
ServBay में Ollama का उपयोग कैसे करें
ServBay आपके विकास वातावरण में शक्तिशाली स्थानीय AI क्षमताएं जोड़ता है, जिससे आप Ollama के माध्यम से macOS पर विभिन्न ओपन सोर्स बड़े भाषा मॉडल (LLM) आसानी से चला सकते हैं। यह दस्तावेज़ आपको ServBay में Ollama एवं उसके मॉडल को सक्षम, कॉन्फिगर व प्रबंधित करने, साथ ही शुरुआत करने की विस्तृत प्रक्रिया बताता है।
परिचय
Ollama एक लोकप्रिय टूल है, जो आपके लोकल कंप्यूटर पर बड़े भाषा मॉडल को डाउनलोड, सेटअप और चलाने की प्रक्रिया को सरल बनाता है। ServBay ने Ollama को एक स्वतंत्र सॉफ़्टवेयर पैकेज के रूप में एकीकृत किया है, साथ ही एक ग्राफिकल प्रबंधक इंटरफ़ेस प्रदान किया है, जिससे डेवलपर्स को मिलते हैं:
- एक क्लिक से Ollama सेवा चालू, बंद या रीस्टार्ट करने की सुविधा।
- ग्राफिकल UI के माध्यम से Ollama के विभिन्न पैरामीटर्स को कॉन्फिगर करने का विकल्प।
- समर्थित LLM मॉडल्स को ब्राउज़, डाउनलोड और प्रबंधित करने की सुविधा।
- पूरी तरह स्थानीय स्तर पर AI एप्लिकेशन का विकास, परीक्षण और प्रयोग – क्लाउड सेवाओं पर निर्भरता बिना।
आवश्यकताएँ
- आपके macOS सिस्टम पर ServBay स्थापित और चालू हो।
Ollama सेवा को सक्षम और प्रबंधित करना
ServBay के मुख्य इंटरफ़ेस के माध्यम से आप Ollama पैकेज को आसानी से प्रबंधित कर सकते हैं।
Ollama पैकेज तक पहुंचें:
- ServBay एप्लिकेशन खोलें।
- बाईं ओर नेविगेशन पैनल में
सॉफ्टवेयर पैकेज(Packages) पर क्लिक करें। - खुली सूची में से
AIवर्ग खोजें और चुनें। Ollamaपर क्लिक करें।
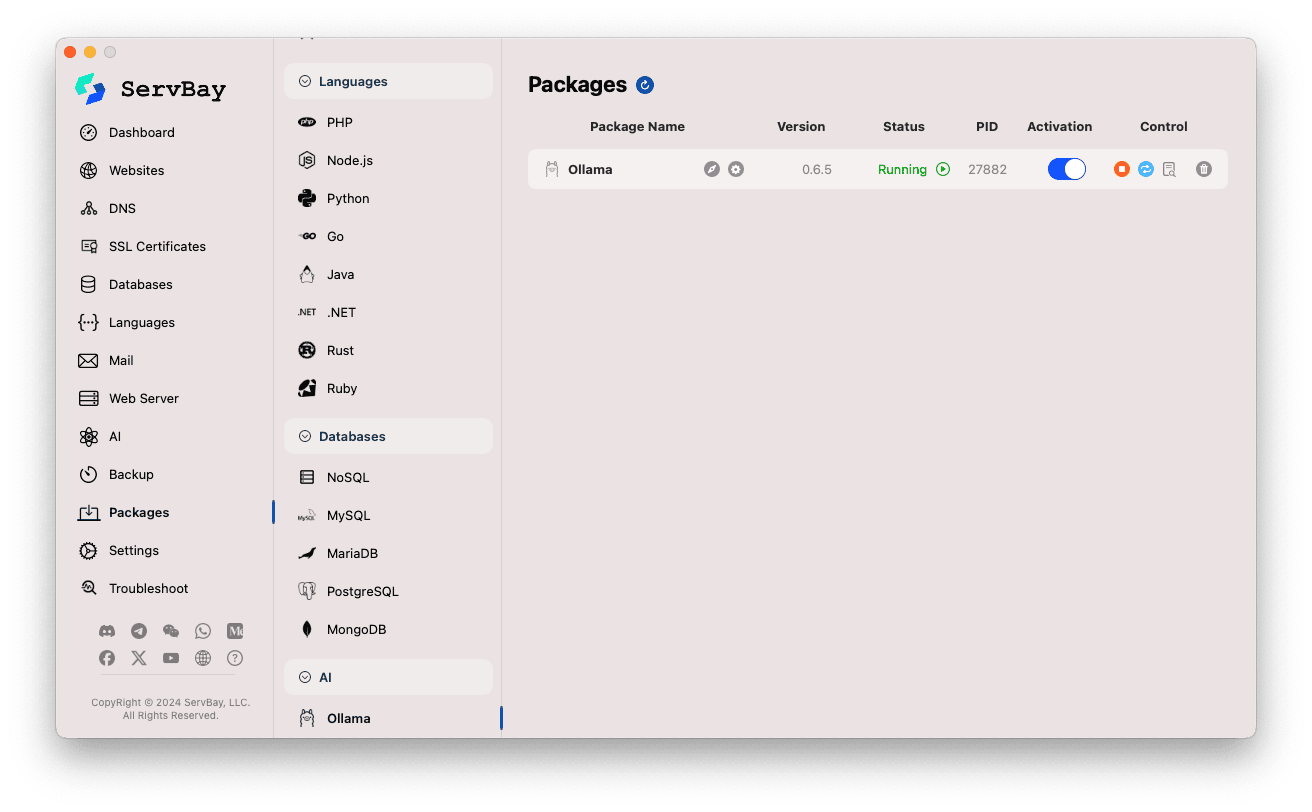
Ollama सेवा प्रबंधन:
- दाएं पैनल में आप Ollama पैकेज की स्थिति देख सकेंगे—संस्करण संख्या (जैसे
