
Verwendung von Ollama in ServBay
ServBay integriert leistungsstarke lokale KI-Funktionen in Ihre Entwicklungsumgebung und ermöglicht es Ihnen, mit Ollama verschiedene Open-Source-LLMs (Large Language Models) direkt auf macOS auszuführen. In dieser Anleitung erfahren Sie, wie Sie Ollama in ServBay aktivieren, konfigurieren, verwalten und mit den passenden Modellen direkt loslegen.
Übersicht
Ollama ist ein populäres Tool, das das Herunterladen, Einrichten und Ausführen großer Sprachmodelle auf Ihrem eigenen Rechner stark vereinfacht. ServBay bietet Ollama als eigenständiges Paket mit grafischer Oberfläche an. So können Entwickler:innen ganz bequem:
- Ollama mit einem Klick starten, stoppen oder neustarten
- Ollama-Einstellungen direkt im Frontend konfigurieren
- Unterstützte LLM-Modelle durchsuchen, herunterladen und verwalten
- KI-Anwendungen lokal entwickeln, testen und experimentieren – komplett unabhängig von Cloud-Diensten
Voraussetzungen
- ServBay ist auf Ihrem macOS-System installiert und läuft bereits.
Ollama-Service in ServBay aktivieren und verwalten
Ollama lässt sich komfortabel über die Hauptoberfläche von ServBay steuern.
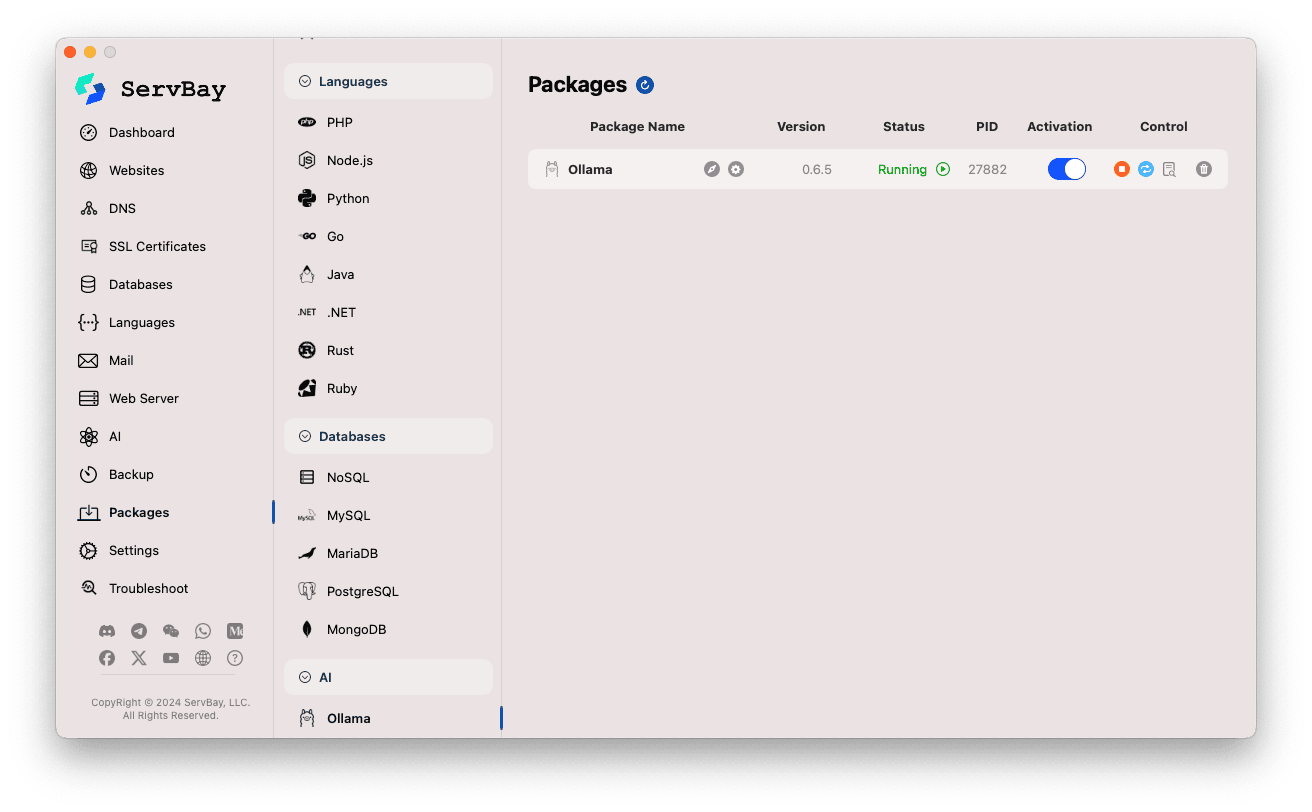
Ollama-Paket aufrufen:
- Öffnen Sie die ServBay-App.
