
Usando Ollama no ServBay
O ServBay integra poderosas capacidades de IA local ao seu ambiente de desenvolvimento, permitindo que você execute facilmente diversos modelos de linguagem de código aberto (LLMs) no macOS com Ollama. Este documento orienta como ativar, configurar, gerenciar o Ollama e seus modelos no ServBay, e começar a utilizá-los.
Visão Geral
Ollama é uma ferramenta popular que simplifica os processos de download, configuração e execução de modelos de linguagem de grande porte diretamente em seu computador. O ServBay integra o Ollama como um pacote independente, oferecendo uma interface gráfica de gerenciamento para que os desenvolvedores possam:
- Iniciar, parar e reiniciar o serviço Ollama com um clique.
- Configurar parâmetros do Ollama através da interface gráfica.
- Navegar, baixar e gerenciar os modelos LLM suportados.
- Desenvolver, testar e experimentar aplicações de IA local sem depender de serviços em nuvem.
Pré-requisitos
- Tenha o ServBay instalado e funcionando no seu sistema macOS.
Ativando e Gerenciando o Serviço Ollama
Você pode gerenciar o pacote Ollama facilmente pela interface principal do ServBay.
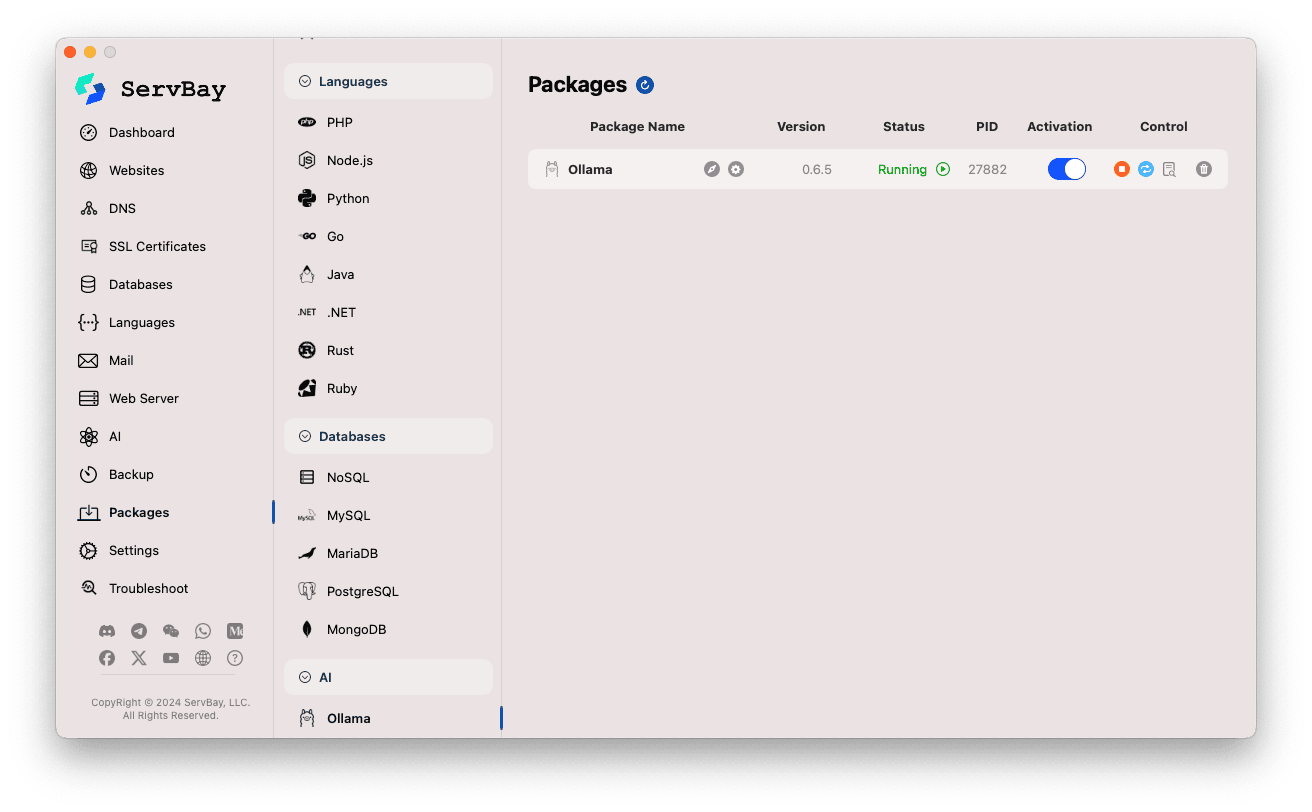
Acessando o pacote Ollama:
- Abra o aplicativo ServBay.
