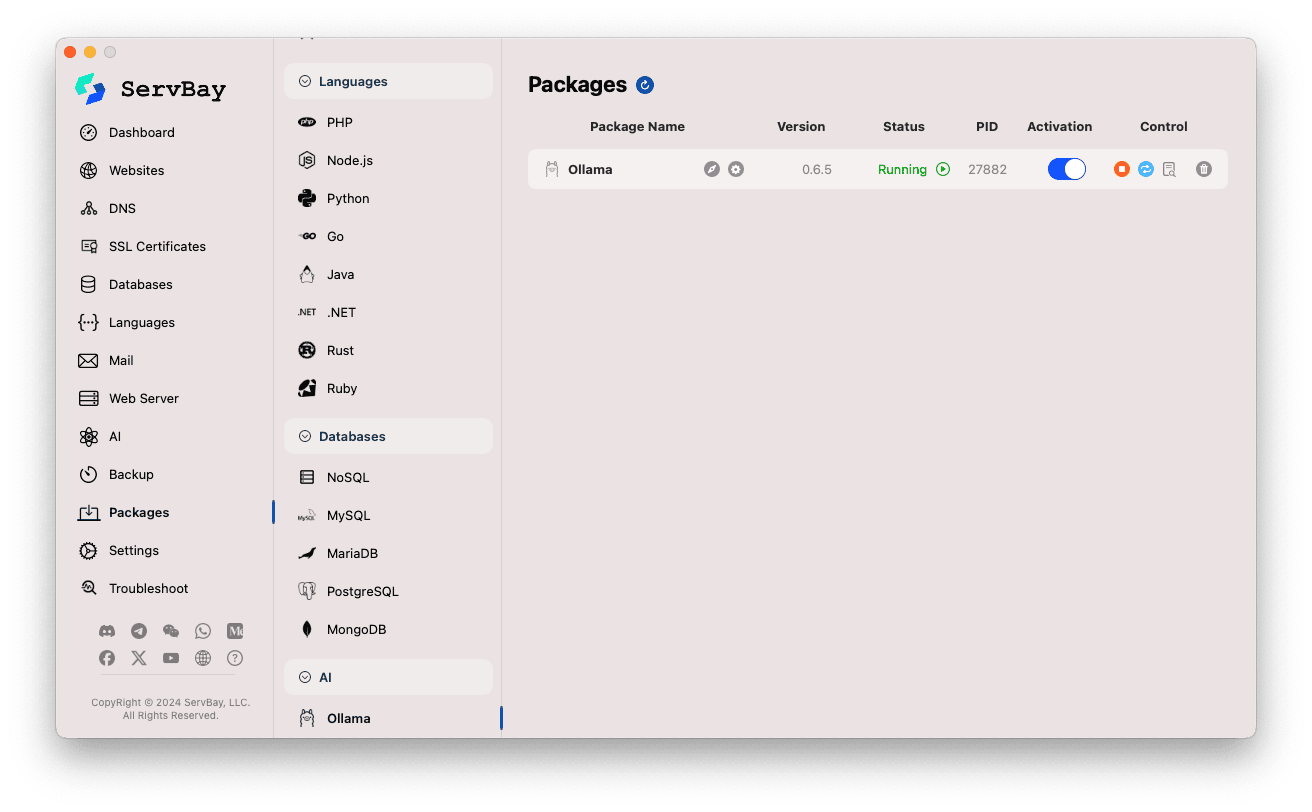
Akses Paket Ollama:
- Buka aplikasi ServBay.
- Pada panel navigasi kiri, klik
Paket(Packages). - Pada daftar yang terbuka, temukan dan klik kategori
AI. - Klik
Ollama.
Kelola Layanan Ollama:
- Di area kanan, Anda akan melihat informasi status paket Ollama, termasuk versi (misalnya
0.6.5), status operasi (RunningatauStopped), dan ID Proses (PID). - Gunakan tombol kontrol di sebelah kanan:
- Start/Stop: Tombol bulat oranye untuk memulai atau menghentikan layanan Ollama.
