
استخدام Ollama داخل ServBay
لقد دمجت ServBay قدرات الذكاء الاصطناعي المحلية القوية في بيئة تطويرك، مما يمكنك من تشغيل نماذج اللغة الكبيرة مفتوحة المصدر (LLM) بسهولة عبر Ollama على نظام macOS. سيرشدك هذا الدليل خلال تفعيل، ضبط، إدارة Ollama ونماذجه ضمن ServBay، والبدء في استخدامها.
نظرة عامة
Ollama هو أداة شهيرة تسهل عملية تنزيل، إعداد، وتشغيل نماذج اللغة الكبيرة على جهازك المحلي. تقدم ServBay تكامل Ollama كحزمة مستقلة مع واجهة إدارة رسومية، تتيح للمطورين:
- تشغيل، إيقاف، وإعادة تشغيل خدمة Ollama بنقرة واحدة.
- ضبط إعدادات Ollama عبر واجهة رسومية سهلة الاستخدام.
- تصفح، تنزيل وإدارة نماذج LLM المدعومة.
- تطوير، اختبار وتجربة تطبيقات الذكاء الاصطناعي محليًا بدون الاعتماد على الخدمات السحابية.
المتطلبات المسبقة
- يجب تثبيت وتشغيل ServBay على نظام macOS لديك.
تفعيل وإدارة خدمة Ollama
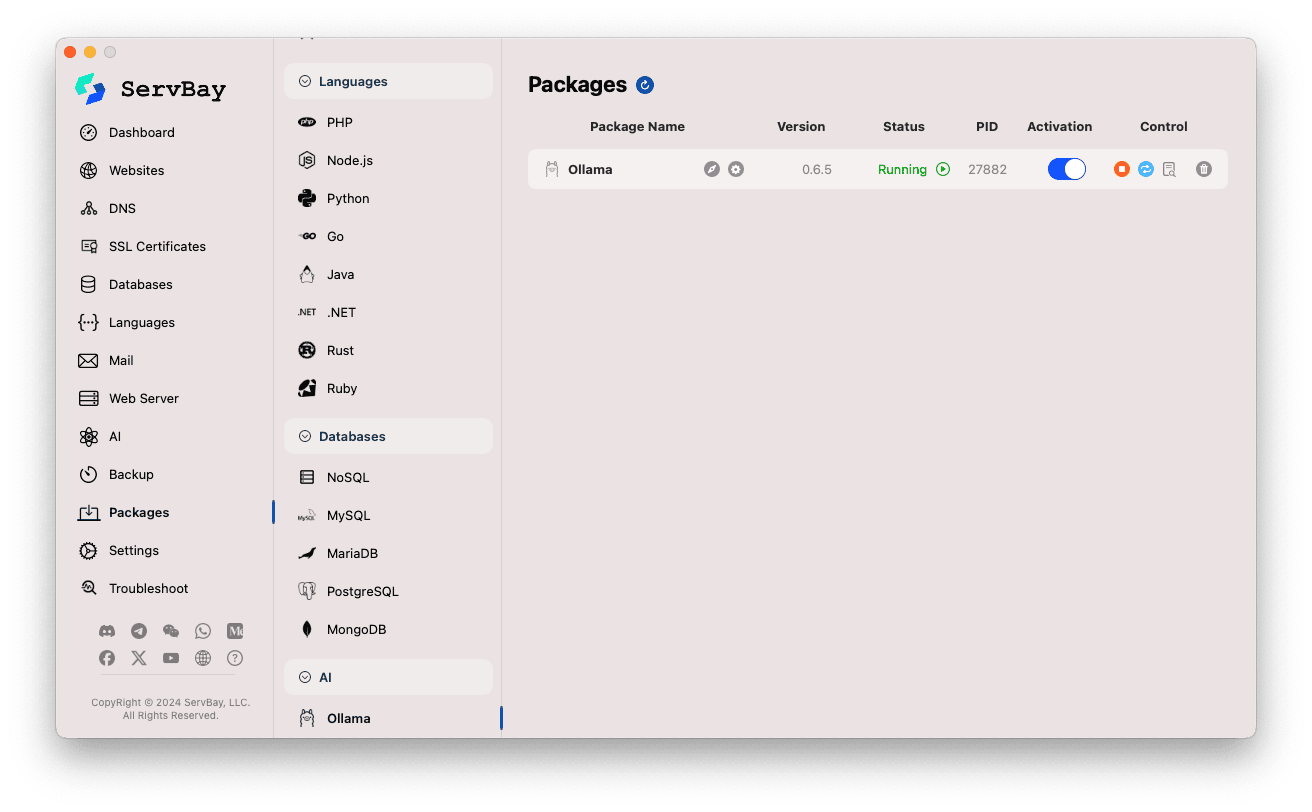
يمكنك إدارة حزمة Ollama بسهولة من خلال الواجهة الرئيسية لـ ServBay.
