
Використання Ollama в ServBay
ServBay інтегрує потужні локальні можливості AI у ваше середовище розробки, дозволяючи зручно запускати різноманітні open source великі мовні моделі (LLM) через Ollama на macOS. У цій документації ви знайдете покрокову інструкцію щодо активації, налаштування та управління Ollama і його моделями в ServBay, а також як розпочати роботу.
Загальний огляд
Ollama — популярний інструмент, що спрощує процес завантаження, встановлення та запуску великих мовних моделей безпосередньо на вашому компʼютері. ServBay інтегрує Ollama як окремий пакет з графічним інтерфейсом для зручного керування, завдяки чому розробники можуть:
- Запускати, зупиняти й перезапускати сервіс Ollama одним кліком.
- Налаштовувати параметри Ollama через зручний графічний інтерфейс.
- Переглядати, завантажувати та управляти підтримуваними LLM-моделями.
- Розробляти, тестувати та експериментувати з AI-додатками локально, без необхідності в хмарних сервісах.
Передумови
- ServBay має бути встановлено та запущено на вашій системі macOS.
Активація та керування сервісом Ollama
Керувати пакетом Ollama можна просто через головний інтерфейс ServBay.
Доступ до пакету Ollama:
- Відкрийте застосунок ServBay.
- В лівій навігаційній панелі виберіть
Пакети(Packages). - У випадаючому списку знайдіть і натисніть категорію
AI. - Оберіть
Ollama.
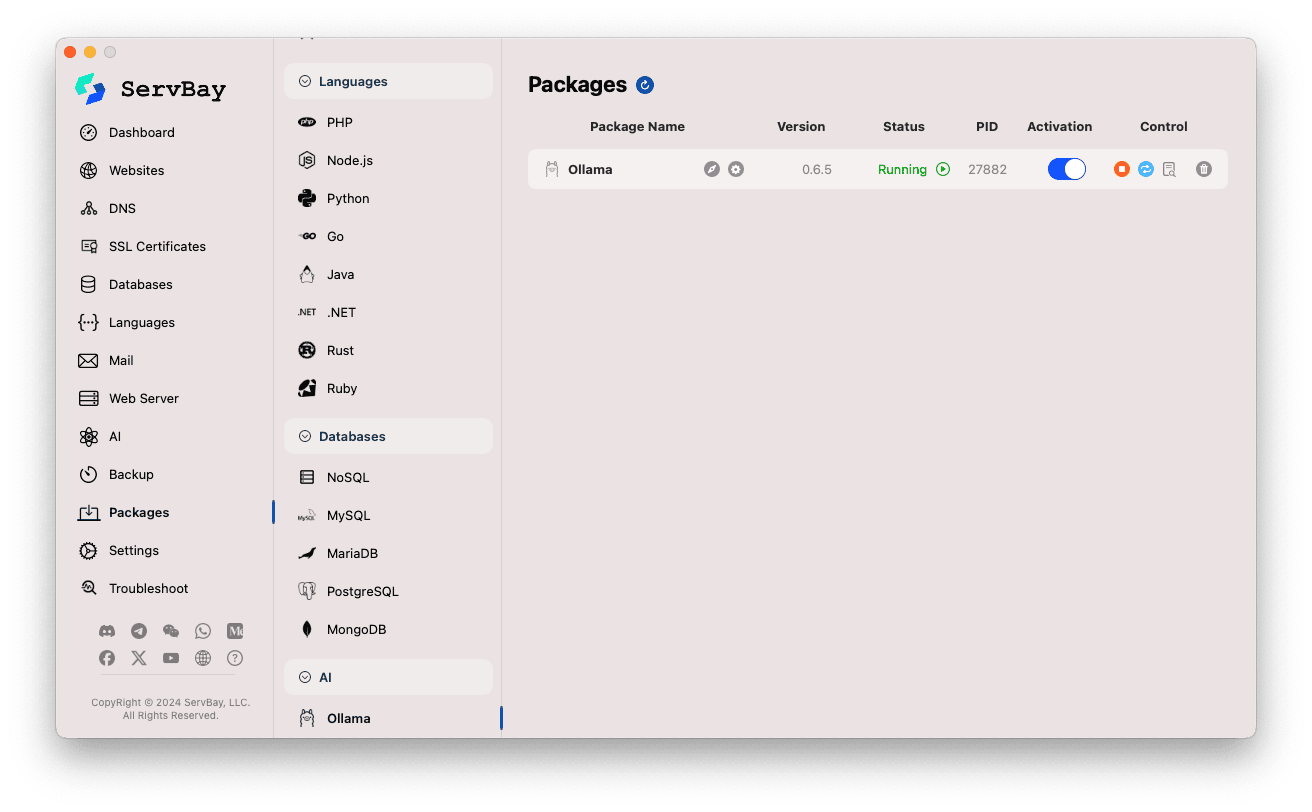
Керування сервісом Ollama:
- У правій частині інтерфейсу відображається статус пакету Ollama, зокрема версія (наприклад,
0.6.5), стан (RunningабоStopped), ідентифікатор процесу (PID). - Використовуйте кнопки керування справа:
- Запуск/Зупинка: Помаранчева кругла кнопка запускає або зупиняє сервіс Ollama.
- Перезапуск: Синя кнопка оновлення перезапускає сервіс.
- Налаштування: Жовта кнопка з шестірнею переходить до сторінки налаштувань Ollama.
- Видалити: Червона кнопка зі смітником видаляє пакет Ollama (застосовуйте обережно).
- Додаткова інформація: Сіра кнопка з інформацією може містити додаткові дані або доступ до журналів.
- У правій частині інтерфейсу відображається статус пакету Ollama, зокрема версія (наприклад,
Налаштування Ollama
ServBay надає зручний інтерфейс для змін параметрів Ollama під ваші потреби.
Перехід до налаштувань:
- Відкрийте застосунок ServBay.
- У лівій панелі виберіть
AI. - У випадаючому списку знайдіть і натисніть категорію
Налаштування (Settings). - Оберіть
Ollama.
Зміна параметрів:
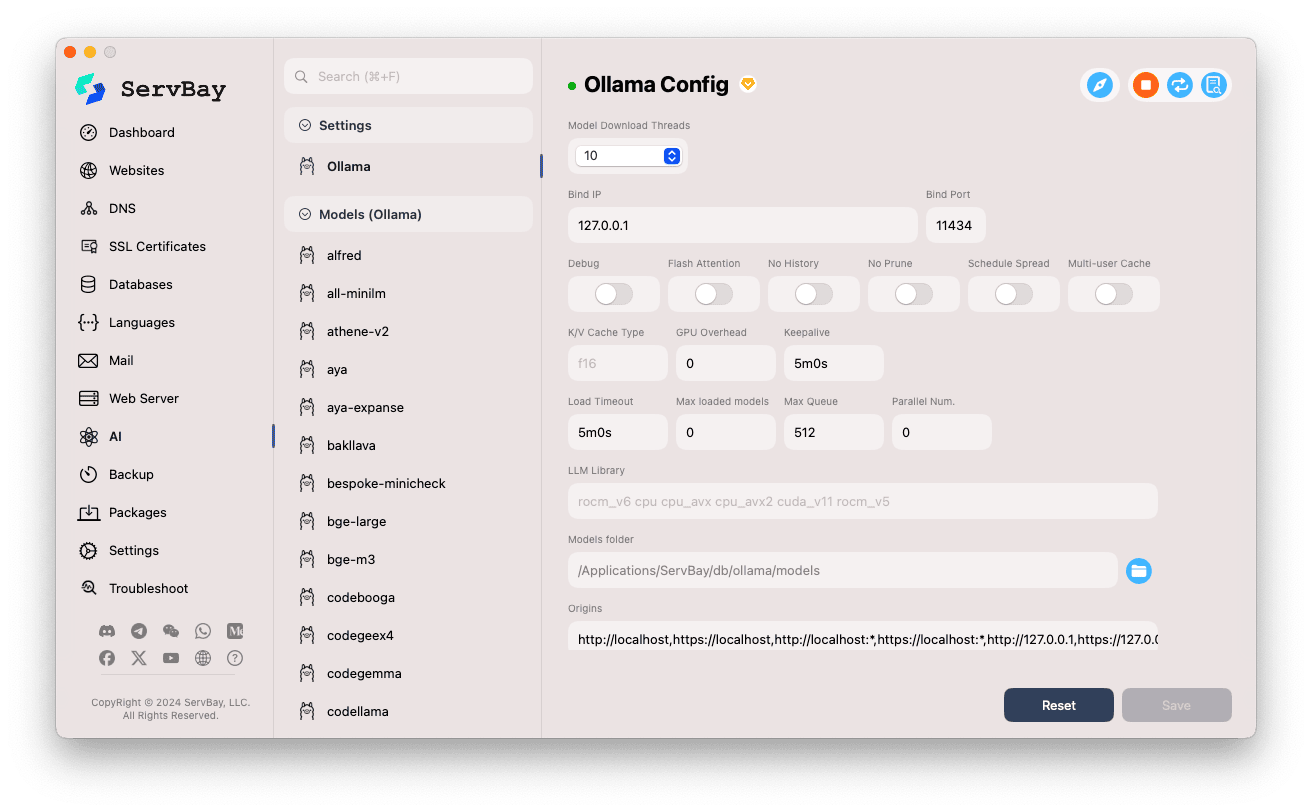
- Model Download Threads: Кількість потоків для одночасного завантаження моделей — пришвидшує завантаження.
- Bind IP: IP-адреса, яку прослуховує Ollama. Типово
127.0.0.1— доступ лише з локального компʼютера. - Bind Port: Порт сервісу Ollama, типово
11434. - Перемикачі:
Debug: Включити режим налагодження.Flash Attention: Може активувати оптимізацію Flash Attention (потребує підтримки обладнанням).No History: Заборонити збереження історії сесій.No Prune: Відключити автоматичне очищення невикористаних моделей.Schedule Spread: Налаштування стратегії розподілу ресурсів.Multi-user Cache: Кешування для декількох користувачів.
- K/V Cache Type: Тип кешу ключ/значення, впливає на продуктивність і споживання памʼяті.
- GPU-параметри:
GPU Overhead: Розподіл навантаження на GPU.Keepalive: Час утримування GPU в активному режимі.
- Завантаження моделей і черга:
Load Timeout: Таймаут завантаження моделі.Max loaded models: Максимальна кількість моделей одночасно в оперативній памʼяті.Max Queue: Максимальна довжина черги запитів.Parallel Num.: Кількість паралельних обробок запитів.
- LLM Library: Шлях до використаної бібліотеки LLM.
- Models folder: Локальна директорія для зберігання моделей — типово
/Applications/ServBay/db/ollama/models. Клацніть на іконку папки, щоб відкрити її у Finder. - origins: Дозволені джерела для доступу до Ollama API (налаштування CORS). Типово включає localhost і подібні адреси (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1тощо). Якщо необхідний доступ з інших доменів — додайте їх тут.
Збереження налаштувань: Після змін натисніть кнопку
Saveу нижньому правому кутку для збереження.
Керування моделями Ollama
ServBay спрощує пошук, завантаження та управління моделями Ollama.
Відкриття менеджера моделей:
- Відкрийте ServBay.
- У лівому меню оберіть
AI. - У розділі, що відкриється, натисніть
Models (Ollama).
