
Использование Ollama в ServBay
ServBay интегрирует мощные локальные возможности AI непосредственно в вашу среду разработки, позволяя с легкостью запускать различные открытые языковые модели (LLM) через Ollama на macOS. Этот документ проведет вас через процесс активации, настройки, управления Ollama и его моделями, а также поможет приступить к работе.
Обзор
Ollama — популярный инструмент, который упрощает процесс загрузки, настройки и запуска крупных языковых моделей прямо на вашем компьютере. ServBay включает Ollama как отдельный программный пакет, предоставляя графический интерфейс для управления, что позволяет разработчикам:
- Запускать, останавливать и перезапускать сервис Ollama одним кликом.
- Настраивать параметры Ollama через визуальный интерфейс.
- Просматривать, скачивать и управлять поддерживаемыми моделями LLM.
- Разрабатывать, тестировать и экспериментировать с AI-приложениями на локальной машине без обращения к облачным сервисам.
Предварительные требования
- ServBay установлен и запущен на вашем macOS.
Включение и управление сервисом Ollama
Вы можете легко управлять пакетом Ollama через главный интерфейс ServBay.
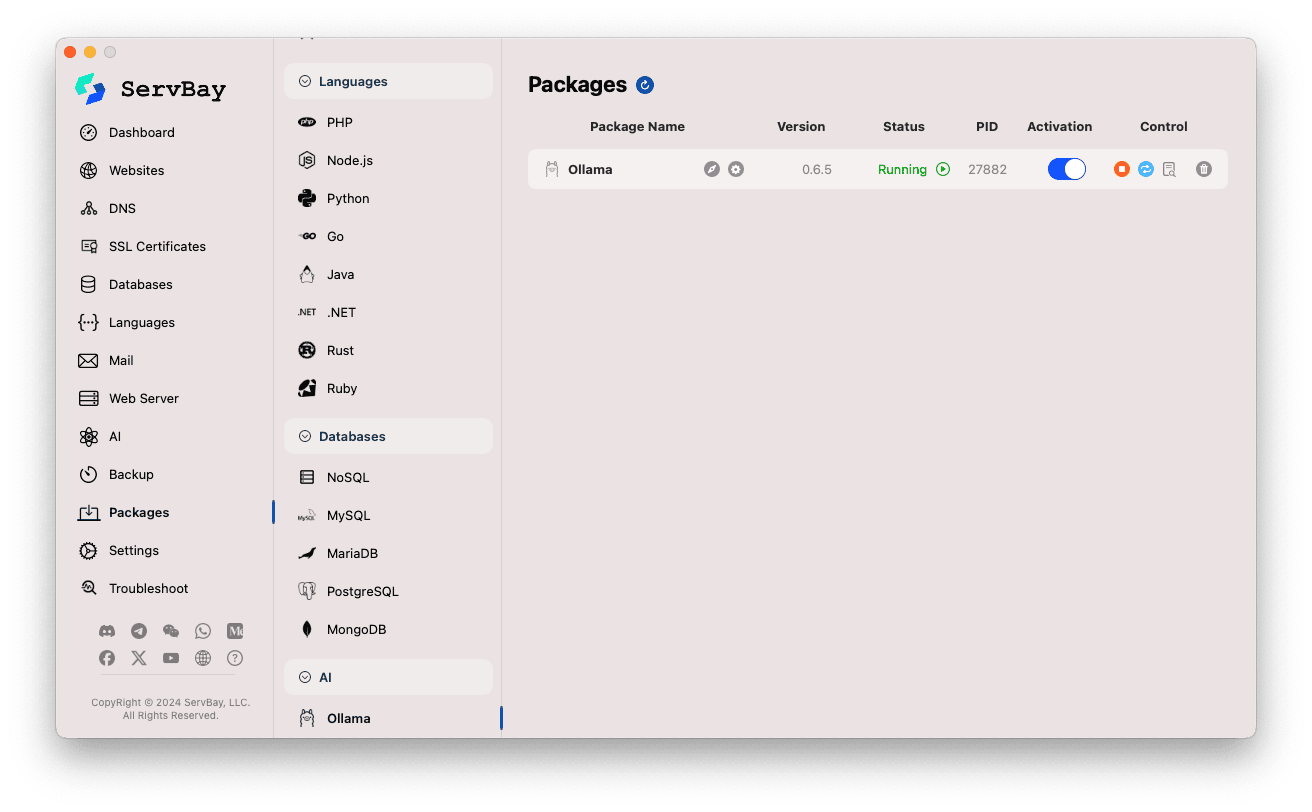
Доступ к пакету Ollama:
- Откройте приложение ServBay.