- Klicken Sie im linken Navigationsmenü auf
Pakete(Packages). - Unter den aufgeklappten Optionen wählen Sie den Bereich
AI. - Klicken Sie dort auf
Ollama.
Ollama-Service verwalten:
- Auf der rechten Seite sehen Sie Statusinformationen des Ollama-Pakets, darunter Versionsnummer (z.B.
0.6.5), aktuellen Status (RunningoderStopped), und Prozess-ID (PID). - Nutzen Sie die Bedienfelder auf der rechten Seite:
- Starten/Stoppen: Der orange runde Button startet oder stoppt Ollama.
- Neustart: Der blaue Button mit dem Refresh-Symbol startet Ollama neu.
- Konfiguration: Der gelbe Button mit Zahnrad führt Sie zu den Ollama-Einstellungen.
- Entfernen: Roter Papierkorb zur Deinstallation von Ollama (bitte vorsichtig anwenden).
- Weitere Infos: Der graue Infobutton gewährt zusätzliche Informationen oder Logzugriff.
- Auf der rechten Seite sehen Sie Statusinformationen des Ollama-Pakets, darunter Versionsnummer (z.B.
Ollama konfigurieren
ServBay bietet ein übersichtliches Interface zur Anpassung der Ollama-Laufeinstellungen für unterschiedlichste Anforderungen.
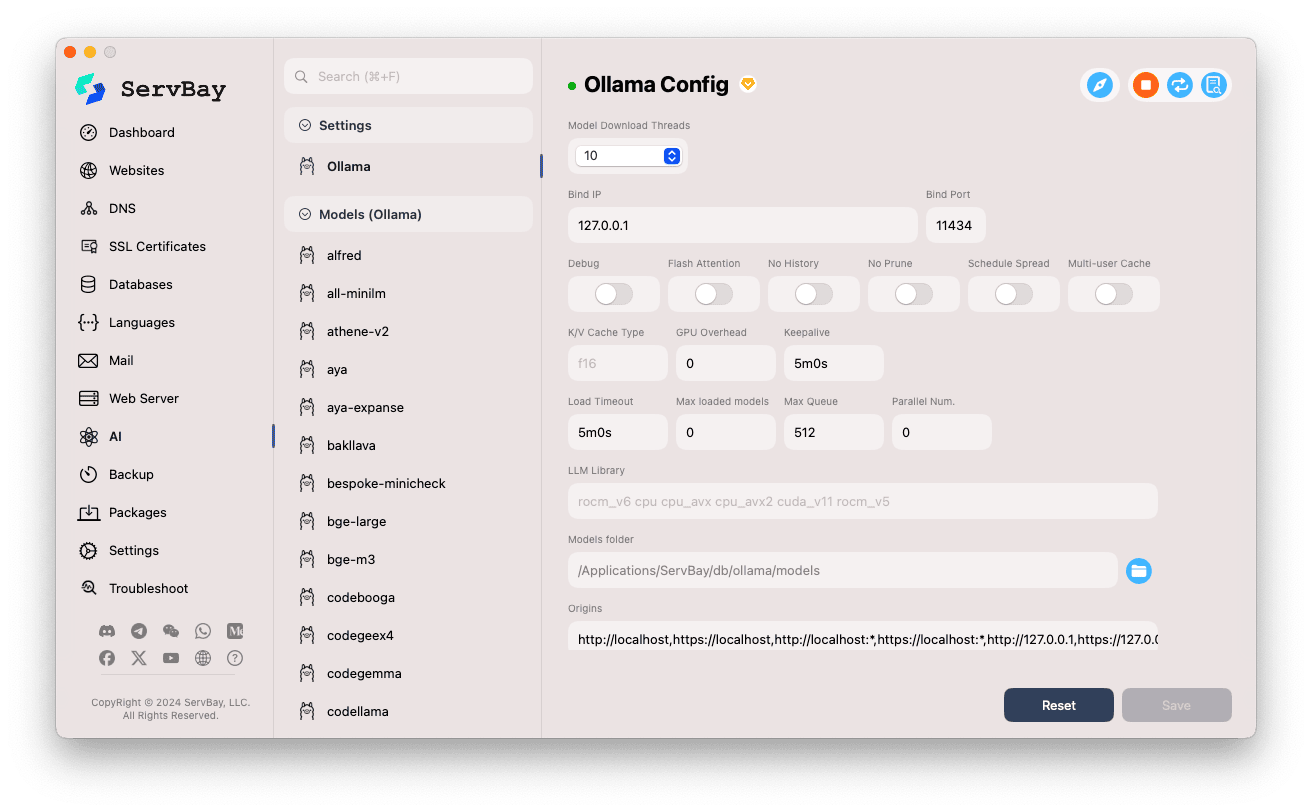
Einstellungen aufrufen:
- Öffnen Sie die ServBay-App.