Перегляд та завантаження моделей:
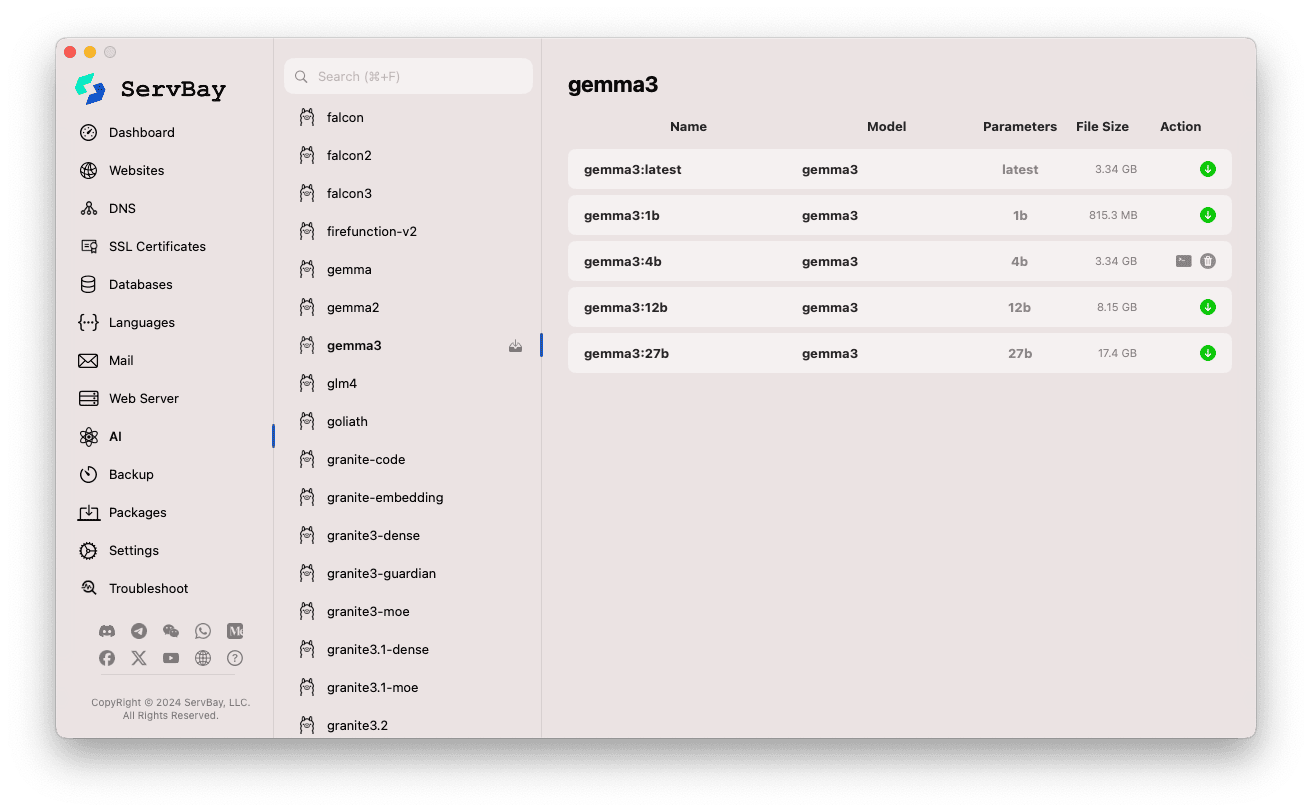
- Ліворуч відображені численні бібліотеки моделей Ollama (наприклад,
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistralта ін.). Клацніть назву моделі, наприклад,gemma3. - Праворуч зʼявляться варіанти цієї моделі (зазвичай відрізняються розміром параметрів —
latest,1b,4b,12b,27b). - У кожному рядку вказані назва моделі, базова модель, кількість параметрів і розмір файлу.
- Щоб завантажити модель, натисніть зелену стрілку завантаження праворуч. Прогрес буде видно у вікні. Для прискорення можна змінити число потоків у розділі
Налаштування. - Для вже завантажених моделей кнопка завантаження стане сірою чи недоступною.