- В левой навигационной панели выберите
Пакеты(Packages). - В появившемся списке найдите и кликните по категории
AI. - Нажмите на
Ollama.
Управление сервисом Ollama:
- В правой части экрана отображается статус пакета Ollama, включая версию (например,
0.6.5), состояние сервиса (RunningилиStopped), идентификатор процесса (PID). - Используйте расположенные справа управляющие кнопки:
- Запуск/остановка: Оранжевая круглая кнопка позволяет запустить или остановить сервис Ollama.
- Перезапуск: Синяя кнопка обновления для перезапуска Ollama.
- Настроить: Желтая кнопка-шестеренка для перехода к экрану настроек Ollama.
- Удалить: Красная кнопка корзины для удаления пакета Ollama (будьте внимательны).
- Подробнее: Серая кнопка-информация может содержать дополнительные сведения или логи.
- В правой части экрана отображается статус пакета Ollama, включая версию (например,
Настройка Ollama
ServBay предоставляет удобный интерфейс для тонкой настройки параметров Ollama под ваши задачи.
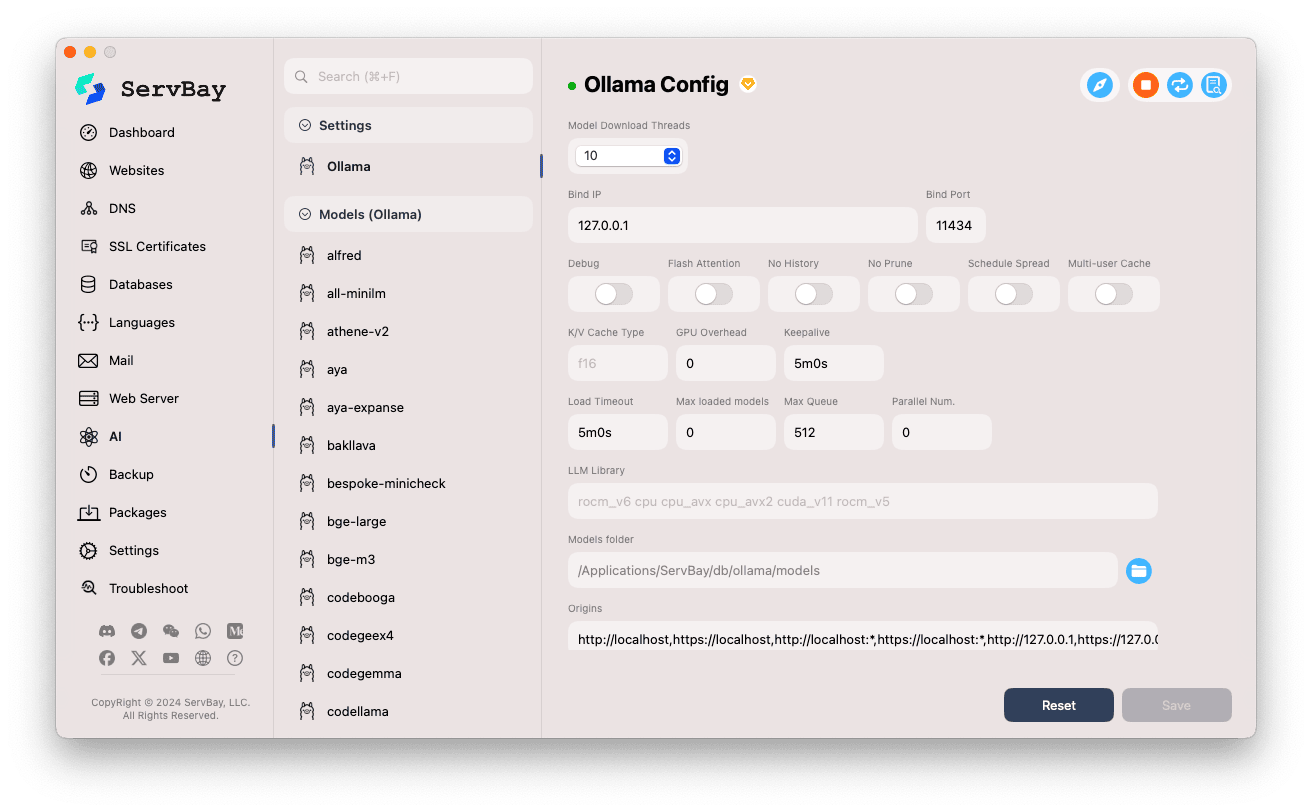
Доступ к настройкам:
- Откройте приложение ServBay.
- В левой навигационной панели выберите
AI. - В открывшемся списке выберите категорию
Настройки (Settings). - Кликните по
Ollama.
Изменение параметров:
- Model Download Threads: Количество параллельных потоков при скачивании моделей для ускорения загрузки.
- Bind IP: IP-адрес, на котором слушает Ollama. По умолчанию
127.0.0.1(доступ только с локального компьютера). - Bind Port: Порт Ollama. По умолчанию
11434. - Булевы опции:
Debug: Включить режим отладки.Flash Attention: Включить оптимизацию Flash Attention (при поддержке оборудования).No History: Не сохранять историю сессий.No Prune: Не удалять неиспользуемые модели автоматически.Schedule Spread: Настройки распределения задач.Multi-user Cache: Кэш для нескольких пользователей.
- K/V Cache Type: Тип key/value-кэша, влияющий на производительность и использование памяти.
- Настройки GPU:
GPU Overhead: Конфигурация нагрузки на GPU.Keepalive: Время поддержания активности GPU.
- Загрузка моделей и очередь:
Load Timeout: Таймаут загрузки моделей.Max loaded models: Максимальное количество одновременно загруженных моделей в память.Max Queue: Максимальная длина очереди запросов.Parallel Num.: Число параллельно обрабатываемых запросов.
- LLM Library: Путь к используемой библиотеке LLM.
- Models folder: Локальная директория для загрузки и хранения моделей Ollama. По умолчанию
/Applications/ServBay/db/ollama/models. Можно открыть каталог через иконку папки в Finder. - origins: Список доверенных источников, которым разрешен доступ к Ollama API (настройки CORS). По умолчанию включены распространенные локальные адреса (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1и др.). Для доступа с других доменов, необходимо добавить их адреса в этот список.
Сохранение настроек: После изменений нажмите кнопку
Saveв правом нижнем углу для применения изменений.
Управление моделями Ollama
ServBay делает процесс поиска, загрузки и управления моделями Ollama проще и быстрее.
Переход к управлению моделями:
- Откройте приложение ServBay.
- В левой навигационной панели выберите
AI. - В появившемся списке перейдите к
Models (Ollama).