- Restart: Tombol refresh biru untuk me-restart layanan Ollama.
- Konfigurasi: Tombol roda gigi kuning untuk masuk ke halaman konfigurasi Ollama.
- Hapus: Tombol tempat sampah merah untuk mencopot paket Ollama (gunakan dengan hati-hati).
- Info Selengkapnya: Tombol informasi abu-abu bisa memberikan informasi tambahan atau akses log.
- Di area kanan, Anda akan melihat informasi status paket Ollama, termasuk versi (misalnya
Konfigurasi Ollama
ServBay menyediakan antarmuka grafis untuk menyesuaikan parameter operasi Ollama sesuai kebutuhan Anda.
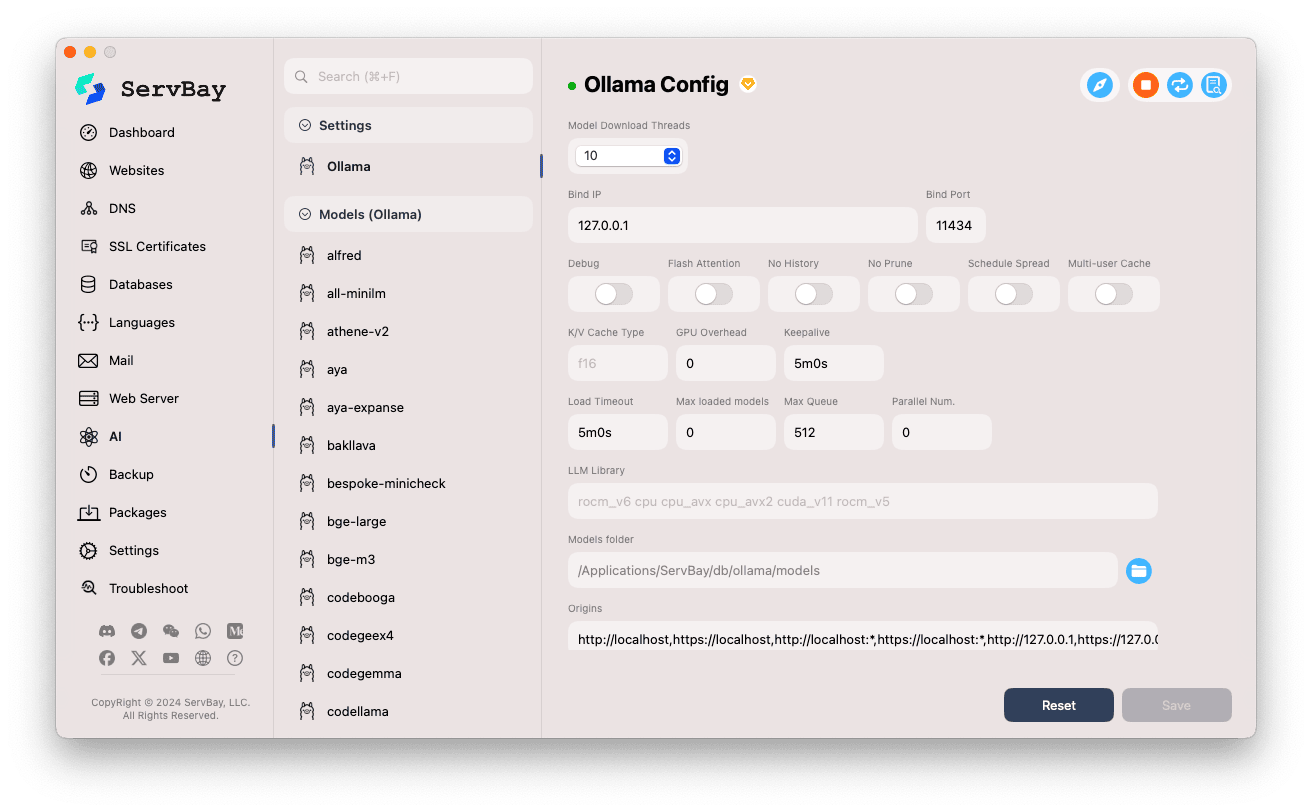
Akses Halaman Konfigurasi:
- Buka aplikasi ServBay.
