
Utilisation d’Ollama dans ServBay
ServBay intègre de puissantes capacités d’IA locales à votre environnement de développement, permettant d’exécuter facilement divers modèles de langage open-source (LLM) via Ollama sur macOS. Ce guide vous explique comment activer, configurer et gérer Ollama ainsi que ses modèles dans ServBay, et comment démarrer rapidement.
Présentation
Ollama est un outil populaire qui simplifie le téléchargement, l’installation et l'exécution locale de grands modèles de langage. Intégré dans ServBay en tant que package autonome, Ollama dispose d’une interface graphique intuitive qui permet aux développeurs de :
- Lancer, arrêter et redémarrer le service Ollama en un clic.
- Configurer tous les paramètres d’Ollama via une interface graphique.
- Explorer, télécharger et gérer les modèles LLM compatibles.
- Développer, tester et expérimenter vos applications IA localement, sans dépendre du cloud.
Prérequis
- ServBay doit être installé et en cours d’exécution sur votre macOS.
Activer et gérer le service Ollama
La gestion du package Ollama s’effectue très facilement depuis l’interface principale de ServBay.
Accéder au package Ollama :
- Ouvrez l’application ServBay.
- Dans la barre latérale gauche, cliquez sur
Packages. - Dans la liste déroulante, trouvez puis cliquez sur la catégorie
AI. - Cliquez sur
Ollama.
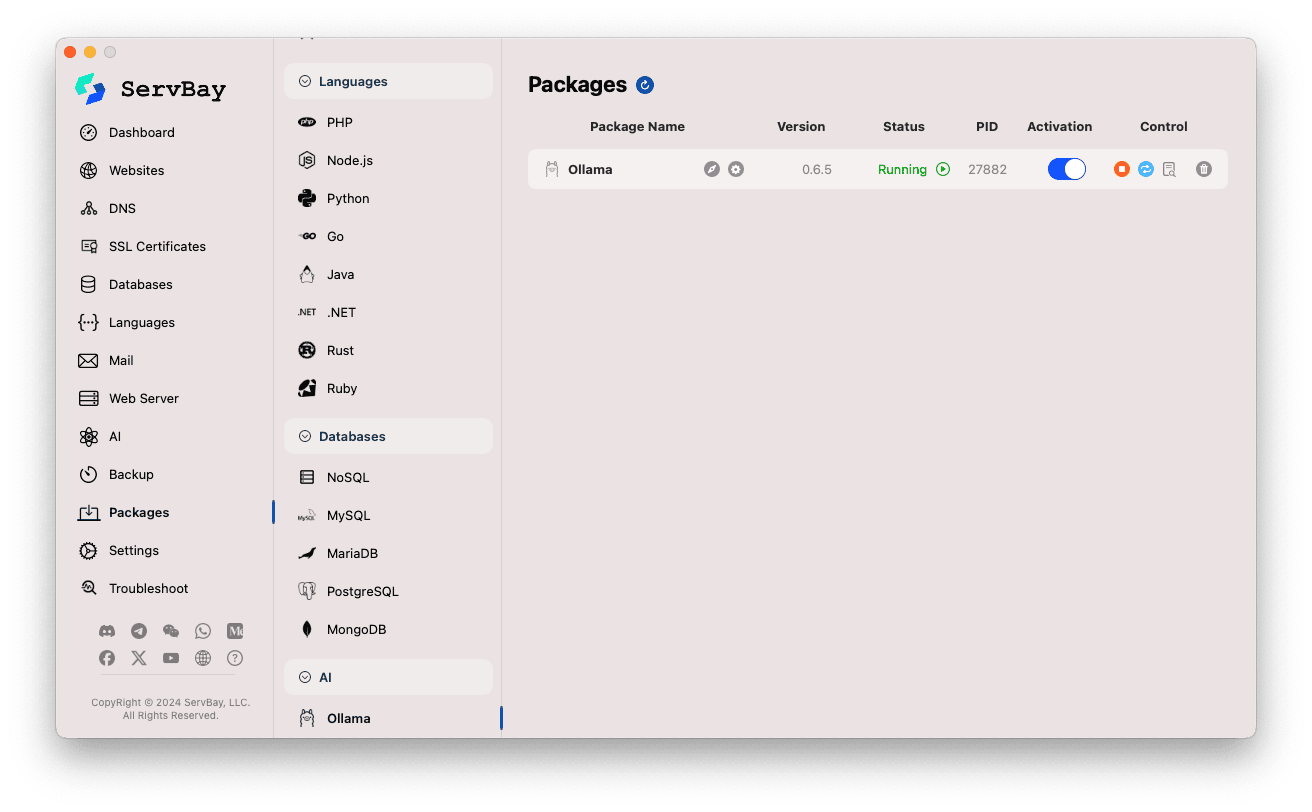
Gérer le service Ollama :
- Dans la zone à droite, vous verrez le statut du package Ollama, y compris la version (ex :