- No menu de navegação à esquerda, clique em
Pacotes(Packages). - Na lista expandida, localize e clique em
AI. - Clique em
Ollama.
Gerenciando o serviço Ollama:
- À direita, você verá informações do status do pacote Ollama, incluindo número da versão (por exemplo,
0.6.5), estado do serviço (RunningouStopped), e o ID do processo (PID). - Utilize os botões de controle no lado direito:
- Iniciar/Parar: O botão circular laranja inicia ou para o serviço Ollama.
- Reiniciar: O botão de atualização azul reinicia o serviço.
- Configurar: O botão de engrenagem amarelo leva à página de configurações do Ollama.
- Remover: O ícone de lixeira vermelho desinstala o pacote Ollama (use com cautela).
- Mais Informações: O botão de informações cinza pode fornecer informações adicionais ou acesso a logs.
- À direita, você verá informações do status do pacote Ollama, incluindo número da versão (por exemplo,
Configurando o Ollama
O ServBay oferece uma interface gráfica para ajustar os parâmetros de execução do Ollama conforme suas necessidades.
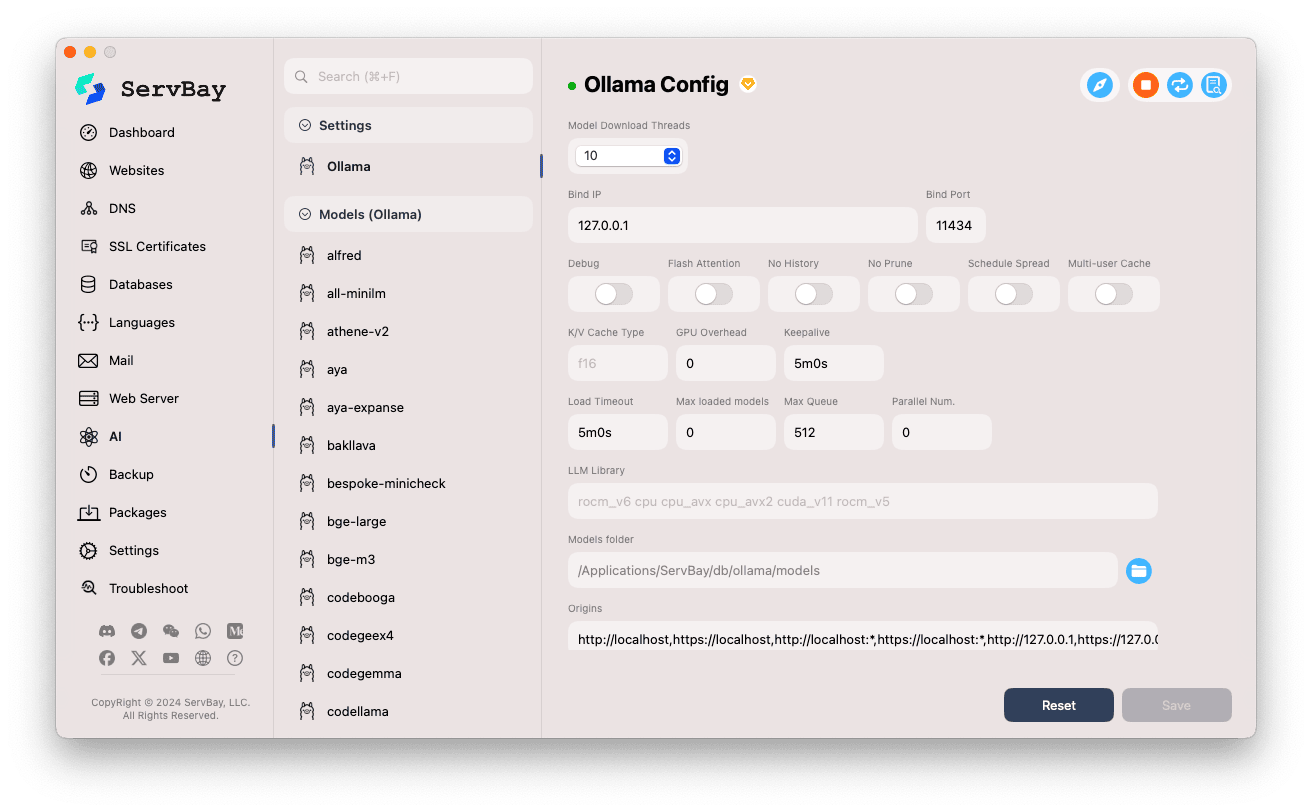
Acessando a interface de configuração:
- Abra o aplicativo ServBay.
- No menu à esquerda, clique em
AI. - Na lista expandida, clique em
Configurações (Settings). - Clique em
Ollama.
Ajustando as configurações:
- Model Download Threads: Define o número de threads para download simultâneo de modelos, acelerando o processo.
- Bind IP: Endereço IP que o Ollama irá escutar. O padrão é
127.0.0.1, permitindo acesso apenas local. - Bind Port: Porta utilizada pelo serviço Ollama. O padrão é
11434. - Opções booleanas:
