
Korzystanie z Ollama w ServBay
ServBay integruje potężne możliwości AI działającej lokalnie z Twoim środowiskiem deweloperskim, umożliwiając łatwe uruchamianie różnych otwartoźródłowych dużych modeli językowych (LLM) przez Ollama na macOS. Ten dokument przeprowadzi Cię przez proces aktywacji, konfiguracji i zarządzania Ollama oraz jej modelami w ServBay, a także pokaże, jak zacząć korzystać z tych funkcji.
Przegląd
Ollama to popularne narzędzie upraszczające pobieranie, konfigurację i uruchamianie dużych modeli językowych na komputerze lokalnym. ServBay integruje Ollama jako niezależny pakiet, oferując graficzny interfejs zarządzania, który pozwala programistom na:
- Uruchamianie, zatrzymywanie i restartowanie usługi Ollama jednym kliknięciem.
- Konfigurację parametrów Ollama bezpośrednio z poziomu interfejsu graficznego.
- Przeglądanie, pobieranie i zarządzanie obsługiwanymi modelami LLM.
- Tworzenie, testowanie i eksperymentowanie z aplikacjami AI lokalnie, bez zależności od usług chmurowych.
Wymagania wstępne
- ServBay musi być zainstalowany i uruchomiony na Twoim komputerze z macOS.
Aktywacja i zarządzanie usługą Ollama
Zarządzanie pakietem Ollama jest bardzo proste za pomocą głównego interfejsu ServBay.
Przejdź do pakietu Ollama:
- Otwórz aplikację ServBay.
- W lewym pasku nawigacyjnym kliknij
Pakiety(Packages). - Z rozwijanego menu wybierz kategorię
AI. - Kliknij
Ollama.
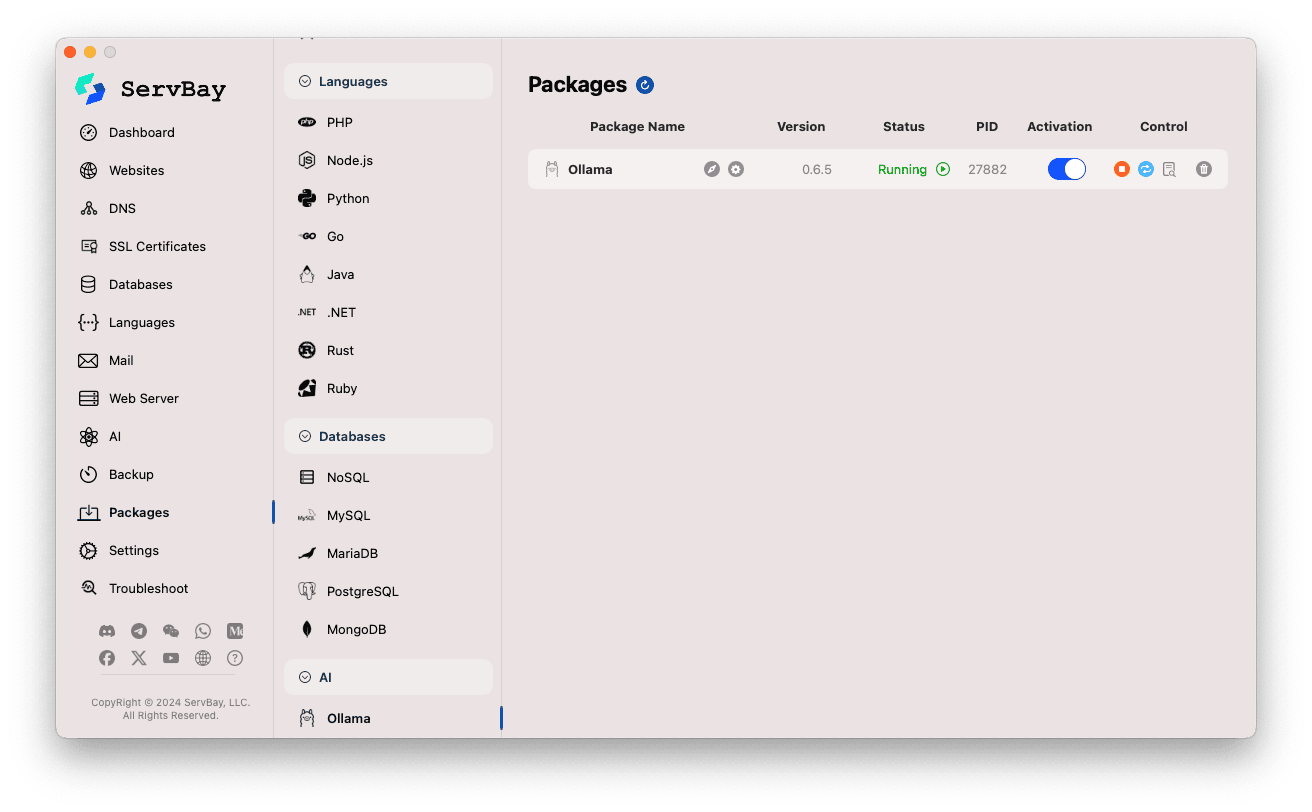
Zarządzanie usługą Ollama:
- Po prawej stronie zobaczysz aktualny status pakietu Ollama, w tym wersję (np.