الوصول إلى حزمة Ollama:
- افتح تطبيق ServBay.
- من شريط التنقل الأيسر، انقر على
الحزم(Packages). - من القائمة المنسدلة، ابحث وانقر على فئة
AI. - انقر على
Ollama.
إدارة خدمة Ollama:
- سيظهر لك على الجانب الأيمن حالة الحزمة، بما في ذلك رقم الإصدار (مثال:
0.6.5)، الحالة الحالية (تشغيلأومتوقف)، ومعرف العملية (PID). - استخدم أزرار التحكم على اليمين:
- تشغيل/إيقاف: زر دائري برتقالي لتشغيل أو إيقاف الخدمة.
- إعادة تشغيل: زر أزرق لتحديث الخدمة.
- الإعدادات: زر أصفر بشكل ترس للانتقال لصفحة الإعدادات.
- حذف: زر سلة مهملات أحمر لإلغاء تثبيت الحزمة (يرجى الحذر).
- مزيد من المعلومات: زر رمادي للمعلومات أو الوصول لسجلات إضافية.
- سيظهر لك على الجانب الأيمن حالة الحزمة، بما في ذلك رقم الإصدار (مثال:
ضبط إعدادات Ollama
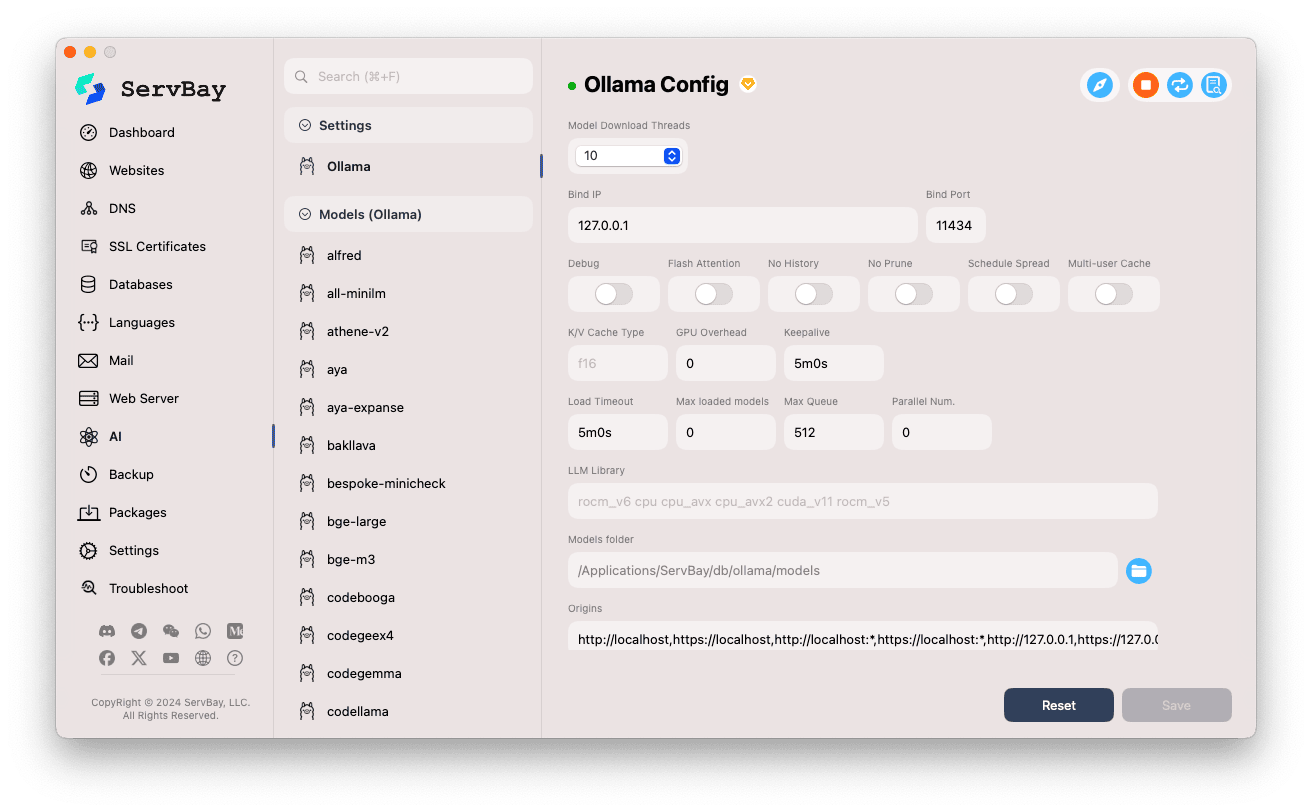
توفر ServBay واجهة رسومية لتعديل إعدادات تشغيل Ollama حسب احتياجاتك المختلفة.