- Ліворуч відображені численні бібліотеки моделей Ollama (наприклад,
Управління завантаженими моделями:
- Завантажені моделі чітко позначені (наприклад, кнопка завантаження стає неактивною або зʼявляється кнопка видалення).
- Ви можете видалити скачану модель, натиснувши іконку смітника — це вивільнить місце на диску.
Використання Ollama API
Після запуску Ollama доступний REST API за налаштованими параметрами Bind IP та Bind Port (типово — 127.0.0.1:11434). Можна використовувати будь-який HTTP-клієнт (наприклад, curl, Postman чи бібліотеки для програмування), щоб взаємодіяти із завантаженою моделлю.
TIP
ServBay пропонує зручний захищений домен для доступу через HTTPS: https://ollama.servbay.host
Користувачі можуть звертатися до Ollama API через домен https://ollama.servbay.host, а не напряму через IP:порт.
Приклад: взаємодія з моделлю gemma3:latest через curl
Переконайтеся, що ви вже завантажили модель gemma3:latest у ServBay та Ollama запущено.
bash
# Використання https від ServBay
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# Або класичний варіант із IP:порт
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'Пояснення команди:
http://127.0.0.1:11434/api/generate: ендпоінт для генерації тексту у Ollama.-d '{...}': POST-запит з даними у форматі JSON."model": "gemma3:latest": яку модель використовувати (має бути завантажена)."prompt": "Why is the sky blue?": ваше питання чи інструкція до моделі."stream": false: відповісти після генерації всього тексту; true — відповідь буде надходити потоково.
Очікуваний результат:
Відповідь у терміналі — JSON, в полі response міститься відповідь моделі на питання "Why is the sky blue?".
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... інші метадані
}Примітка щодо CORS: Якщо ви звертаєтеся до API Ollama з JavaScript у браузері, переконайтеся, що джерело вашого вебдодатку (наприклад, http://myapp.servbay.demo) додано до списку origins у налаштуваннях Ollama, інакше браузер заблокує запит через політику CORS.
Варіанти застосування
Локальний запуск Ollama у ServBay дає чимало переваг:
- Локальна AI-розробка: Жодної залежності від зовнішніх API чи хмарних сервісів — розробка й тестування LLM-додатків напряму на вашому Mac.
- Швидке прототипування: Можливість тестувати різні open source моделі для перевірки концепцій.
- Робота офлайн: Взаємодія з LLM, навіть якщо відсутнє інтернет-зʼєднання.
- Конфіденційність: Усі дані та взаємодії залишаються на локальному компʼютері — не потрібно хвилюватися щодо витоку даних до сторонніх сервісів.
- Економія: Не потрібно сплачувати за хмарні AI-послуги.
Важливі зауваження
- Вільне місце на диску: Файли великих мовних моделей часто значні за розміром (від декількох до десятків гігабайтів). Переконайтеся, що у вас достатньо місця. Типово моделі зберігаються у
/Applications/ServBay/db/ollama/models. - Системні ресурси: Робота LLM суттєво навантажує CPU і оперативну памʼять. Якщо Mac має сумісний GPU, Ollama може його використовувати — це також споживає ресурси відеокарти. Перевірте, чи вистачає ресурсів для обраної моделі.
- Час завантаження моделей: Швидкість залежить від розміру моделі та швидкості інтернету.
- Фаєрвол: Якщо ви змінили
Bind IPна0.0.0.0— тобто дозволили доступ з інших пристроїв у мережі, переконайтесь, що фаєрвол macOS пропускає вхідні зʼєднання на порт Ollama (11434).
Висновок
З інтеграцією Ollama, ServBay значно спрощує розгортання та керування локальними великими мовними моделями на macOS. Інтуїтивний графічний інтерфейс дозволяє запускати сервіси, змінювати налаштування, завантажувати моделі — й миттєво приступати до локальної AI-розробки та експериментів, що підсилює цінність ServBay як універсального середовища розробки.