0.6.5), रनिंग स्टेटस (RunningयाStopped), प्रक्रिया आईडी (PID)। - दाईं ओर दिए गए नियंत्रण बटनों का उपयोग करें:
- स्टार्ट/स्टॉप: नारंगी गोल बटन से Ollama सेवा शुरू या बंद करें।
- रीस्टार्ट: नीला रिफ्रेश बटन सेवा को पुनः चालू करता है।
- कॉन्फ़िगरेशन: पीला गियर बटन Ollama के सेटिंग पेज पर ले जाता है।
- हटाएँ: लाल डस्टबिन बटन Ollama पैकेज अनइंस्टॉल करने के लिए है (सावधानीपूर्वक उपयोग करें)।
- अधिक जानकारी: ग्रे ‘i’ बटन अतिरिक्त सूचना या लॉग प्रदर्शित कर सकता है।
- दाएं पैनल में आप Ollama पैकेज की स्थिति देख सकेंगे—संस्करण संख्या (जैसे
Ollama का कॉन्फ़िगरेशन
ServBay आपको ग्राफिकल इंटरफ़ेस प्रदान करता है, जिससे आप Ollama के संचालन से जुड़ी सेटिंग्स को अपनी जरूरत अनुसार बदल सकते हैं।
सेटिंग्स पेज खोलें:
- ServBay एप्लिकेशन खोलें।
- बाईं ओर नेविगेशन में
AIपर क्लिक करें। - सूची में से
सेटिंग्स (Settings)वर्ग चुनें। Ollamaपर क्लिक करें।
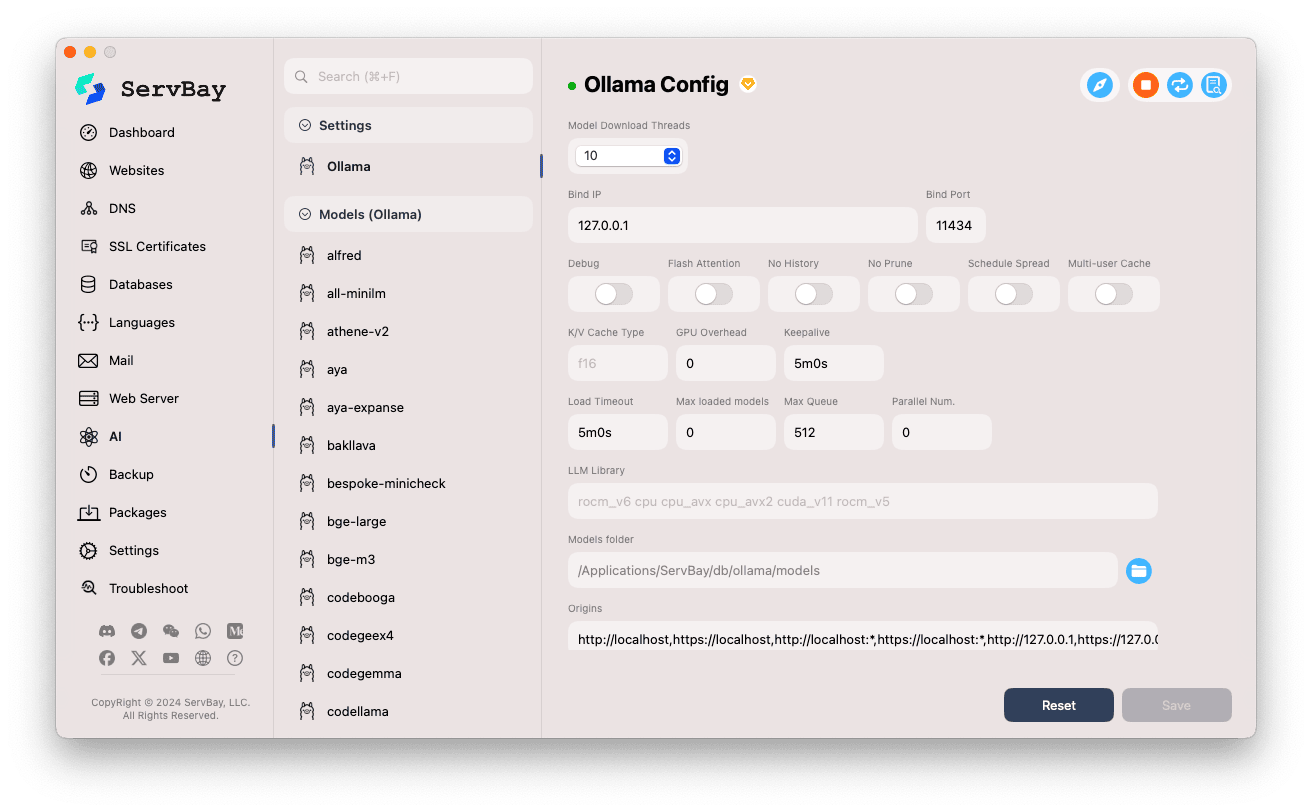
कॉन्फ़िगरेशन विकल्प बदलें:
- Model Download Threads: एक साथ कितने मॉडल डाउनलोड होंगे, यह सेट करें; इससे डाउनलोड गति बढ़ सकती है।
- Bind IP: Ollama सेवा किस IP पते पर सुनेगी। डिफॉल्ट –
127.0.0.1(केवल लोकल मशीन द्वारा एक्सेस योग्य)। - Bind Port: Ollama सेवा का पोर्ट, डिफॉल्ट –
11434। - स्विच विकल्प:
Debug: डिबग मोड सक्रिय करें।Flash Attention: हार्डवेयर सपोर्ट होने पर फ्लैश अटेंशन अनुकूलन।No History: सेशन हिस्ट्री सहेजना बंद करे।No Prune: अप्रयुक्त मॉडल ऑटो-क्लीयर नहीं होंगे।Schedule Spread: शेड्यूलिंग संबंधी सेटिंग।Multi-user Cache: मल्टी-यूज़र कैश से जुड़ा विकल्प।