Debug: Ativa o modo de depuração.Flash Attention: Possibilita a otimização Flash Attention (dependendo do hardware).No History: Impede o registro do histórico de sessões.No Prune: Desativa a limpeza automática de modelos não utilizados.Schedule Spread: Relacionado à estratégia de agendamento.Multi-user Cache: Relacionado ao cache multiusuário.
- K/V Cache Type: Tipo de cache Key/Value utilizado, impactando desempenho e uso de memória.
- Configurações de GPU:
GPU Overhead: Ajuste do overhead de GPU.Keepalive: Tempo de manutenção da GPU ativa.
- Carregamento de modelos e fila:
Load Timeout: Tempo limite para carregamento de modelos.Max loaded models: Número máximo de modelos carregados simultaneamente na memória.Max Queue: Tamanho máximo da fila de requisições.Parallel Num.: Número de requisições processadas em paralelo.
- LLM Library: Caminho da biblioteca LLM subjacente.
- Models folder: Diretório local para download e armazenamento dos modelos do Ollama. Por padrão é
/Applications/ServBay/db/ollama/models. Você pode clicar no ícone de pasta para abrir este diretório no Finder. - origins: Define as origens autorizadas a acessar a API do Ollama (configuração CORS). Os endereços locais mais comuns já vêm incluídos (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1, etc.). Adicione outros domínios conforme necessário para permitir acesso via web apps externos.
Salvando as configurações: Após modificar os parâmetros, clique em
Salvarno canto inferior direito para aplicar as alterações.
Gerenciando Modelos do Ollama
O ServBay facilita o processo de descoberta, download e gerenciamento de modelos do Ollama.