- Navigieren Sie links zu
AI. - Unter den aufgeklappten Optionen klicken Sie auf
Einstellungen (Settings). - Klicken Sie anschließend auf
Ollama.
Konfiguration anpassen:
- Model Download Threads: Anzahl der gleichzeitigen Download-Threads für Modelle – erhöht die Download-Geschwindigkeit.
- Bind IP: Die IP-Adresse, auf der der Ollama-Service lauscht. Standard ist
127.0.0.1(nur lokal erreichbar). - Bind Port: Der Port, auf dem der Ollama-Service verfügbar ist. Standardwert ist
11434. - Boolesche Schalter:
Debug: Aktiviert den Debug-Modus.Flash Attention: Aktiviert ggf. Flash Attention Optimierung (Hardware-Abhängigkeit).No History: Verhindert das Speichern von Session-Historie.No Prune: Deaktiviert das automatische Entfernen ungenutzter Modelle.Schedule Spread: Einstellungen für Scheduling-Strategien.Multi-user Cache: Optionen für Mehrbenutzer-Caching.
- K/V Cache Type: Key/Value-Cache-Typ, beeinflusst Leistung und RAM-Nutzung.
- GPU-bezogene Einstellungen:
GPU Overhead: Verwaltung der GPU-Resourcen.Keepalive: Zeitspanne, wie lange die GPU aktiv bleibt.
- Modell-Ladung & Warteschlange:
Load Timeout: Zeitlimit für das Laden von Modellen.Max loaded models: Maximale Anzahl gleichzeitig geladener Modelle im Speicher.Max Queue: Maximale Länge für Anfragewarteschlangen.Parallel Num.: Maximale Anzahl paralleler Anfragen.
- LLM Library: Pfad zur verwendeten LLM-Bibliothek.
- Models folder: Lokales Verzeichnis, in dem Ollama Modelle speichert (Standard:
/Applications/ServBay/db/ollama/models). Klicken Sie auf das Ordnersymbol, um diesen Ordner im Finder zu öffnen. - origins: Konfigurieren Sie Quellen, die auf die Ollama-API zugreifen dürfen (CORS). Standardmäßig sind gängige Adressen wie (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1etc.) freigeschaltet. Für den Zugriff Ihrer Webanwendungen von anderen Domains fügen Sie bitte die entsprechende Adresse hinzu.
Einstellungen speichern: Nach Änderungen klicken Sie unten rechts auf den
Save-Button, um die Konfiguration zu übernehmen.
Ollama-Modelle verwalten
ServBay macht das Entdecken, Herunterladen und Verwalten von Ollama-Modellen kinderleicht.