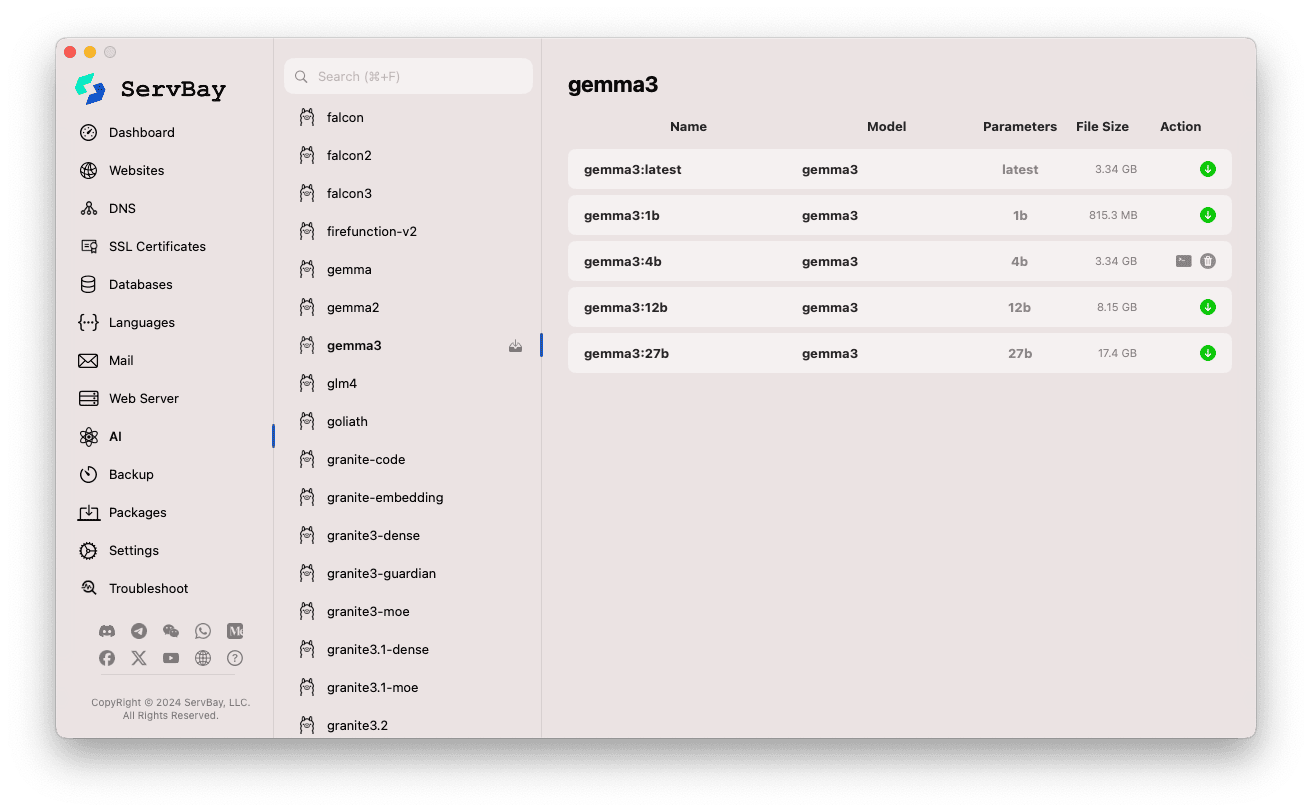
Обзор и скачивание моделей:
- Слева отображаются доступные модельные репозитории Ollama (например,
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistralи др.). Для примера выберитеgemma3. - Справа появится перечень различных вариантов или версий выбранного репозитория, обычно различающихся размером параметров (
latest,1b,4b,12b,27b). - Каждая строка содержит название модели, базовую модель, размер параметров и размер файла.
- Для скачивания нужной модели щелкните по зелёной иконке стрелки справа. Прогресс загрузки будет отображаться на экране. Скорость загрузки можно увеличить, изменив число потоков в настройках.
- Для уже скачанных моделей кнопка загрузки становится серой или недоступной.