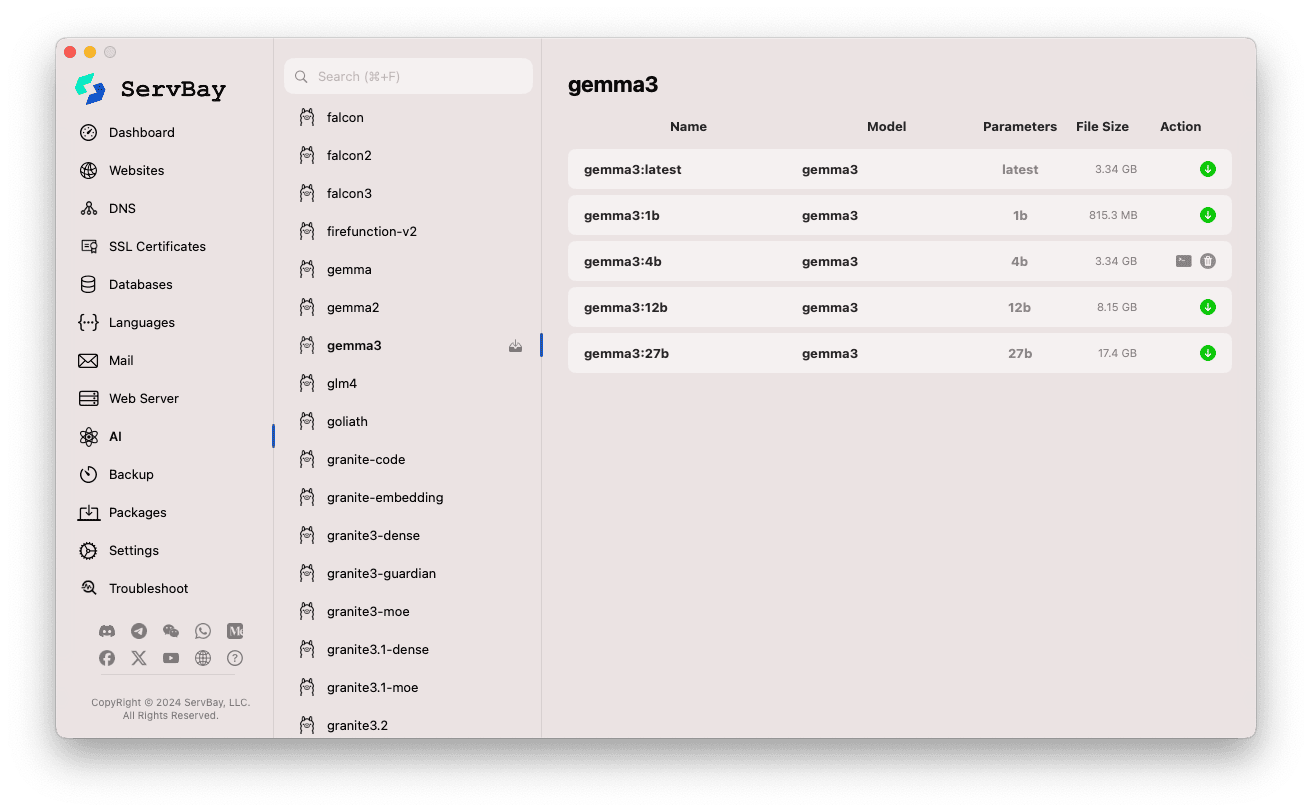
Acessando a gestão de modelos:
- Abra o aplicativo ServBay.
- No menu à esquerda, clique em
AI. - Na lista expandida, selecione
Models (Ollama).
Navegando e baixando modelos:
- À esquerda, você encontrará diversos repositórios de modelos compatíveis com o Ollama (como
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistraletc.). Clique no nome de um repositório, por exemplo,gemma3. - O lado direito apresentará as diferentes variantes ou versões disponíveis, geralmente diferenciadas pelo tamanho do parâmetro (como
latest,1b,4b,12b,27b). - Para cada modelo, serão exibidos nome, modelo base, número de parâmetros e tamanho do arquivo.
- Clique na seta verde à direita para iniciar o download do modelo escolhido. O progresso será exibido na interface. Para acelerar o processo, aumente o número de threads de download nas
Configurações. - Modelos já baixados terão o botão de download desativado ou cinza.