- Pada panel navigasi kiri, klik
AI. - Pada daftar yang terbuka, temukan dan klik kategori
Pengaturan (Settings). - Klik
Ollama.
Penyesuaian Parameter:
- Model Download Threads: Atur jumlah thread untuk mengunduh model secara paralel, mempercepat proses unduhan.
- Bind IP: Alamat IP yang didengar layanan Ollama. Default adalah
127.0.0.1, hanya dapat diakses secara lokal. - Bind Port: Port yang digunakan untuk layanan Ollama. Default:
11434. - Opsi Saklar Boolean:
Debug: Aktifkan mode debug.Flash Attention: Kemungkinan mengaktifkan optimasi Flash Attention (memerlukan dukungan hardware).No History: Nonaktifkan pencatatan riwayat sesi.No Prune: Nonaktifkan pembersihan otomatis model yang tidak digunakan.Schedule Spread: Terkait kebijakan penjadwalan.Multi-user Cache: Terkait caching untuk banyak pengguna.
- Tipe K/V Cache: Tipe cache Key/Value; memengaruhi kinerja dan penggunaan memori.
- Terkait GPU:
GPU Overhead: Konfigurasi overhead GPU.Keepalive: Pengaturan waktu GPU tetap aktif.
- Pemrosesan Model & Antrian:
Load Timeout: Waktu maksimal pemuatan model.Max loaded models: Jumlah maksimal model yang dimuat sekaligus ke dalam memori.Max Queue: Batas panjang antrian permintaan.Parallel Num.: Jumlah permintaan yang diproses serentak.
- LLM Library: Tentukan path library LLM yang digunakan.
- Models folder: Direktori lokal tempat Ollama mengunduh dan menyimpan model. Default:
/Applications/ServBay/db/ollama/models. Anda dapat mengklik ikon folder untuk membuka direktori ini di Finder. - origins: Atur sumber yang diizinkan untuk mengakses API Ollama (pengaturan CORS cross-domain). Default sudah meliputi alamat lokal umum (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1, dll.). Jika Anda ingin web app dari domain lain dapat mengakses, tambahkan alamat sumber di sini.