0.6.5), l’état du service (RunningouStopped), et l’identifiant de processus (PID). - Utilisez les boutons de commande à droite :
- Démarrer/Arrêter : le bouton orange permet de lancer ou d’arrêter le service Ollama.
- Redémarrer : bouton bleu pour redémarrer Ollama.
- Configurer : bouton roue dentée jaune pour accéder à la page de configuration.
- Supprimer : bouton corbeille rouge pour désinstaller le package Ollama (attention).
- Plus d’informations : bouton gris pour accéder à des infos supplémentaires ou aux journaux.
- Dans la zone à droite, vous verrez le statut du package Ollama, y compris la version (ex :
Configurer Ollama
ServBay propose une interface graphique pour ajuster les paramètres de fonctionnement d’Ollama selon vos besoins.
Accéder à la page de configuration :
- Ouvrez ServBay.
- Dans la barre latérale, cliquez sur
AI. - Dans la liste déroulante, sélectionnez la catégorie
Paramètres (Settings). - Cliquez sur
Ollama.
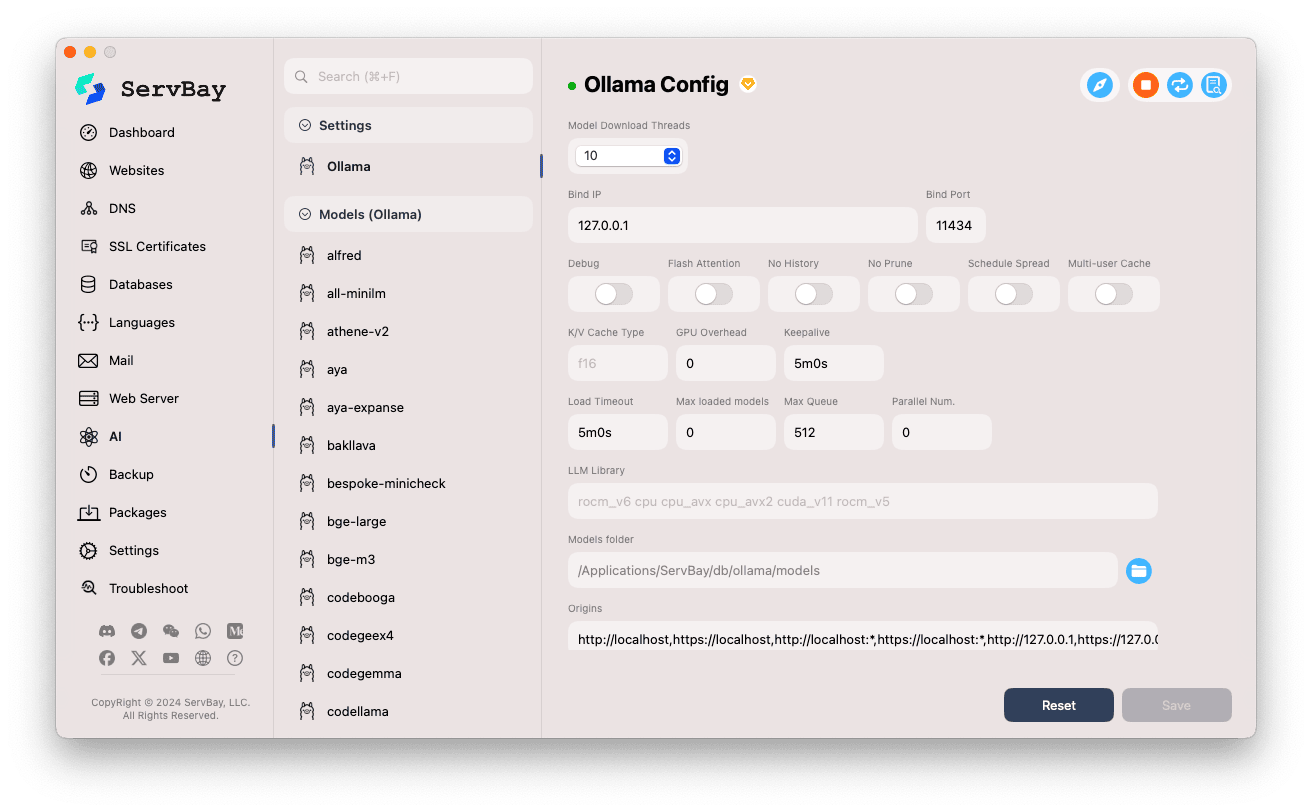
Modifier les paramètres :
- Model Download Threads : nombre de threads utilisés pour télécharger des modèles simultanément, accélérant le processus.
- Bind IP : adresse IP d’écoute d’Ollama. Par défaut
127.0.0.1(accès uniquement local). - Bind Port : port d’écoute d’Ollama, par défaut
11434. - Interrupteurs booléens :
Debug: active le mode débogage.Flash Attention: active l’optimisation Flash Attention (si matériel compatible).No History: empêche la sauvegarde de l’historique des sessions.No Prune: désactive le nettoyage automatique des modèles inutilisés.Schedule Spread: relatif à la stratégie d’ordonnancement.Multi-user Cache: options de cache multi-utilisateurs.
