
การใช้งาน Ollama ใน ServBay
ServBay ผสานศักยภาพ AI ในเครื่องขั้นสูงเข้าสู่สภาพแวดล้อมการพัฒนาของคุณ ให้คุณรันโมเดลปัญญาประดิษฐ์แบบภาษาใหญ่ (LLM) แบบ open-source หลายตัวบน macOS ผ่าน Ollama ได้ในไม่กี่คลิก คู่มือนี้จะแนะนำวิธีเปิดใช้งาน ตั้งค่า จัดการ Ollama และโมเดลต่าง ๆ ภายใน ServBay และเริ่มต้นใช้งาน
ภาพรวม
Ollama คือเครื่องมือยอดนิยมที่ช่วยให้คุณดาวน์โหลด ติดตั้ง และรันโมเดลภาษาใหญ่ในเครื่องอย่างง่ายดาย ServBay ได้ผนวก Ollama เป็นแพ็คเกจแยกโดยมีหน้าจอบริหารแบบกราฟิก ใช้งานสะดวกสำหรับนักพัฒนา:
- เริ่มต้น หยุด หรือรีสตาร์ทบริการ Ollama ได้ในคลิกเดียว
- ปรับแต่งการตั้งค่าต่าง ๆ ของ Ollama ผ่านหน้าจอกราฟิก
- ค้นหา ดาวน์โหลด และจัดการโมเดล LLM ที่รองรับ
- ทดสอบและพัฒนาแอปพลิเคชัน AI ในเครื่อง โดยไม่ต้องพึ่งพาบริการคลาวด์
ข้อกำหนดเบื้องต้น
- ติดตั้งและเปิดใช้งาน ServBay บนระบบ macOS ของคุณเรียบร้อยแล้ว
การเปิดใช้งานและจัดการบริการ Ollama
คุณสามารถจัดการแพ็คเกจ Ollama ได้ง่าย ๆ จากอินเทอร์เฟซหลักของ ServBay
เข้าถึงแพ็คเกจ Ollama:
- เปิดแอปพลิเคชัน ServBay
- ที่แถบนำทางซ้าย เลือก
แพ็คเกจ(Packages) - ในรายการที่แสดงผล คลิกที่หมวด
AI - จากนั้นคลิกที่
Ollama