0.6.5), status działania (RunninglubStopped), identyfikator procesu (PID). - Skorzystaj z przycisków kontrolnych po prawej:
- Uruchom/Zatrzymaj: Pomarańczowy okrągły przycisk służy do uruchamiania lub zatrzymywania usługi Ollama.
- Restartuj: Niebieski przycisk odświeżania umożliwia restart usługi Ollama.
- Konfiguracja: Żółty przycisk z ikoną koła zębatego służy do przejścia do strony konfiguracji Ollama.
- Usuń: Czerwony przycisk z ikoną kosza umożliwia odinstalowanie pakietu Ollama (Uwaga: operacja nieodwracalna).
- Więcej informacji: Szary przycisk informacji może oferować dodatkowe informacje lub dostęp do logów.
- Po prawej stronie zobaczysz aktualny status pakietu Ollama, w tym wersję (np.
Konfiguracja Ollama
ServBay zapewnia graficzny interfejs umożliwiający dostosowanie parametrów działania Ollama do własnych potrzeb.
Przejdź do panelu konfiguracji:
- Otwórz aplikację ServBay.
- W lewym pasku nawigacyjnym kliknij
AI. - Z listy wybierz kategorię
Ustawienia (Settings). - Kliknij
Ollama.
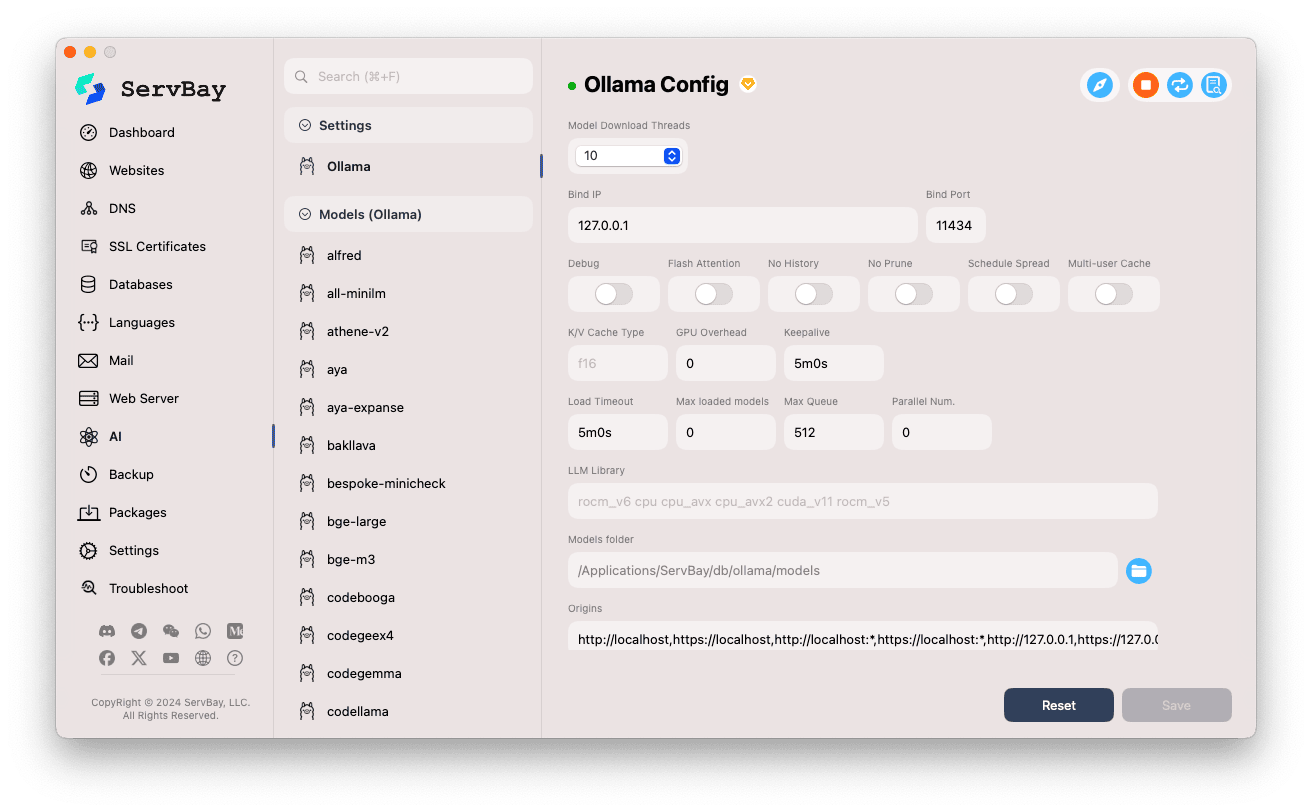
Dostosowywanie ustawień:
- Wątki pobierania modeli (Model Download Threads): Określa liczbę jednoczesnych wątków pobierania modeli, co umożliwia szybsze pobieranie.
- Bind IP: Adres IP, na którym nasłuchuje usługa Ollama. Domyślnie to
127.0.0.1, czyli dostęp wyłącznie lokalny. - Bind Port: Port używany przez usługę Ollama. Domyślnie to
11434. - Przełączniki:
Debug: Aktywuje tryb debugowania.Flash Attention: Może włączyć optymalizację Flash Attention (wymaga wsparcia sprzętowego).No History: Blokuje zapisywanie historii sesji.No Prune: Wyłącza automatyczne czyszczenie nieużywanych modeli.Schedule Spread: Dotyczy strategii harmonogramowania.Multi-user Cache: Tryb współdzielenia pamięci podręcznej przez wielu użytkowników.
- K/V Cache Type: Typ cache (Key/Value), wpływa na wydajność i wykorzystanie pamięci.
- Parametry GPU:
GPU Overhead: Konfiguracja obciążenia GPU.Keepalive: Czas utrzymania aktywnego GPU.
- Ładowanie modeli i kolejka:
Load Timeout: Limit czasu ładowania modelu.Max loaded models: Maksymalna liczba modeli jednocześnie załadowanych do pamięci.Max Queue: Maksymalna długość kolejki żądań.Parallel Num.: Liczba żądań przetwarzanych równolegle.
- LLM Library: Ścieżka do biblioteki wykorzystywanej przez Ollama.
- Models folder: Lokalny katalog pobierania i przechowywania modeli Ollama (domyślnie:
/Applications/ServBay/db/ollama/models). Możesz kliknąć ikonę folderu, by otworzyć katalog w Finderze. - origins: Konfiguracja dozwolonych źródeł (CORS) dla API Ollama. Domyślnie zawiera najczęstsze adresy lokalne (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1itd.). Jeśli chcesz uzyskać dostęp z aplikacji web na innej domenie, dodaj ją do tej listy.
Zapisz zmiany: Po wprowadzeniu zmian kliknij w prawym dolnym rogu przycisk
Zapisz(Save), aby je zastosować.
Zarządzanie modelami Ollama
ServBay upraszcza proces przeglądania, pobierania i zarządzania modelami Ollama.
Wejdź do panelu zarządzania modelami:
- Otwórz aplikację ServBay.
- W lewym pasku nawigacyjnym kliknij
AI. - Z listy wybierz
Models (Ollama).