- K/V Cache Type : type de cache clé/valeur, impactant la performance et l’utilisation mémoire.
- Paramètres GPU :
GPU Overhead: configuration de la charge GPU.Keepalive: durée de maintien du GPU actif.
- Chargement & file d’attente de modèles :
Load Timeout: délai d’attente maximal pour le chargement d’un modèle.Max loaded models: nombre maximal de modèles simultanément en mémoire.Max Queue: longueur maximale de la file d’attente des requêtes.Parallel Num.: nombre de requêtes traitées en parallèle.
- LLM Library : chemin de la bibliothèque LLM utilisée.
- Dossier des modèles : dossier local où Ollama télécharge les modèles. Par défaut :
/Applications/ServBay/db/ollama/models. Cliquez sur l’icône dossier pour ouvrir cet emplacement dans le Finder. - origins : configure les sources autorisées à accéder à l’API Ollama (paramètre CORS). Par défaut : adresses locales courantes (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1, etc.). Si vous souhaitez accéder à l’API depuis une application web sur un autre domaine, ajoutez-le ici.
Sauvegarder la configuration : Après modification, cliquez sur le bouton
Saveen bas à droite pour appliquer vos changements.
Gérer les modèles Ollama
La gestion et le téléchargement des modèles via Ollama sont simplifiés avec ServBay.
Accéder à la gestion des modèles :
- Ouvrez ServBay.
- Dans la barre latérale, cliquez sur
AI. - Dans la liste, choisissez
Models (Ollama).
