
Utilizzare Ollama in ServBay
ServBay integra potenti funzionalità AI locali nel tuo ambiente di sviluppo, consentendoti di eseguire con facilità una varietà di modelli linguistici open source di grandi dimensioni (LLM) su macOS tramite Ollama. Questa guida ti spiegherà come abilitare, configurare e gestire Ollama e i suoi modelli in ServBay, nonché come iniziare a utilizzarli.
Panoramica
Ollama è uno strumento molto diffuso che semplifica il processo di download, configurazione ed esecuzione di modelli linguistici di grandi dimensioni direttamente sul tuo computer. ServBay integra Ollama come pacchetto indipendente, offrendo un'interfaccia grafica che permette agli sviluppatori di:
- Avviare, arrestare e riavviare il servizio Ollama con un solo clic.
- Configurare tutti i parametri di Ollama attraverso l'interfaccia grafica.
- Sfogliare, scaricare e gestire i modelli LLM supportati.
- Sviluppare, testare ed effettuare esperimenti AI localmente, senza la dipendenza da servizi cloud.
Prerequisiti
- ServBay deve essere installato e in esecuzione sul tuo sistema macOS.
Abilitare e gestire il servizio Ollama
Puoi gestire facilmente il pacchetto Ollama tramite l'interfaccia principale di ServBay.
Accedere al pacchetto Ollama:
- Apri l'applicazione ServBay.
- Nella barra di navigazione a sinistra, clicca su
Pacchetti(Packages). - Nell'elenco che si espande, trova e seleziona la categoria
AI. - Clicca su
Ollama.
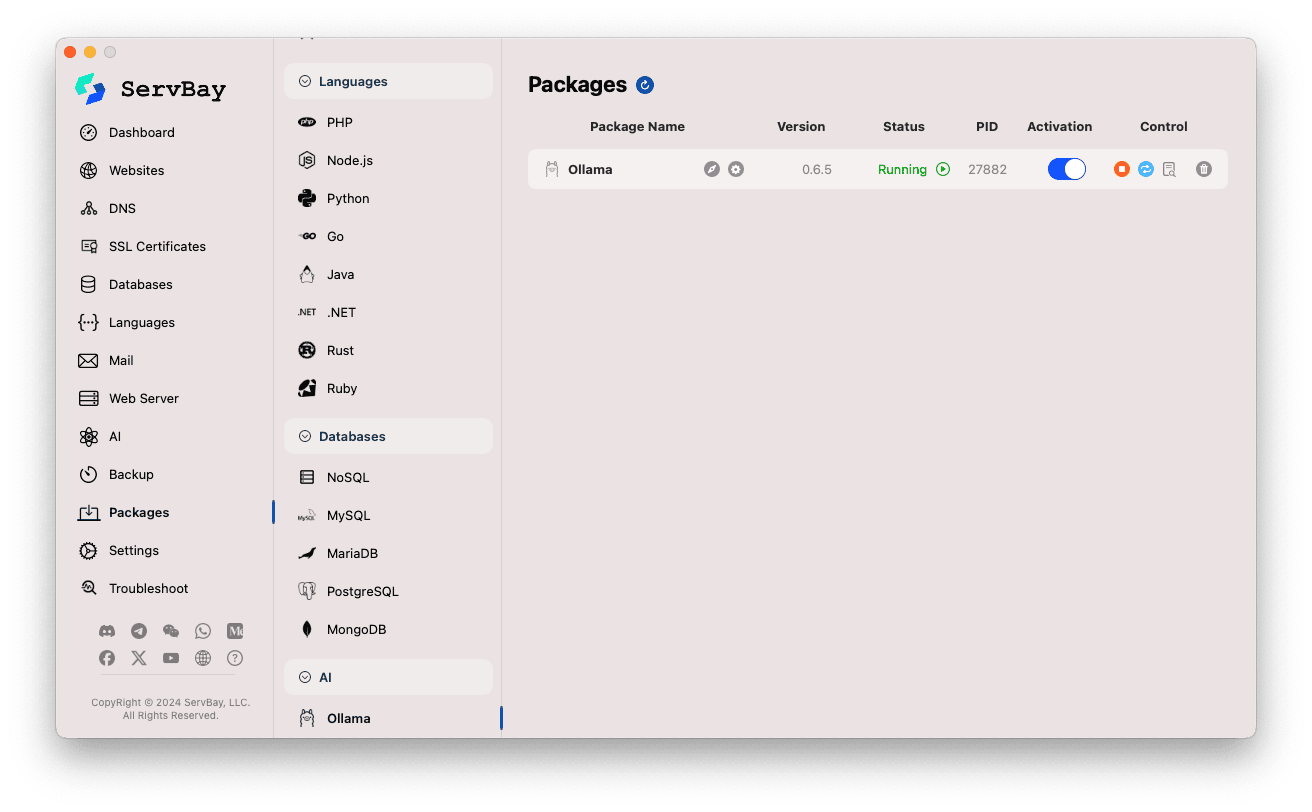
Gestire il servizio Ollama:
- Nell'area destra, vedrai le informazioni di stato del pacchetto Ollama, incluso il numero di versione (ad esempio