- K/V Cache Type: की-वैल्यू कैशिंग का प्रकार, प्रदर्शन और मेमोरी उपयोग पर प्रभाव डालता है।
- GPU संबंधित सेटिंग्स:
GPU Overhead: GPU लोड प्रबंधन के लिए।Keepalive: GPU सक्रिय रखने का समय।
- मॉडल लोडिंग और कतार:
Load Timeout: मॉडल लोडिंग के लिए अधिकतम प्रतीक्षा।Max loaded models: एक साथ RAM में लोड किए जा सकने वाले मॉडलों की अधिकतम संख्या।Max Queue: रिक्वेस्ट कतार की अधिकतम लंबाई।Parallel Num.: एक साथ कितने अनुरोध प्रोसेस होंगे।
- LLM Library: किस LLM लाइब्रेरी का उपयोग करना है, उसका पथ।
- Models folder: Ollama द्वारा मॉडल डाउनलोड व स्टोर करने का स्थानीय फ़ोल्डर। डिफॉल्ट –
/Applications/ServBay/db/ollama/models। फ़ोल्डर आइकन पर क्लिक कर Finder में खोल सकते हैं। - origins: Ollama API तक पहुंचने की अनुमति देने वाले सोर्सेज़—(CORS सेटिंग)। डिफॉल्ट में सामान्य लोकल ऐड्रेस शामिल हैं (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1इत्यादि)। यदि आप किसी अन्य डोमेन से Web App द्वारा API उपयोग करना चाहते हैं, तो वहां सम्बंधित स्रोत जोड़ें।
सेटिंग्स सहेजें: बदलाव करने के बाद नीचे दाएं
Saveबटन पर क्लिक करें; तभी बदलाव रिकॉर्ड होंगे।
Ollama मॉडल प्रबंधन
ServBay के माध्यम से Ollama मॉडल्स को खोजना, डाउनलोड करना और प्रबंधित करना बहुत आसान है।
मॉडल प्रबंधन सेक्शन खोलें:
- ServBay एप्लिकेशन खोलें।
- बाईं ओर नेविगेशन में
AIपर क्लिक करें। - खुली सूची में से
Models (Ollama)चुनें।
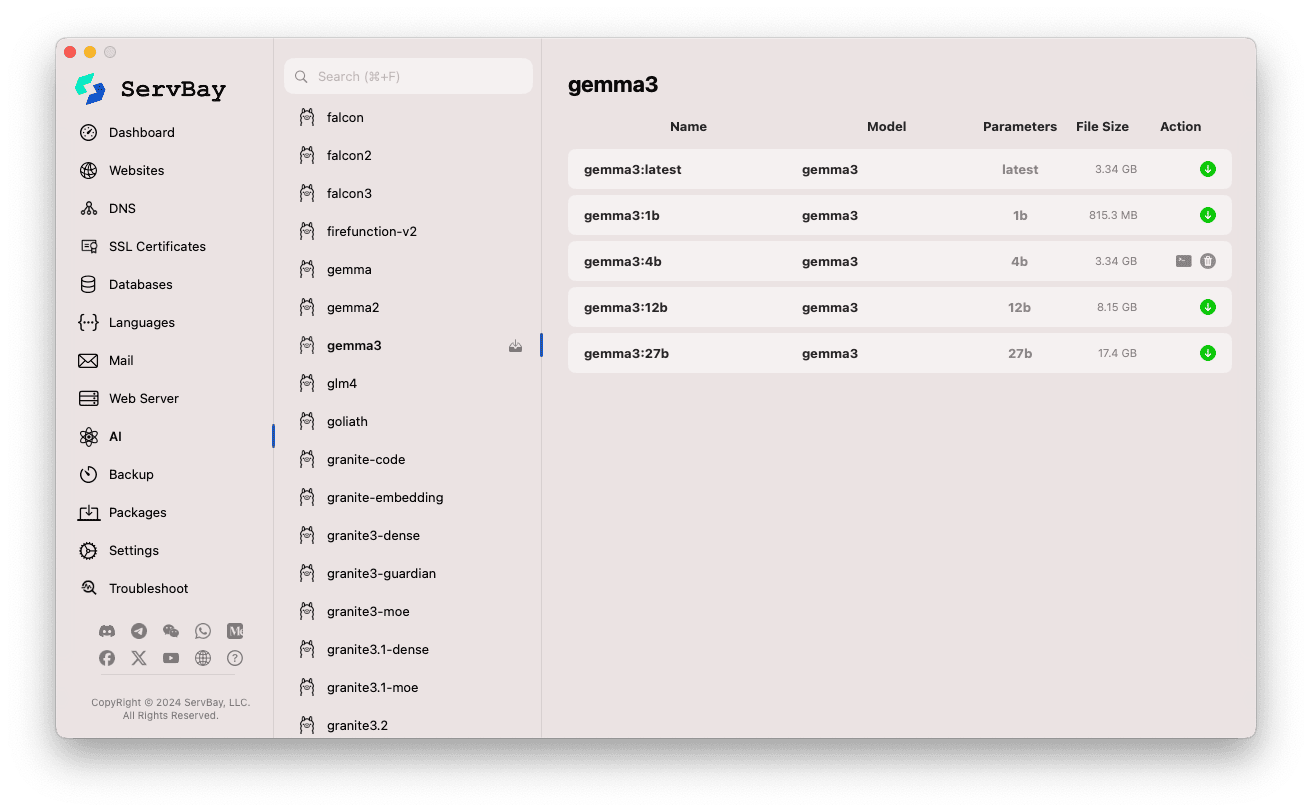
मॉडल ब्राउज़ व डाउनलोड करें:
- बाएं पैनल में आपको Ollama द्वारा सपोर्ट किए जाने वाले कई मॉडल लाइब्रेरीज दिखेंगी (