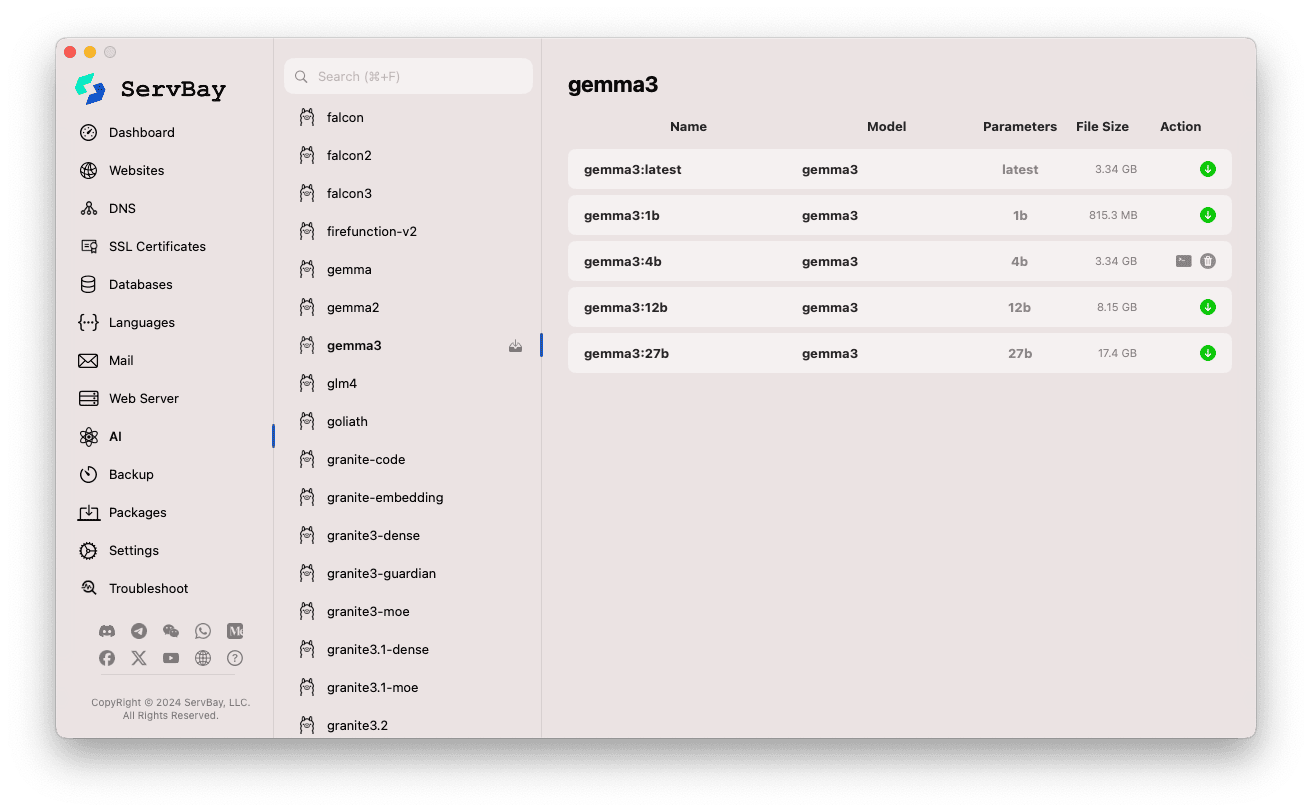
Explorer et télécharger des modèles :
- À gauche s’affichent différentes librairies de modèles compatibles avec Ollama (
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistral, etc.). Cliquez sur un nom de bibliothèque, par exemplegemma3. - À droite, les variantes ou versions de chaque modèle s’affichent (ex :
latest,1b,4b,12b,27bselon la taille des paramètres). - Chaque ligne liste le nom du modèle, le modèle de base, le nombre de paramètres, la taille du fichier.
- Cliquez sur la flèche verte à l’extrémité droite pour démarrer le téléchargement du modèle choisi. Le progrès s’affiche dans l’interface. Vous pouvez accélérer ce processus en augmentant le nombre de threads depuis les paramètres.