0.6.5), lo stato d'esecuzione (RunningoStopped), e l'ID processo (PID). - Usa i tasti di controllo a destra:
- Avvia/Arresta: Il pulsante arancione rotondo serve per avviare o arrestare Ollama.
- Riavvia: Il pulsante blu a forma di refresh serve per riavviare Ollama.
- Configura: Il pulsante giallo a forma di ingranaggio conduce alla pagina di configurazione di Ollama.
- Elimina: Il pulsante rosso a forma di cestino permette di disinstallare il pacchetto Ollama (operare con cautela).
- Più informazioni: Il pulsante grigio informazioni può offrire dati aggiuntivi o accesso ai log.
- Nell'area destra, vedrai le informazioni di stato del pacchetto Ollama, incluso il numero di versione (ad esempio
Configurare Ollama
ServBay offre una pratica interfaccia grafica per modificare i parametri di Ollama e adattarlo alle varie esigenze.
Accedere alla pagina di configurazione:
- Apri l'applicazione ServBay.
- Nella barra di navigazione a sinistra, seleziona
AI. - Nell'elenco espanso, trova la categoria
Impostazioni (Settings)e cliccala. - Seleziona
Ollama.
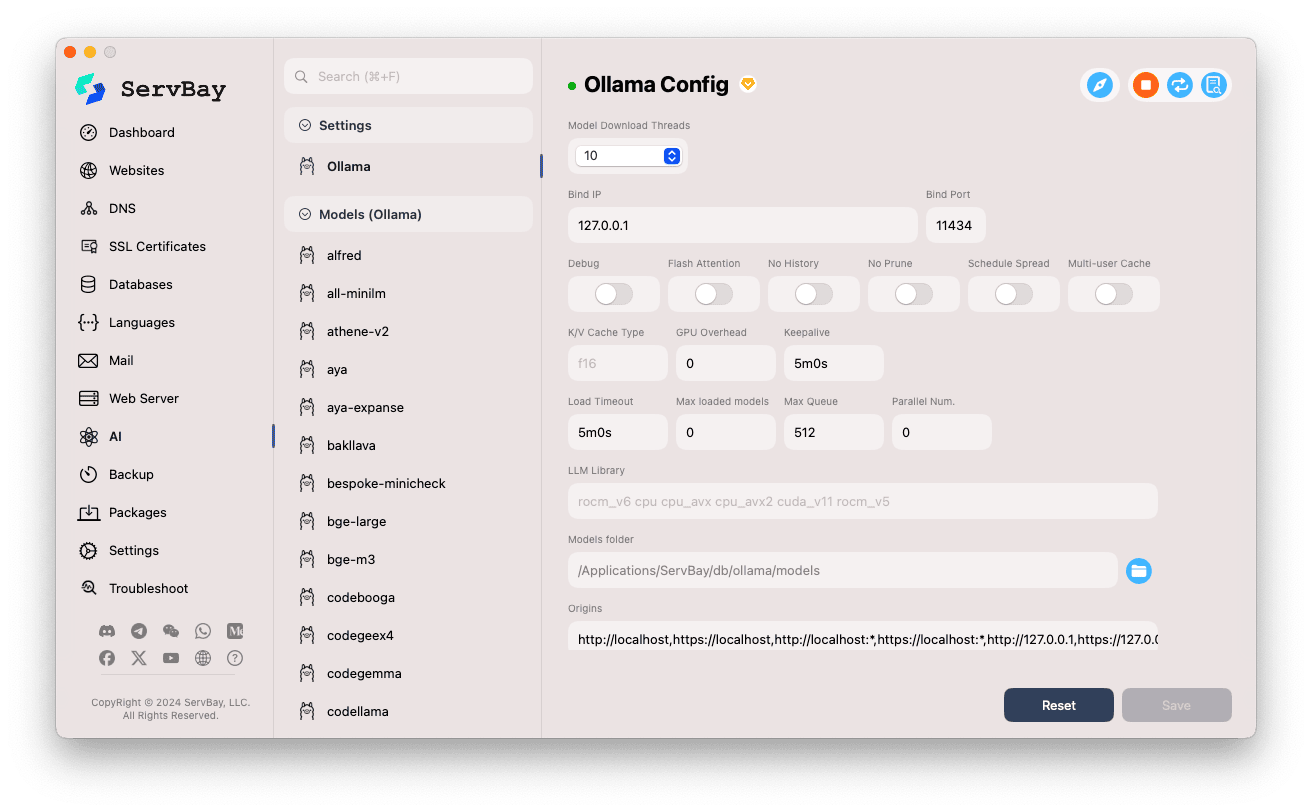
Regolare le opzioni di configurazione:
- Model Download Threads: Imposta il numero di thread per il download simultaneo dei modelli, utile per aumentare la velocità di scaricamento.
- Bind IP: L'indirizzo IP su cui Ollama ascolta. Di default è
127.0.0.1, cioè accessibile solo in locale. - Bind Port: La porta di ascolto di Ollama. Default:
11434. - Opzioni a interruttore booleano:
Debug: Attiva la modalità debug.Flash Attention: Abilita (se supportato dall'hardware) l'ottimizzazione Flash Attention.No History: Impedisce la registrazione della cronologia delle sessioni.No Prune: Disabilita la rimozione automatica dei modelli non utilizzati.Schedule Spread: Riguarda le strategie di scheduling.Multi-user Cache: Gestione cache per più utenti.
- K/V Cache Type: Tipo di cache Key/Value, che influenza le performance e l'utilizzo della memoria.
- Opzioni GPU:
GPU Overhead: Configurazione dei carichi sulla GPU.Keepalive: Tempo di mantenimento attivo della GPU.
- Caricamento modelli e coda:
Load Timeout: Timeout per il caricamento dei modelli.Max loaded models: Numero massimo di modelli caricati in RAM contemporaneamente.Max Queue: Lunghezza massima della coda delle richieste.Parallel Num.: Numero di richieste elaborate in parallelo.
- LLM Library: Percorso della libreria LLM di base utilizzata.
- Models folder: Cartella locale in cui Ollama scarica e conserva i modelli. Default:
/Applications/ServBay/db/ollama/models. Clicca sull'icona della cartella per aprire la directory in Finder. - origins: Configura le origini consentite per accedere alle API di Ollama (impostazione CORS). Di default include i tipici indirizzi locali (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1, ecc.). Se desideri accedere da app web su altri domini, aggiungi qui l'origine corrispondente.
Salvare la configurazione: Dopo le modifiche, clicca il pulsante
Savein basso a destra per applicare i cambiamenti.
Gestire i modelli Ollama
ServBay semplifica il processo di esplorazione, download e gestione dei modelli Ollama.
Accedere alla gestione modelli:
- Apri l'applicazione ServBay.
- Seleziona
AInella barra laterale sinistra. - Nell'elenco espanso, clicca su
Models (Ollama).