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistralआदि)। किसी लाइब्रेरी (जैसेgemma3) का नाम क्लिक करें। - दाएं पैनल में आपको उस लाइब्रेरी से जुड़े विभिन्न वेरिएंट्स/संस्करण दिखेंगे—आमतौर पर पैरामीटर संख्या के आधार पर (
latest,1b,4b,12b,27b)। - हर लाइन में मॉडल का नाम, बेस मॉडल, पैरामीटर संख्या, फाइल साइज़ आदि सूचीबद्ध होते हैं।
- दाएं छोर पर हरे रंग का तीर वाला ‘डाउनलोड’ बटन क्लिक करें – डाउनलोड प्रक्रिया प्रारंभ होगी और उसकी प्रगति UI में दिखेगी। डाउनलोडिंग गति बढ़ाने के लिए Setting में ‘Download Threads’ संख्या बढ़ा सकते हैं।
- जो मॉडल पहले से डाउनलोड हो चुका है, उसका डाउनलोड बटन ग्रे हो जाएगा या नॉन-एक्टिव रहेगा।
- बाएं पैनल में आपको Ollama द्वारा सपोर्ट किए जाने वाले कई मॉडल लाइब्रेरीज दिखेंगी (
डाउनलोड किए मॉडल का प्रबंधन:
- डाउनलोड किए हुए मॉडल्स को सूची में पहचानना आसान रहेगा (जैसे, डाउनलोड बटन ग्रे हो जाता है या डिलीट बटन प्रकट होता है)।
- डिलीट बटन (आमतौर पर डस्टबिन आइकन) पर क्लिक कर आप उस मॉडल को लोकल सिस्टम से हटा सकते हैं और स्टोरेज खाली कर सकते हैं।
Ollama API का उपयोग
Ollama चालू होने पर, यह निर्धारित Bind IP और Bind Port (प्रायः 127.0.0.1:11434) पर REST API सर्विस मुहैया कराता है। आप चाहे तो किसी भी HTTP क्लाइंट (जैसे curl, Postman, या आपकी पसंदीदा प्रोग्रामिंग लाइब्रेरी) से डाउनलोड किए मॉडल्स को एक्सेस कर सकते हैं।
TIP
ServBay ने बड़ी सहूलियत दी है—SSL/TLS एन्क्रिप्शन के साथ HTTPS एक्सेस के लिए विशेष डोमेन https://ollama.servbay.host दिया गया है।