Simpan Pengaturan: Setelah mengubah konfigurasi, klik tombol
Savedi kanan bawah untuk menerapkan perubahan.
Mengelola Model Ollama
ServBay memudahkan proses pencarian, pengunduhan, dan manajemen model Ollama.
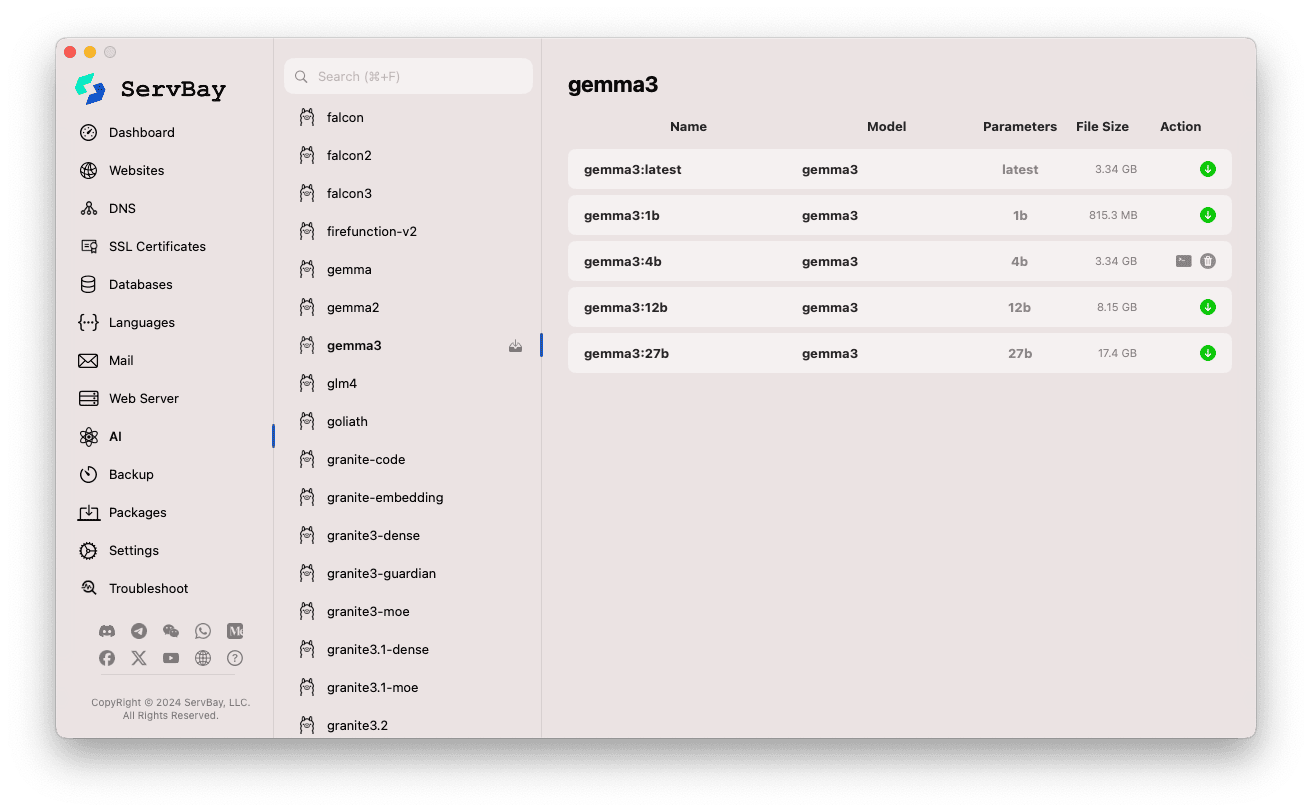
Akses Antarmuka Manajemen Model:
- Buka aplikasi ServBay.
- Pada panel navigasi kiri, klik
AI. - Pada daftar yang terbuka, temukan dan klik
Models (Ollama).
Menelusuri & Mengunduh Model:
- Di kiri, Anda akan menemukan berbagai koleksi model yang didukung Ollama (misal
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistral, dll.). Klik nama koleksi model (misalgemma3). - Bagian kanan menampilkan varian atau versi model, biasanya dibedakan berdasarkan jumlah parameter (seperti
latest,1b,4b,12b,27b). - Setiap baris menampilkan nama model, model dasar, jumlah parameter, dan ukuran file.
- Klik tombol panah unduh hijau di kanan untuk mulai mengunduh model tersebut. Progres unduhan akan tampil di antarmuka. Anda dapat mempercepat unduhan dengan mengatur jumlah thread di
Pengaturan. - Untuk model yang sudah diunduh, tombol unduh akan berubah abu-abu atau tidak bisa diklik.
- Di kiri, Anda akan menemukan berbagai koleksi model yang didukung Ollama (misal
Manajemen Model yang Sudah Diunduh:
- Model yang sudah diunduh umumnya punya tanda jelas (misal, tombol unduh berwarna abu atau ada tombol hapus).
- Klik tombol hapus (ikon tempat sampah) untuk menghapus file model lokal dan mengosongkan ruang disk.
Menggunakan API Ollama
Setelah dijalankan, Ollama akan menyediakan REST API pada alamat Bind IP dan Bind Port yang dikonfigurasi (default: 127.0.0.1:11434). Anda dapat menggunakan HTTP client apa saja (seperti curl, Postman, atau library pemrograman) untuk berinteraksi dengan model yang sudah diunduh.