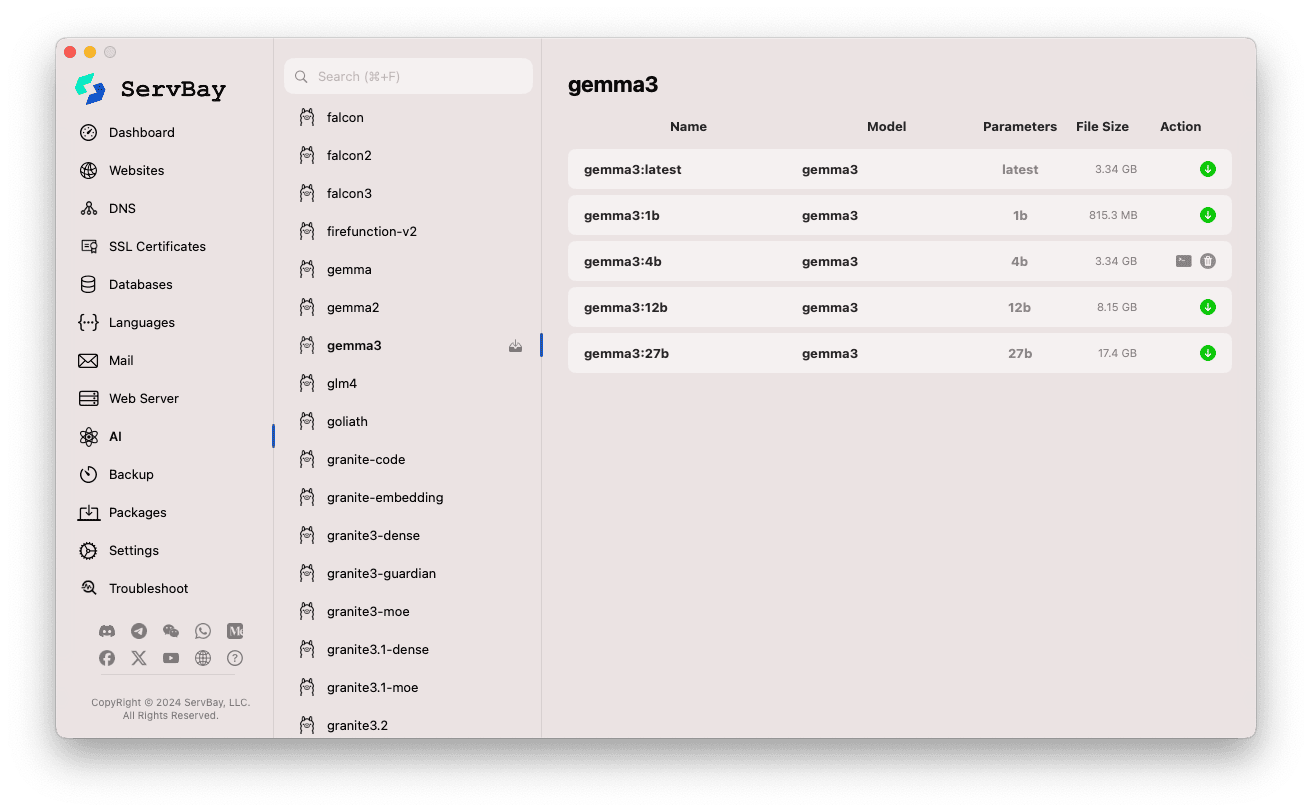
Modellverwaltung öffnen:
- Starten Sie die ServBay-App.
- Navigieren Sie zur linken Leiste auf
AI. - Wählen Sie unter den eingeblendeten Kategorien
Models (Ollama).
Modelle durchsuchen und herunterladen:
- Links finden Sie zahlreiche Modell-Repositories, die mit Ollama kompatibel sind (z.B.
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistralusw.). Klicken Sie auf eine Modellbibliothek (z.B.gemma3). - Rechts erscheinen die jeweiligen Varianten oder Versionen – meist nach Parameteranzahl wie
latest,1b,4b,12b,27busw. - Jede Zeile enthält Modellname, Basismodell, Parameteranzahl und Dateigröße.
- Über den grünen Download-Pfeil rechts starten Sie den Download des gewünschten Modells. Der Fortschritt ist im Interface sichtbar. Den gleichzeitigen Downloadfluss können Sie unter
Einstellungenanpassen. - Bereits installierte Modelle werden als fertig gekennzeichnet – der Downloadbutton ist dann ausgegraut oder deaktiviert.
- Links finden Sie zahlreiche Modell-Repositories, die mit Ollama kompatibel sind (z.B.
Heruntergeladene Modelle verwalten:
- Downgeloadete Modelle sind deutlich markiert (Ausgrauen, Papierkorb-Symbol).
- Klicken Sie auf den Papierkorb, um das Modell lokal zu entfernen und Speicherplatz freizugeben.