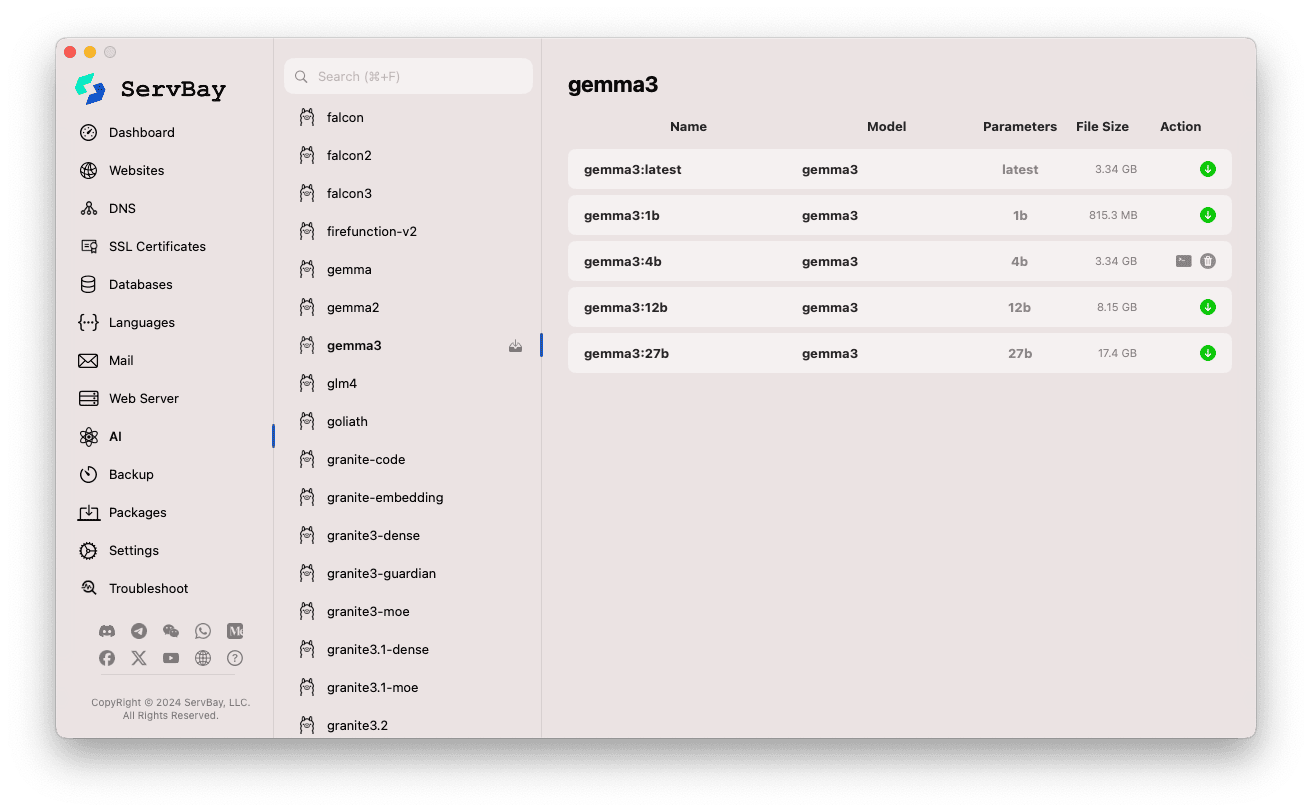
Esplorare e scaricare modelli:
- A sinistra troverai librerie di modelli supportate da Ollama (ad esempio
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistralecc.). Clicca su una di queste, per esempiogemma3. - A destra appariranno le varianti/versioni disponibili della libreria selezionata, di solito distinte per dimensione (ad es.
latest,1b,4b,12b,27b). - Ogni riga indica il nome del modello, il modello di base, il numero di parametri e la dimensione del file.
- Clicca sull’icona verde a forma di freccia sulla destra per iniziare il download del modello desiderato. La barra di avanzamento mostrerà lo stato del download. Puoi aumentare la velocità di scaricamento modificando il numero di thread in
Impostazioni. - I modelli già scaricati avranno il pulsante disabilitato o grigio.
- A sinistra troverai librerie di modelli supportate da Ollama (ad esempio
Gestire i modelli scaricati:
- I modelli scaricati saranno chiaramente segnalati nell'elenco (ad esempio, con il pulsante download disabilitato o la comparsa della funzione di cancellazione).