الدخول إلى واجهة الإعدادات:
- افتح تطبيق ServBay.
- من شريط التنقل الأيسر، اختر
AI. - من القائمة المنسدلة، اختر فئة
الإعدادات (Settings). - انقر على
Ollama.
تعديل خيارات الضبط:
- عدد خيوط تنزيل النموذج: تحدد عدد خيوط التنزيل المتزامنة لتسريع عملية تنزيل النماذج.
- العنوان IP المربوط: عنوان IP الذي تستمع عليه خدمة Ollama (افتراضيًا
127.0.0.1، أي الوصول من الجهاز فقط). - المنفذ المربوط: منفذ خدمات Ollama (افتراضيًا
11434). - خيارات التبديل:
Debug: تفعيل وضع تصحيح الأخطاء.Flash Attention: تفعيل تحسين Flash Attention (يتطلب دعمًا عتاديًا).No History: تعطيل تسجيل المحادثات السابقة.No Prune: تعطيل تنظيف النماذج غير المستخدمة تلقائيًا.Schedule Spread: يتعلق باستراتيجيات الجدولة.Multi-user Cache: خيارات التخزين المؤقت لعدة مستخدمين.
- نوع ذاكرة K/V: نوع ذاكرة المفاتيح/القيم للتخزين المؤقت، ما يؤثر على الأداء والاستهلاك.
- خيارات متعلقة بـ GPU:
GPU Overhead: إعداد حمل الـ GPU.Keepalive: مدة إبقاء الـ GPU نشطًا.
- تحميل النماذج وقائمة الانتظار:
Load Timeout: مهلة تحميل النموذج.Max loaded models: الحد الأقصى للنماذج المحملة في الذاكرة.Max Queue: طول قائمة الانتظار للطلبات.Parallel Num.: عدد الطلبات المتزامنة.
- مكتبة LLM: المسار للمكتبة البرمجية الأساسية للنموذج.
- مجلد النماذج: مجلد تخزين وتحميل النماذج محليًا (افتراضيًا
/Applications/ServBay/db/ollama/models). يمكنك فتحه في Finder بالنقر على أيقونة المجلد. - الأصول (origins): تكوين مصادر الوصول المسموح بها لـ Ollama API (إعداد CORS). يشمل بشكل افتراضي العناوين المحلية الشهيرة (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1إلخ). إذا كنت ترغب في السماح لتطبيقات ويب أخرى بالوصول، أضف مصادرها هنا.
حفظ الإعدادات: بعد التعديل، اضغط زر
Saveفي أسفل اليمين لحفظ التعديلات وتطبيقها.