Verwendung der Ollama API
Nachdem Ollama gestartet ist, stellt es auf der eingestellten Bind IP und Bind Port (Standard: 127.0.0.1:11434) einen REST-API-Dienst bereit. Sie können mit jedem HTTP-Tool (z.B. curl, Postman oder einer Programmierbibliothek) auf Ihre heruntergeladenen Modelle zugreifen.
TIP
ServBay bietet komfortabel eine SSL/TLS-gesicherte Domain: https://ollama.servbay.host
Sie können die Ollama-API einfach über diese Domain nutzen, anstatt direkt über IP:Port zuzugreifen.
Beispiel: Mit curl das Modell gemma3:latest ansprechen
Stellen Sie sicher, dass das Modell gemma3:latest bereits über ServBay geladen wurde und Ollama läuft.
bash
# Via HTTPS über ServBay
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# Oder auf klassische Weise via IP:Port
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'Befehlsbeschreibung:
http://127.0.0.1:11434/api/generate: API-Endpunkt für Textgenerierung von Ollama.-d '{...}': POST-Anfrage mit zugehörigem JSON-Body."model": "gemma3:latest": Name des zu nutzenden Modells (muss vorhanden sein)."prompt": "Why is the sky blue?": Ihre Frage/Eingabe an das Modell."stream": false:falsebedeutet, das komplette Resultat wird am Stück geliefert; beitrueerfolgt eine gestreamte Token-Ausgabe.
Erwartete Ausgabe:
Sie erhalten eine JSON-Antwort im Terminal. Das Feld response enthält die Antwort des Modells auf "Why is the sky blue?".
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... weitere Metadaten
}CORS-Hinweis: Möchten Sie von JavaScript-Code im Browser aus auf die Ollama-API zugreifen, achten Sie darauf, Ihre Web-App-URL (z.B. http://myapp.servbay.demo) in der Ollama-Konfiguration unter origins freizugeben. Andernfalls blockiert der Browser CORS-bedingt die Anfrage.
Anwendungsszenarien
Das lokale Ausführen von Ollama in ServBay bietet zahlreiche Vorteile:
- Lokale KI-Entwicklung: Entwickeln und testen Sie LLM-basierte Anwendungen direkt auf Ihrem Rechner, unabhängig von externen APIs oder der Cloud.
- Schnelle Prototyp-Entwicklung: Verschiedene Open-Source-Modelle ohne Aufwand ausprobieren und Ideen schnell validieren.
- Offline-Verfügbarkeit: Nutzen Sie LLM auch ohne Internetverbindung.
- Datenschutz: Sämtliche Daten und Interaktionen verbleiben auf Ihrer lokalen Maschine – Datenübertragung an Dritte entfällt.
- Kosteneffizienz: Sparen Sie sich nutzungsabhängige Cloud-KI-Gebühren.
Hinweise
- Speicherplatz: LLM-Dateien sind oft sehr groß (mehrere bis dutzende GB). Stellen Sie sicher, dass genug Speicherplatz auf Ihrer Festplatte liegt. Standard-Speicherort:
/Applications/ServBay/db/ollama/models. - Systemressourcen: Das Ausführen von LLMs ist ressourcenintensiv (CPU, RAM). Falls Ihr Mac eine kompatible GPU besitzt, kann Ollama diese zur Beschleunigung nutzen – dies beansprucht auch GPU-Ressourcen. Prüfen Sie, ob Ihre Hardwareausstattung ausreichend ist.
- Downloadzeiten: Der Download von Modellen dauert – abhängig von Ihrer Internetgeschwindigkeit und Modellgröße.
- Firewall: Wenn Sie die
Bind IPauf0.0.0.0setzen, um im LAN erreichbar zu sein, stellen Sie sicher, dass Ihre macOS-Firewall eingehende Verbindungen zum Ollama-Port (11434) erlaubt.
Fazit
Mit der Ollama-Integration vereinfacht ServBay das Einrichten, Verwalten und Verwenden lokaler LLMs auf macOS erheblich. Die komfortable grafische Oberfläche ermöglicht Entwickler:innen einen unkomplizierten Einstieg – von der Service-Steuerung über flexible Konfiguration und Modell-Download bis hin zur lokalen KI-App-Entwicklung und -Erprobung. Damit stärkt ServBay seinen Wert als umfassende All-in-One-Plattform für die lokale Entwicklung.