- Une fois le modèle téléchargé, le bouton de téléchargement devient grisé ou désactivé.
- À gauche s’affichent différentes librairies de modèles compatibles avec Ollama (
Gérer les modèles téléchargés :
- Les modèles localement présents sont clairement indiqués (bouton gris ou option de suppression disponible).
- Cliquez sur l’icône corbeille à côté d’un modèle pour le supprimer et libérer de l’espace disque.
Utiliser l’API Ollama
Après le lancement, Ollama expose une API REST sur l’IP et le port configurés (par défaut 127.0.0.1:11434). Vous pouvez interagir avec les modèles via n’importe quel client HTTP (comme curl, Postman ou des librairies de programmation).
TIP
ServBay propose un domaine sécurisé avec SSL/TLS : https://ollama.servbay.host
Vous pouvez utiliser https://ollama.servbay.host pour accéder à l’API Ollama au lieu d’utiliser l’adresse IP et le port.
Exemple : Interagir avec le modèle gemma3:latest téléchargé via curl
Assurez-vous d’avoir téléchargé le modèle gemma3:latest avec ServBay et que le service Ollama fonctionne.
bash
# Utilisation du domaine https fourni par ServBay
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# Ou la méthode classique via IP:port
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'Explication de la commande :
http://127.0.0.1:11434/api/generate: endpoint API de génération de texte d’Ollama.-d '{...}': envoie une requête POST avec un corps JSON."model": "gemma3:latest": nom du modèle utilisé (doit être téléchargé)."prompt": "Why is the sky blue?": question ou prompt transmis au modèle."stream": false: àfalse, attendre la réponse complète ; àtrue, réponse retournée progressivement (mode streaming).
Résultat attendu :
Le terminal affiche une réponse JSON, avec le champ response qui contient la réponse du modèle à "Why is the sky blue?".
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... autres métadonnées
}Attention CORS : Si vous accédez à l’API Ollama depuis du JavaScript côté navigateur, assurez-vous que l’origine de votre application web (par exemple http://myapp.servbay.demo) est bien ajoutée dans la liste origins de la configuration Ollama, sinon le navigateur bloquera la requête pour raison de politique CORS.
Cas d’usage
Exécuter Ollama en local dans ServBay offre de nombreux avantages :
- Développement IA local : développez et testez vos applications LLM sans dépendances cloud ou API externes.
- Prototypage rapide : essayez immédiatement différents modèles open-source pour vos idées.
- Utilisation hors-ligne : interagissez avec des LLM même sans connexion internet.
- Confidentialité : toutes les données restent localement sur votre machine, zéro fuite vers des tiers.
- Économies : pas de coûts liés à des services IA en cloud facturés à l’usage.
Points d’attention
- Espace disque : les fichiers de modèles LLM sont volumineux (souvent de plusieurs Go à plusieurs dizaines de Go), prévoyez l’espace nécessaire. Les modèles sont stockés par défaut dans
/Applications/ServBay/db/ollama/models. - Ressources système : faire tourner un LLM requiert beaucoup de CPU et de RAM ; si votre Mac dispose d’un GPU compatible, Ollama peut également accélerer les calculs via le GPU, consommant de la ressource graphique. Vérifiez que votre Mac est adapté à la taille de modèle voulue.
- Temps de téléchargement : dépend de la taille du modèle et de votre débit internet.
- Pare-feu : si vous configurez
Bind IPsur0.0.0.0pour autoriser l’accès depuis d’autres appareils du réseau local, ouvrez le port (11434) dans le pare-feu macOS.
Résumé
L’intégration d’Ollama dans ServBay simplifie grandement le déploiement et la gestion locale des grands modèles de langage sur macOS. Grâce à une interface graphique intuitive, il suffit de quelques clics pour démarrer un service, ajuster la configuration, télécharger un modèle et commencer le développement IA local, renforçant ainsi la valeur de ServBay comme plateforme tout-en-un de développement local.