إدارة نماذج Ollama
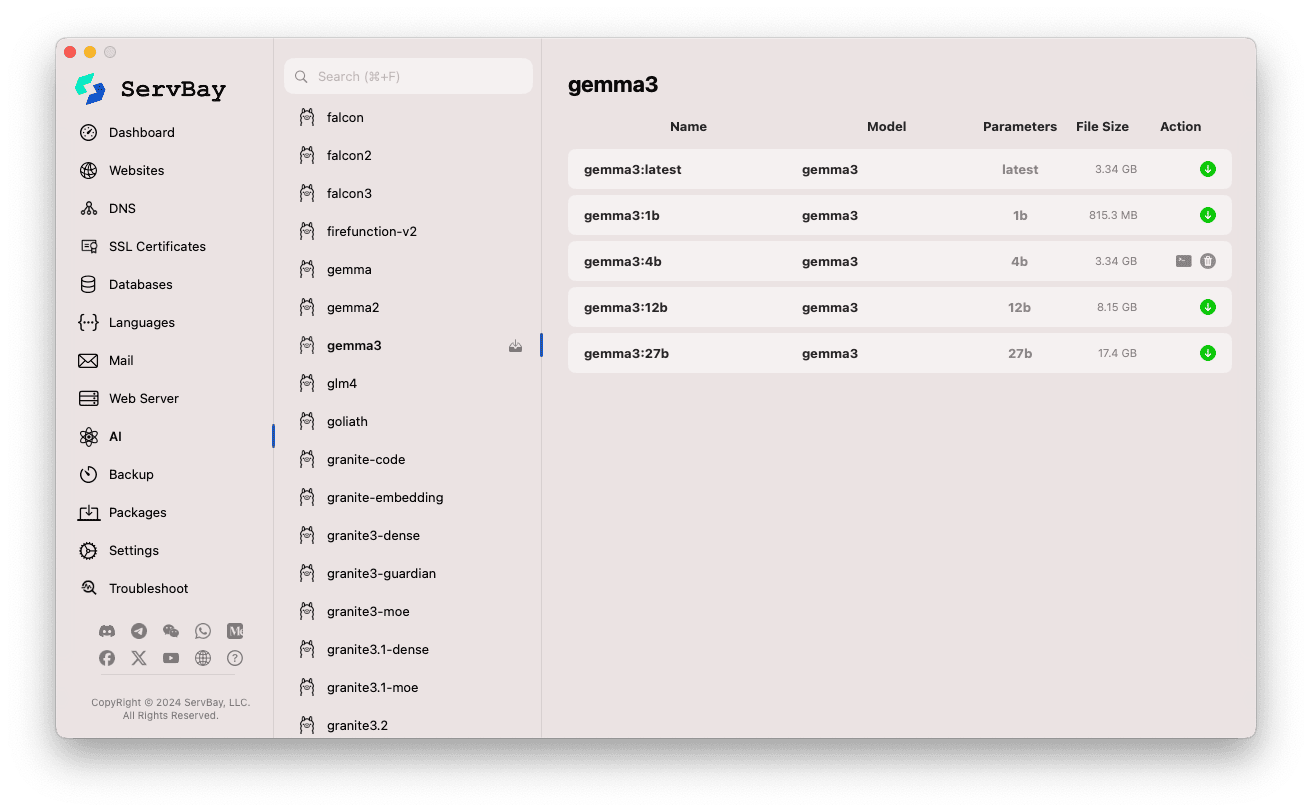
جعلت ServBay عملية اكتشاف، تحميل وإدارة نماذج Ollama أكثر سهولة.
الوصول إلى واجهة إدارة النماذج:
- افتح تطبيق ServBay.
- من شريط التنقل الأيسر، اختر
AI. - ومن القائمة، اختر
Models (Ollama).
تصفح وتنزيل النماذج:
- ستجد على اليسار قائمة بمستودعات النماذج المدعومة (مثلاً:
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistral... إلخ). انقر على اسم المستودع المطلوب (مثلاًgemma3). - سيظهر على اليمين الإصدارات أو المتغيرات المتاحة بالكامل حسب حجم النموذج (مثل:
latest,1b,4b,12b,27b). - ستجد في كل صف اسم النموذج، النموذج الأساسي، عدد المعاملات، وحجم الملف.
- لتنزيل نموذج، انقر زر السهم الأخضر على يمين الصف. سيتم عرض تقدم التنزيل بالواجهة. يمكنك تسريع التنزيل عبر تعديل
عدد خيوط التنزيلمن الإعدادات. - النماذج المنزلة مسبقًا سيظهر زر تحميلها رماديًا أو غير متاح.
- ستجد على اليسار قائمة بمستودعات النماذج المدعومة (مثلاً:
إدارة النماذج المنزلة:
- النماذج المنزلة سيتم تمييزها بوضوح (مثلاً يمكنك حذفها عبر رمز سلة المهملات).
- لحذف نموذج وتحرير مساحة القرص، انقر زر الحذف (عادة بشكل سلة مهملات) على يمين النموذج.
استخدام واجهة Ollama API
عند تشغيل Ollama، سيتوفر لديك REST API على العنوان Bind IP والمنفذ Bind Port (افتراضيًا 127.0.0.1:11434). يمكنك التفاعل مع النماذج المنزّلة باستخدام أي عميل HTTP مثل curl، Postman، أو مكتبات البرمجة.