अब आप API को सीधे IP:पोर्ट से नहीं, बल्कि https://ollama.servbay.host डोमेन नाम के जरिये एक्सेस कर सकते हैं।
उदाहरण: curl से डाउनलोड किए गए gemma3:latest मॉडल के साथ संवाद
सुनिश्चित करें कि ServBay के माध्यम से आपने पहले ही gemma3:latest मॉडल डाउनलोड कर लिया है और Ollama सेवा चालू है।
bash
# ServBay द्वारा प्रदान किए गए https का उपयोग करें
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# या पारंपरिक IP:पोर्ट तरीका
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'कमांड विवरण:
http://127.0.0.1:11434/api/generate: Ollama का टेक्स्ट जनरेटिंग API एंडपॉइंट।-d '{...}': POST रिक्वेस्ट बॉडी, जिसमें JSON डेटा है।"model": "gemma3:latest": उपयोग किया जाने वाला मॉडल नाम (डाउनलोडेड होना जरूरी है)।"prompt": "Why is the sky blue?": मॉडल से पूछी जाने वाली क्वेरी या संकेत।"stream": false: जब false हो, तब मॉडल पूरा उत्तर एक साथ लौटाता है; true होने पर उत्तर स्ट्रीमिंग के रूप में मिलता है।
अपेक्षित आउटपुट:
आपको टर्मिनल पर एक JSON प्रतिक्रिया दिखेगी, जिसमें response फील्ड में "Why is the sky blue?" का उत्तर मौजूद होगा।
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... अन्य मेटाडेटा
}CORS नोट: यदि आप ब्राउज़र में JavaScript के माध्यम से Ollama API एक्सेस करना चाहें, तो सुनिश्चित करें कि आपके वेब ऐप का स्रोत (जैसे http://myapp.servbay.demo) Ollama कॉन्फ़िगरेशन की origins सूची में शामिल हो – अन्यथा CORS पॉलिसी के कारण अनुरोध अस्वीकार हो जाएंगे।
उपयोग के परिदृश्य
ServBay में लोकली Ollama चलाने के कई लाभ हैं:
- स्थानीय AI विकास: बिना बाहरी API या क्लाउड सर्विस की जरूरत के, सीधे लोकल मशीन पर LLM आधारित एप्लिकेशन का विकास व परीक्षण।