- À esquerda, você encontrará diversos repositórios de modelos compatíveis com o Ollama (como
Gerenciando modelos baixados:
- Os modelos já disponíveis localmente serão devidamente indicados na lista (por exemplo, botão cinza ou ícone de lixeira).
- Clique no ícone de lixeira correspondente para remover modelos e liberar espaço em disco.
Usando a API do Ollama
Após ser iniciado, o Ollama disponibiliza uma API REST no IP e porta configurados (127.0.0.1:11434 por padrão). Você pode interagir com os modelos baixados usando qualquer cliente HTTP (como curl, Postman ou bibliotecas de programação).
TIP
O ServBay gentilmente fornece um domínio com SSL/TLS para acesso HTTPS: https://ollama.servbay.host
Você pode acessar a API do Ollama por meio desse domínio, em vez de usar diretamente IP:porta.
Exemplo: interagindo com o modelo gemma3:latest via curl
Certifique-se de já ter baixado o modelo gemma3:latest pelo ServBay, e que o serviço Ollama esteja em execução.
bash
# Usando o https fornecido pelo ServBay
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# Ou utilizando IP:porta tradicional
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'Explicação dos comandos:
http://127.0.0.1:11434/api/generate: Endpoint da API de geração de texto do Ollama.-d '{...}': Envia um POST com dados JSON."model": "gemma3:latest": Nome do modelo a ser usado (deve estar baixado)."prompt": "Why is the sky blue?": Pergunta ou prompt a ser enviado ao modelo."stream": false: Com valorfalseaguarda a resposta completa do modelo de uma só vez; comtrue, a API retorna os tokens gerados em streaming.
Saída esperada:
Você verá uma resposta JSON no terminal, cujo campo response conterá a resposta do modelo para "Why is the sky blue?".
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... outros metadados
}Atenção ao CORS: Se for acessar a API do Ollama via JavaScript no navegador, adicione o domínio da web app (por exemplo, http://myapp.servbay.demo) à lista de origins nas configurações do Ollama, para evitar bloqueios por política CORS.
Cenários de Uso
Rodar o Ollama localmente no ServBay proporciona diversas vantagens:
- Desenvolvimento de IA local: Desenvolva e teste aplicações baseadas em LLM sem depender de APIs externas ou da nuvem.
- Prototipagem rápida: Experimente rapidamente diferentes modelos de código aberto e valide ideias.
- Uso offline: Interaja com LLMs mesmo sem conexão com a internet.
- Privacidade de dados: Todos os dados e interações permanecem no seu computador, sem risco de envio para terceiros.
- Custo-benefício: Elimina custos com serviços de IA na nuvem por demanda.
Observações
- Espaço em disco: Modelos de linguagem grandes costumam ter vários GBs — até dezenas de GB. Garanta espaço suficiente; o padrão de armazenamento é
/Applications/ServBay/db/ollama/models. - Recursos do sistema: Rodar LLMs exige bastante CPU e RAM. Se seu Mac possui GPU compatível, o Ollama pode utilizá-la para acelerar o processamento, aumentando também o uso desse recurso. Tenha certeza de que a configuração do seu Mac atende aos modelos desejados.
- Tempo de download: O tempo para baixar um modelo depende da velocidade da internet e do tamanho do arquivo.
- Firewall: Se alterar o
Bind IPpara0.0.0.0(permitindo acesso por outros dispositivos na rede), assegure que o firewall do macOS está liberando conexões para a porta utilizada (11434).
Resumo
Ao integrar o Ollama, o ServBay simplifica de forma notável o processo de implantação e gestão de modelos de linguagem de grande porte no macOS. Com uma interface gráfica intuitiva, desenvolvedores podem iniciar serviços, ajustar configurações, baixar modelos e rapidamente começar a criar e experimentar aplicações de IA local, ampliando o valor do ServBay como ambiente completo de desenvolvimento local.