TIP
تقدم ServBay لك دومين مشفر بـ SSL/TLS يدعم الوصول عبر HTTPS: https://ollama.servbay.host
يمكنك الاستفادة من هذا الدومين، بدلاً من استخدام عنوان الـ IP والمنفذ، للوصول إلى واجهة Ollama API.
مثال: استخدام curl للتفاعل مع نموذج gemma3:latest المنزّل
تأكد أنك قمت بتنزيل نموذج gemma3:latest وأن خدمة Ollama قيد التشغيل عبر ServBay.
bash
# استخدام https المقدم من ServBay
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# أو بالطريقة التقليدية باستخدام عنوان IP والمنفذ
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'شرح الأوامر:
http://127.0.0.1:11434/api/generate: نقطة نهاية API لتوليد النص.-d '{...}': إرسال جسم POST بتنسيق JSON."model": "gemma3:latest": اسم النموذج (يجب أن يكون منزلاً مسبقًا)."prompt": "Why is the sky blue?": السؤال أو الموجه المرسل للنموذج."stream": false: لضبط الإرجاع المتدفق (إذا true يرجع الاستجابة بشكل تدريجي، إذا false ينتظر الرد الكامل).
الناتج المتوقع:
سيظهر لك في الطرفية استجابة JSON في الحقل response وتحتوي الإجابة على سؤال "Why is the sky blue?".
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... بيانات إضافية
}ملاحظة حول CORS: إذا كنت تستخدم كود JavaScript في المتصفح للاتصال بواجهة Ollama API، تأكد من إضافة دومين تطبيقك (مثل http://myapp.servbay.demo) لقائمة origins في إعدادات Ollama، وإلا قد يتم منع الطلب من قبل المتصفح بسبب سياسات CORS.
حالات الاستخدام
تشغيل Ollama محليًا ضمن ServBay يوفر لك العديد من الفوائد:
- تطوير الذكاء الاصطناعي محليًا: يمكنك تطوير واختبار تطبيقات LLM محليًا بدون الحاجة لأي API خارجي أو خدمات سحابية.
- تصميم أولي سريع: تجربة نماذج مفتوحة المصدر مختلفة بسرعة للتحقق من أفكارك.
- تشغيل دون اتصال: يمكنك استخدام النماذج بدون الحاجة لاتصال بالإنترنت.
- الخصوصية: جميع بياناتك والتفاعلات مع النموذج محليًا، فلا داعي للقلق حول نقلها لطرف ثالث.
- فعالية في التكلفة: لا حاجة لدفع مقابل استخدام واجهات الذكاء الاصطناعي السحابية.
ملاحظات هامة
- مساحة القرص: ملفات النماذج عادة كبيرة الحجم (من عدة جيجابايت وحتى عشرات الجيجابايت)، تأكد من توافر مساحة كافية. يتم حفظ النماذج بشكل افتراضي في
/Applications/ServBay/db/ollama/models. - موارد النظام: تشغيل LLM يستهلك كثيرًا من المعالج والذاكرة (RAM). إن كان لديك GPU مدعوم على جهاز الماك الخاص بك، فقد يستفيد Ollama من تسريع الـ GPU أيضًا. تأكد من أن مواصفات جهازك مناسبة للنماذج التي ترغب بتشغيلها.
- وقت التنزيل: تنزيل النماذج قد يستغرق بعض الوقت حسب سرعة الإنترنت وحجم النموذج.
- جدار الحماية: إذا غيرت إعداد الـ
Bind IPإلى0.0.0.0للسماح للأجهزة الأخرى على الشبكة بالوصول، تأكد من ضبط جدار حماية macOS للسماح بالاتصال بمنفذ Ollama (11434).
خلاصة
يسهل عليك ServBay عبر دمجه لـ Ollama نشر وإدارة نماذج اللغة الكبيرة محليًا على macOS. من خلال واجهة رسومية بديهية، يمكنك تشغيل الخدمة، تعديل الإعدادات، تنزيل وإدارة النماذج بسهولة، ثم الشروع مباشرة في تطوير تطبيقات الذكاء الاصطناعي المحلية الخاصة بك، مما يعزز من قيمة ServBay كبيئة تطوير محلية متكاملة وشاملة.