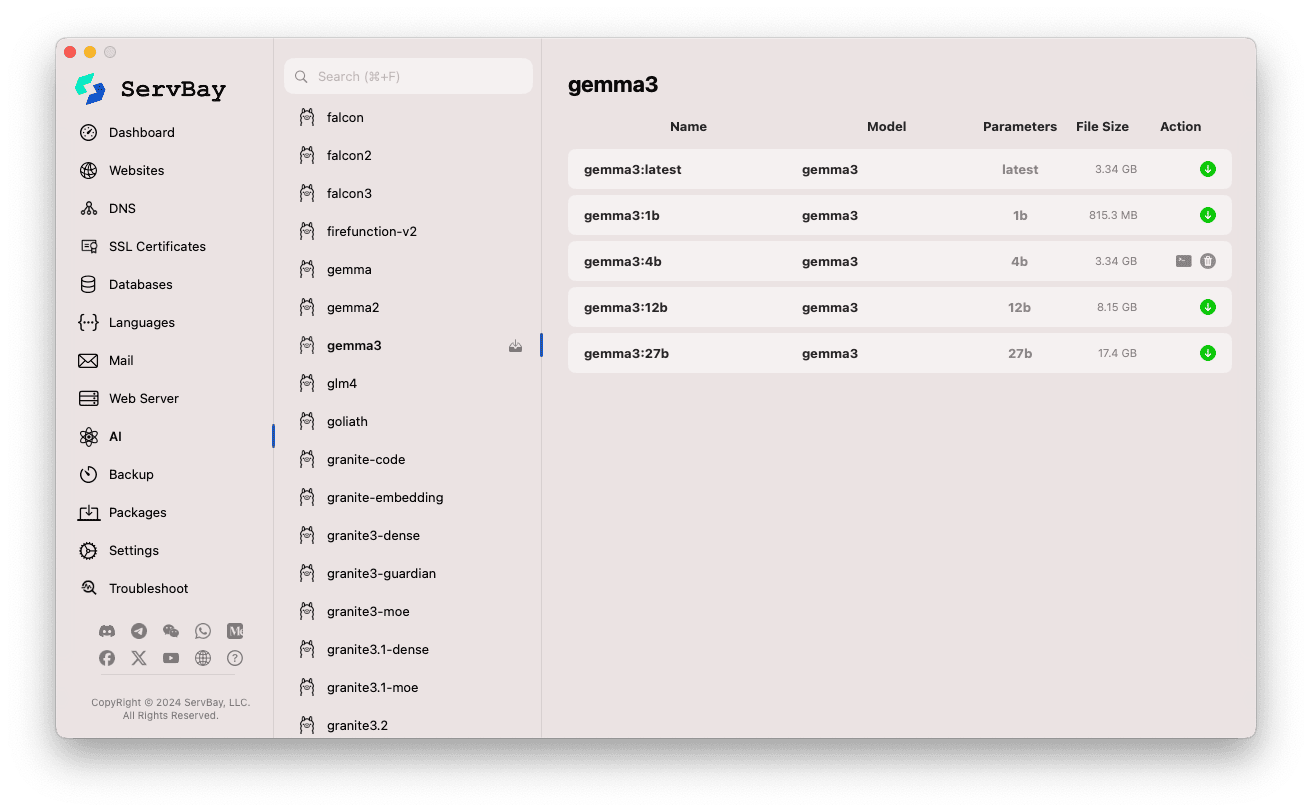
Przeglądanie i pobieranie modeli:
- Po lewej stronie zobaczysz różne biblioteki modeli dostępnych dla Ollama (np.
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistralitd.). Kliknij wybraną bibliotekę (np.gemma3). - Po prawej stronie pojawią się warianty lub wersje danego modelu, zwykle podzielone według liczby parametrów (
latest,1b,4b,12b,27b). - Każdy wiersz zawiera nazwę modelu, bazę, liczbę parametrów i wielkość pliku.
- Kliknij zielony przycisk pobierania po prawej stronie, aby rozpocząć pobieranie wybranego modelu. Progres pobierania zobaczysz na ekranie. Możesz przyspieszyć pobieranie, zwiększając liczbę wątków w
Ustawieniach. - Dla modeli już pobranych przycisk pobierania będzie wyszarzony lub nieaktywny.
- Po lewej stronie zobaczysz różne biblioteki modeli dostępnych dla Ollama (np.
Zarządzanie pobranymi modelami:
- Modele, które zostały pobrane, są wyraźnie oznaczone (np. wyszarzony przycisk pobierania lub ikona usuwania).
- Możesz kliknąć ikonę kosza, aby usunąć wybrany model lokalnie i zwolnić miejsce na dysku.