- Puoi liberare spazio disco cliccando sull’icona del cestino accanto al modello, che rimuove il file dalla memoria locale.
Utilizzo delle API di Ollama
Quando Ollama è attivo, fornisce API REST sull’indirizzo IP e sulla porta configurata (127.0.0.1:11434 per impostazione predefinita). Puoi interagire con i modelli scaricati tramite qualsiasi client HTTP (come curl, Postman o librerie nei tuoi linguaggi di programmazione).
TIP
ServBay mette a disposizione un pratico dominio con crittografia SSL/TLS, accessibile tramite HTTPS: https://ollama.servbay.host.
Puoi utilizzare il dominio https://ollama.servbay.host invece del classico IP:porta per accedere alle API di Ollama.
Esempio: utilizzo di curl con il modello scaricato gemma3:latest
Assicurati di aver scaricato gemma3:latest tramite ServBay e che il servizio Ollama sia in esecuzione.
bash
# Utilizzo dell’https fornito da ServBay
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# In alternativa, puoi usare il classico IP:porta
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'Spiegazione dei comandi:
http://127.0.0.1:11434/api/generate: endpoint API di Ollama per la generazione di testo.-d '{...}': invia una richiesta POST con i dati JSON."model": "gemma3:latest": il nome del modello da utilizzare (deve essere già stato scaricato)."prompt": "Why is the sky blue?": domanda o istruzione per il modello."stream": false: se impostato sufalse, la risposta viene restituita tutta insieme; sutrueviene trasmessa in streaming token per token.
Output atteso:
Nel terminale riceverai una risposta JSON; il campo response contiene la risposta del modello alla domanda "Why is the sky blue?".
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... altri metadati
}Nota CORS: Se desideri accedere alle API di Ollama tramite JavaScript nel browser, assicurati che l'origine (ad esempio http://myapp.servbay.demo) sia stata aggiunta all'elenco origins nella configurazione di Ollama, altrimenti il browser bloccherà la richiesta per motivi di CORS.
Scenari d’uso
Eseguire Ollama localmente in ServBay offre numerosi vantaggi:
- Sviluppo AI locale: Puoi sviluppare e testare facilmente applicazioni basate su LLM, senza dipendere da API esterne o dal cloud.
- Prototipazione rapida: Sperimenta e valida idee provando diversi modelli open source in modo rapido.
- Utilizzo offline: Continua a interagire con gli LLM anche senza connessione Internet.
- Privacy dei dati: Tutti i dati e le interazioni restano sul tuo computer, senza rischi di invio a terzi.
- Risparmio sui costi: Eviti i costi pay-per-use dei servizi AI in cloud.
Avvertenze
- Spazio su disco: I file dei grandi modelli linguistici occupano molto spazio (da vari GB a decine di GB). Assicurati di disporre di sufficiente spazio su disco. Il percorso predefinito di salvataggio è
/Applications/ServBay/db/ollama/models. - Risorse di sistema: L’esecuzione di un LLM richiede molte risorse CPU e RAM. Se possiedi una GPU compatibile sul tuo Mac, Ollama può usarla per l’accelerazione hardware, ma questo utilizza anche la GPU. Assicurati che il tuo Mac sia adatto a gestire il modello che vuoi eseguire.
- Tempo di download: Il download dei modelli può richiedere tempo, in base alla velocità della tua connessione e alla dimensione del modello.
- Firewall: Se imposti
Bind IPsu0.0.0.0per permettere l’accesso da altri dispositivi nella LAN, assicurati che il firewall di macOS consenta connessioni in entrata sulla porta usata da Ollama (11434).
Conclusione
Integrando Ollama, ServBay semplifica enormemente la distribuzione e gestione di modelli linguistici di grandi dimensioni su macOS. Grazie alla sua interfaccia grafica intuitiva, puoi avviare servizi, regolare le impostazioni, scaricare modelli e iniziare a sviluppare ed eseguire applicazioni AI localmente in pochi clic, rafforzando il ruolo di ServBay come ambiente di sviluppo locale all-in-one.