TIP
ServBay menyediakan domain dengan enkripsi SSL/TLS https://ollama.servbay.host untuk akses HTTPS yang aman.
Anda dapat menggunakan domain https://ollama.servbay.host sebagai ganti IP:port untuk mengakses API Ollama.
Contoh: Berinteraksi dengan Model gemma3:latest Terunduh via curl
Pastikan Anda sudah mengunduh model gemma3:latest melalui ServBay dan layanan Ollama sedang berjalan.
bash
# Menggunakan https yang disediakan ServBay
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# Atau cara tradisional menggunakan IP:port
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'Penjelasan Perintah:
http://127.0.0.1:11434/api/generate: Endpoint API untuk menghasilkan teks dari Ollama.-d '{...}': Mengirim body POST request berupa data JSON."model": "gemma3:latest": Nama model yang akan digunakan (harus sudah diunduh)."prompt": "Why is the sky blue?": Pertanyaan atau prompt yang ingin diajukan ke model."stream": false: Jikafalse, menunggu hingga model selesai merespons lalu mengembalikan hasil secara penuh. Jikatrue, response akan dikirim secara streaming per token.
Output yang Diharapkan:
Anda akan menerima respons JSON di terminal, di mana field response berisi jawaban dari model terhadap "Why is the sky blue?".
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... metadata lainnya
}Catatan CORS: Jika Anda ingin mengakses API Ollama dari kode JavaScript di browser, pastikan alamat asal Web App Anda (misal http://myapp.servbay.demo) telah ditambahkan ke daftar origins di pengaturan Ollama. Jika tidak, permintaan akan diblokir browser karena kebijakan CORS.
Skenario Penggunaan
Menjalankan Ollama secara lokal di ServBay membawa banyak keuntungan, antara lain:
- Pengembangan AI Lokal: Tidak perlu API eksternal atau layanan cloud; kembangkan dan uji aplikasi berbasis LLM langsung di perangkat Anda.
- Prototyping Cepat: Coba berbagai model open-source dengan mudah untuk menguji ide-ide Anda.
- Penggunaan Offline: Tetap dapat menggunakan LLM tanpa koneksi internet.
- Privasi Data: Semua data dan interaksi tetap di komputer Anda; tidak perlu mengkhawatirkan data terkirim ke pihak ketiga.
- Efisiensi Biaya: Tidak ada biaya berlangganan layanan AI cloud berbasis pemakaian.
Perhatian
- Ruang Disk: File model LLM sangat besar (beberapa GB hingga puluhan GB). Pastikan ada ruang kosong cukup di hard disk. Model secara default disimpan di
/Applications/ServBay/db/ollama/models. - Sumber Daya Sistem: Menjalankan LLM membutuhkan banyak CPU, memori (RAM), dan jika Mac Anda memiliki GPU yang kompatibel, Ollama mungkin menggunakan GPU untuk akselerasi, sehingga mengonsumsi resource GPU juga. Pastikan spesifikasi Mac Anda cukup untuk model yang ingin dijalankan.
- Waktu Unduh: Proses pengunduhan model membutuhkan waktu, tergantung kecepatan internet dan besar file model.
- Firewall: Jika Anda mengubah
Bind IPmenjadi0.0.0.0agar perangkat di jaringan lokal bisa mengakses, pastikan firewall macOS mengizinkan koneksi masuk pada port yang digunakan Ollama (11434).
Kesimpulan
Dengan mengintegrasikan Ollama, ServBay sangat mempermudah proses deployment dan manajemen model bahasa besar lokal di macOS. Melalui antarmuka grafis yang intuitif, pengembang dapat dengan mudah memulai layanan, mengatur konfigurasi, mengunduh model, dan dengan cepat membangun serta bereksperimen dengan aplikasi AI secara lokal—menambah nilai ServBay sebagai lingkungan pengembangan all-in-one di perangkat Anda.