Korzystanie z API Ollama
Po uruchomieniu, Ollama udostępnia REST API na skonfigurowanym adresie Bind IP i porcie Bind Port (domyślnie 127.0.0.1:11434). Możesz korzystać z dowolnego klienta HTTP (curl, Postman, biblioteki programistyczne) do interakcji z pobranymi modelami.
TIP
ServBay oferuje wygodną nazwę domenową https://ollama.servbay.host, dzięki której możesz korzystać z Ollama przez szyfrowane połączenie HTTPS.
Użytkownicy mogą uzyskać dostęp do API Ollama poprzez https://ollama.servbay.host zamiast tradycyjnego IP:port.
Przykład: Wykorzystanie curl do interakcji z pobranym modelem gemma3:latest
Upewnij się, że pobrałeś model gemma3:latest przez ServBay i usługa Ollama jest uruchomiona.
bash
# Użycie adresu https od ServBay
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# Lub klasycznie przez IP:port
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'Wyjaśnienie poleceń:
http://127.0.0.1:11434/api/generate: Punkt końcowy API do generowania tekstu przez Ollama.-d '{...}': Przesłanie danych POST z JSON-em."model": "gemma3:latest": Określa nazwę modelu (musi być wcześniej pobrany)."prompt": "Why is the sky blue?": Pytanie lub polecenie skierowane do modelu."stream": false: Jeśli ustawisz nafalse, odpowiedź zostanie zwrócona jednorazowo po wygenerowaniu całości. Przytrueodpowiedź będzie zwracana strumieniowo tokenami.
Oczekiwany rezultat:
W terminalu otrzymasz odpowiedź w formacie JSON, gdzie w polu response znajdziesz odpowiedź modelu na pytanie "Why is the sky blue?".
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... inne metadane
}Uwaga dotycząca CORS: Jeśli chcesz uzyskać dostęp do API Ollama z poziomu JavaScript w przeglądarce, upewnij się, że adres źródłowy Twojej aplikacji web (np. http://myapp.servbay.demo) został dodany do listy origins w konfiguracji Ollama, inaczej przeglądarka zablokuje zapytania z powodu CORS.
Przykładowe zastosowania
Lokalne uruchomienie Ollama w ServBay oferuje wiele korzyści:
- Rozwój AI lokalnie: Twórz i testuj aplikacje oparte na LLM bez potrzeby korzystania z zewnętrznych API lub usług chmurowych.
- Szybkie prototypowanie: Błyskawicznie testuj różne otwarte modele, by zweryfikować pomysły.
- Tryb offline: Dostęp do modeli nawet bez połączenia z Internetem.
- Prywatność danych: Wszystkie dane i interakcje pozostają na komputerze, bez przesyłania do podmiotów trzecich.
- Efektywność kosztowa: Unikasz kosztów związanych z usługami AI rozliczanymi w chmurze.
Ważne uwagi
- Miejsce na dysku: Pliki modeli LLM mogą być bardzo duże (od kilku do kilkudziesięciu GB). Upewnij się, że masz wystarczająco wolnego miejsca (domyślnie:
/Applications/ServBay/db/ollama/models). - Zasoby systemowe: Uruchamianie modeli LLM wymaga sporej mocy CPU i RAM. Jeśli Twój Mac ma kompatybilną kartę GPU, Ollama może wykorzystać ją do przyspieszenia działania – zużycie GPU również wzrośnie. Upewnij się, że Twój komputer spełnia wymagania wybranego modelu.
- Czas pobierania: Pobieranie modeli może zająć dużo czasu, w zależności od szybkości łącza oraz wielkości plików.
- Firewall: Jeśli zmienisz
Bind IPna0.0.0.0, umożliwiając innym urządzeniom w sieci LAN dostęp do API Ollama, upewnij się, że firewall macOS zezwala na ruch przychodzący na wybranym porcie (11434).
Podsumowanie
Dzięki integracji z Ollama, ServBay znacząco ułatwia wdrażanie i zarządzanie lokalnymi dużymi modelami językowymi na macOS. Za sprawą intuicyjnego interfejsu graficznego deweloperzy mogą szybko uruchamiać usługi, konfigurować środowisko, pobierać modele i natychmiast użytkować AI lokalnie – co czyni ServBay jeszcze bardziej wartościową, kompleksową platformą do lokalnego rozwoju oprogramowania.