- Слева отображаются доступные модельные репозитории Ollama (например,
Управление скачанными моделями:
- Загруженные модели обычно отмечаются явно (например, кнопка загрузки серая или появляется кнопка удаления).
- Для удаления модели — и освобождения места на диске — нажмите на кнопку удаления (иконка корзины).
Использование Ollama API
После запуска Ollama предоставляет REST API на заданных в настройках IP и порту (по умолчанию 127.0.0.1:11434). Вы можете взаимодействовать с моделями через любой HTTP-клиент (curl, Postman или языковые библиотеки).
TIP
ServBay заботится о вас и предоставляет домен https://ollama.servbay.host с SSL/TLS-шифрованием для безопасного HTTPS-доступа к API.
Вы можете использовать https://ollama.servbay.host вместо формата IP:порт для обращения к API Ollama.
Пример: Взаимодействие с моделью gemma3:latest через curl
Убедитесь, что модель gemma3:latest загружена в ServBay и сервис Ollama запущен.
bash
# Используем HTTPS через ServBay
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# Либо классический вариант через IP и порт
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'Объяснение команд:
http://127.0.0.1:11434/api/generate: Точка входа API для генерации текста с помощью Ollama.-d '{...}': Отправка POST-запроса с данными в формате JSON."model": "gemma3:latest": Имя используемой модели (должна быть скачана)."prompt": "Why is the sky blue?": Ваш вопрос или подсказка к модели."stream": false: Приfalseответ возвращается целиком. Если установитьtrue, API выдаёт ответ в режиме потока.
Ожидаемый результат:
В терминале вы увидите ответ в формате JSON, где поле response содержит текстовый ответ модели на вопрос "Why is the sky blue?".
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... другие метаданные
}Внимание к CORS: Если вы обращаетесь к API Ollama из JavaScript-кода в браузере, убедитесь, что домен вашего приложения (например, http://myapp.servbay.demo) добавлен в список origins в настройках Ollama. Иначе запрос блокируется браузером из-за политики CORS.
Примеры применения
Локальный запуск Ollama в ServBay открывает множество возможностей:
- AI-разработка на локальной машине: Не нужно использовать внешние API или облака — разработка и тестирование приложений на базе LLM происходит прямо на вашем Mac.
- Быстрое прототипирование: Оценка и переключение между разными open-source моделями для реализации идей.
- Оффлайн-доступ: Даже без интернета вы можете взаимодействовать с языковыми моделями LLM.
- Конфиденциальность данных: Все данные и запросы остаются на вашем компьютере, нет риска передачи сторонним сервисам.
- Экономия: Нет затрат на облачные AI-сервисы с оплатой по объему использования.
Важные замечания
- Свободное место: Файлы языковых моделей занимают значительный объём (от нескольких до десятков гигабайт). Убедитесь, что на вашем диске достаточно свободного пространства. По умолчанию модели хранятся в
/Applications/ServBay/db/ollama/models. - Системные ресурсы: Для работы LLM требуется много ресурсов CPU, оперативной памяти (RAM), а при наличии совместимой видеокарты Ollama может использовать GPU для ускорения (и это тоже влияет на загрузку системы). Перед запуском убедитесь, что ваш Mac соответствует требованиям выбранной модели.
- Время загрузки: Загрузка моделей зависит от скорости интернета и размера файла.
- Firewall: Если вы установили параметр
Bind IPна0.0.0.0для доступа к Ollama с других устройств в вашей сети, проверьте, что macOS Firewall разрешает входящие соединения на используемый порт (11434).
Итоги
Интеграция Ollama в ServBay кардинально упрощает развёртывание и управление локальными языковыми моделями на macOS. Благодаря интуитивному интерфейсу разработчик может быстро запускать сервисы, настраивать параметры, загружать модели — и практически мгновенно приступить к созданию или тестированию AI-приложений. Всё это укрепляет статус ServBay как универсального инструмента для локальной разработки.