- त्वरित प्रोटोटाइपिंग: विभिन्न ओपन-सोर्स मॉडल्स आसानी से ट्राय करें, आइडिया से Validate करें।
- ऑफ़लाइन उपयोग: नेटवर्क न होने पर भी LLM के साथ संवाद संभव।
- डेटा गोपनीयता: सभी डेटा और संवाद पूरी तरह आपकी मशीन पर ही रहते हैं, किसी तीसरे पक्ष को ट्रांसफर नहीं होते।
- लागत में बचत: पे-पर-यूज़ क्लाउड AI सेवा के खर्च से बचें।
ध्यान देने योग्य बातें
- डिस्क स्पेस: बड़े भाषा मॉडल्स के फाइल्स आम तौर पर बहुत बड़े (कई GB से लेकर दशकों GB तक) होते हैं; सुनिश्चित करें कि आपकी डिस्क पर पर्याप्त जगह हो। डिफॉल्ट स्टोरेज पाथ है
/Applications/ServBay/db/ollama/models। - सिस्टम संसाधन: LLM को चलाना CPU और RAM का भारी उपयोग करता है; यदि आपके Mac में उपयुक्त GPU है, तो Ollama GPU एक्सेलरेशन का लाभ उठा सकता है—इससे GPU संसाधन भी लगते हैं। कृपया अपने Mac की क्षमताओं को ध्यान में रखें।
- डाउनलोड समय: मॉडल डाउनलोड में समय लगेगा, जो आपकी इंटरनेट स्पीड एवं मॉडल आकार पर निर्भर करता है।
- फ़ायरवॉल: यदि आपने
Bind IPको0.0.0.0कर दिया है (ताकि LAN के अन्य डिवाइस भी पहुंच सकें), तो macOS फ़ायरवॉल में Ollama के उपयोग किए गए पोर्ट (11434) के लिए इनकमिंग कनेक्शन अनुमति दें।
संक्षिप्त सारांश
ServBay में Ollama को शामिल करने से macOS पर लोकल बड़े भाषा मॉडल को तैनात एवं प्रबंधित करना बेहद आसान हो गया है। सरल ग्राफिकल इंटरफ़ेस के जरिए सेवा शुरू करना, सेटिंग्स बदलना, मॉडल डाउनलोड करना और स्थानीय AI एप्लिकेशन डिवेलपमेंट अत्यंत सुगम होता है, जिससे ServBay एक पूर्ण और शक्तिशाली लोकल डेवेलपमेंट माहौल सिद्ध होता है।