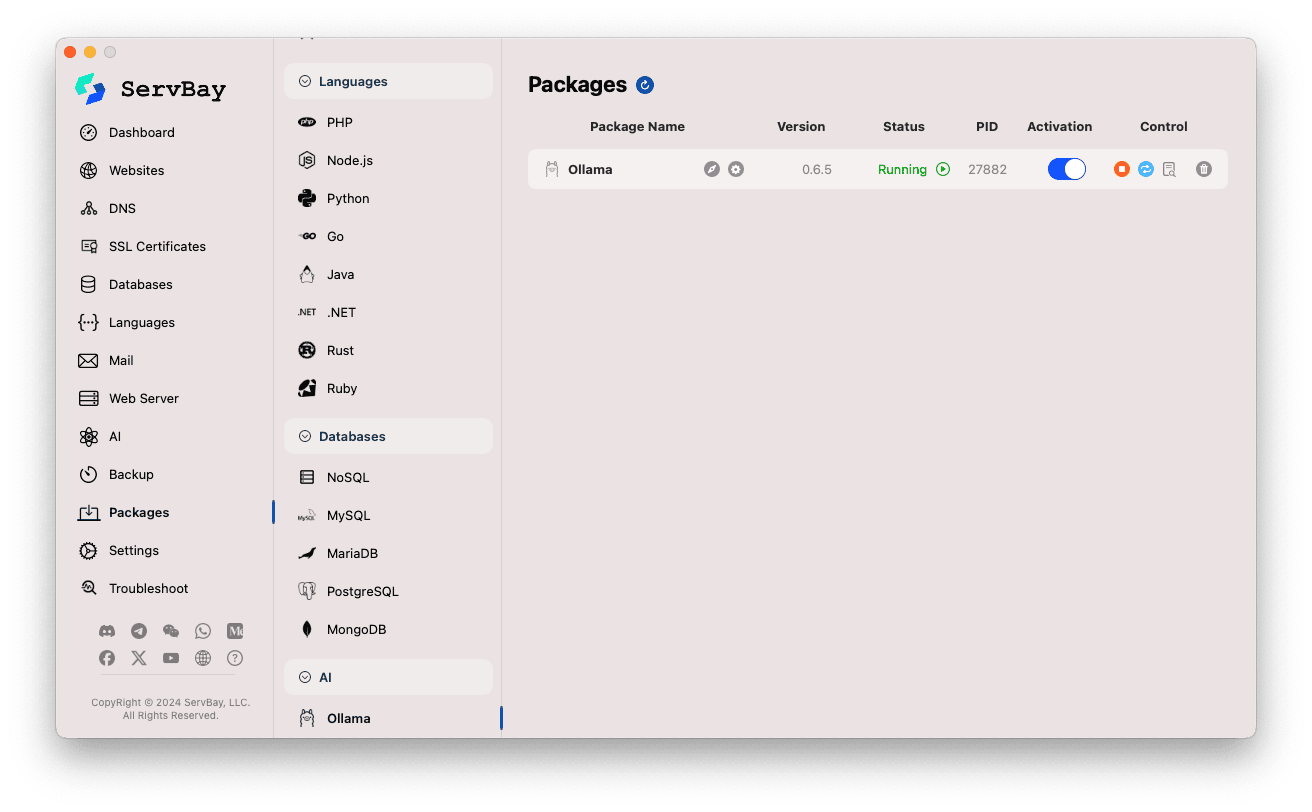
จัดการบริการ Ollama:
- ด้านขวาจะแสดงสถานะต่าง ๆ ของแพ็คเกจ Ollama เช่น หมายเลขเวอร์ชัน (เช่น
0.6.5), สถานะการทำงาน (RunningหรือStopped), และรหัสกระบวนการ (PID) - ใช้ปุ่มควบคุมทางขวา:
- เริ่ม/หยุด: ปุ่มสีส้มทรงกลมสำหรับเริ่มหรือหยุดบริการ Ollama
- รีสตาร์ท: ปุ่มสีน้ำเงินสำหรับรีสตาร์ทบริการ Ollama
- ตั้งค่า: ปุ่มฟันเฟืองสีเหลืองสำหรับเข้าสู่หน้าตั้งค่า Ollama
- ลบ: ปุ่มถังขยะสีแดงสำหรับถอนการติดตั้งแพ็คเกจ Ollama (โปรดระวัง)
- ข้อมูลเพิ่มเติม: ปุ่ม i สีเทา อาจใช้ดูข้อมูลเพิ่มเติมหรือเข้าถึงล็อก
- ด้านขวาจะแสดงสถานะต่าง ๆ ของแพ็คเกจ Ollama เช่น หมายเลขเวอร์ชัน (เช่น
การตั้งค่า Ollama
ServBay มอบอินเทอร์เฟซกราฟิกให้คุณปรับแต่งพารามิเตอร์การทำงานของ Ollama ให้เหมาะกับแต่ละกรณีการใช้งาน
เข้าสู่หน้าตั้งค่า:
- เปิดแอปพลิเคชัน ServBay
- ที่แถบนำทางซ้าย คลิก
AI - เลือกหมวด
ตั้งค่า (Settings) - จากนั้นคลิก
Ollama
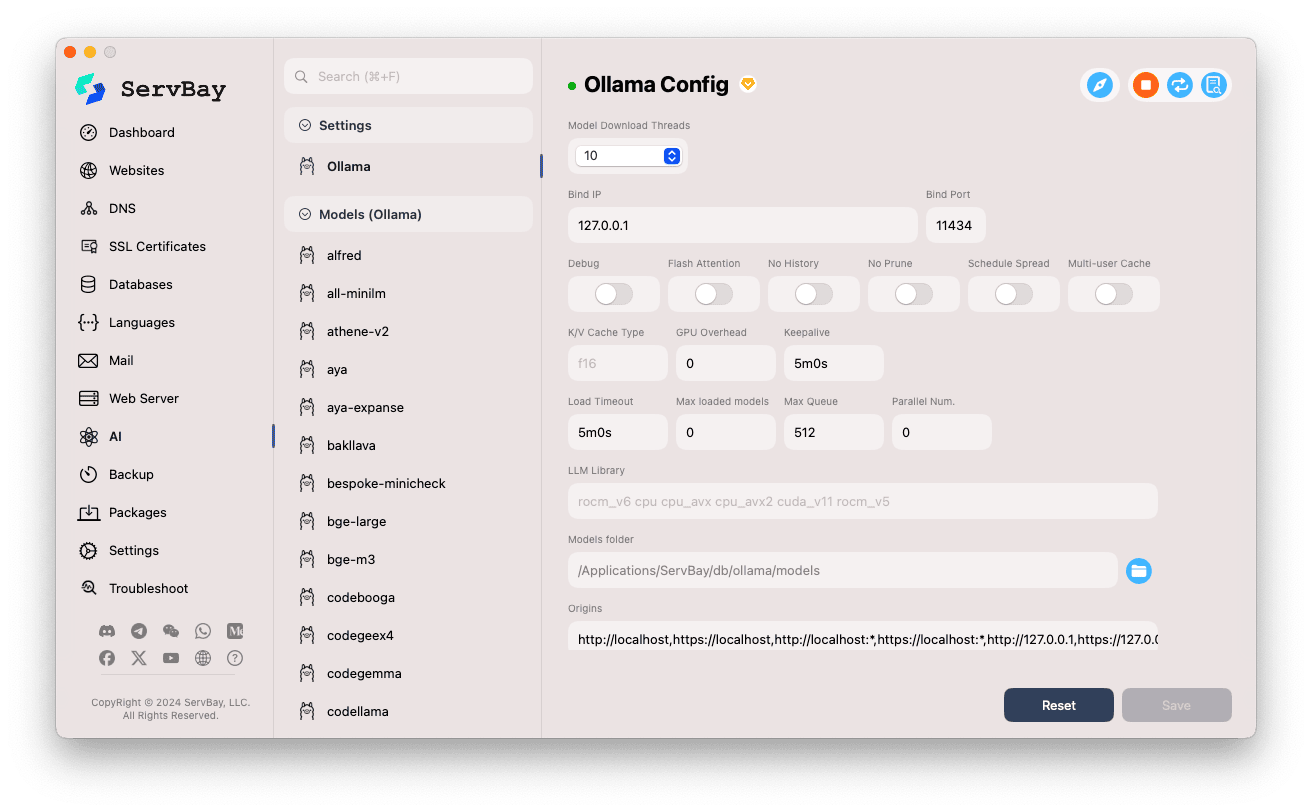
ปรับแต่งตัวเลือกการตั้งค่า:
- Model Download Threads: กำหนดจำนวนเธรดสำหรับดาวน์โหลดโมเดลพร้อมกัน ช่วยเพิ่มความเร็วการดาวน์โหลด
- Bind IP: กำหนด IP ที่บริการ Ollama จะรันฟังอยู่ ปกติเป็น
127.0.0.1(เฉพาะเครื่องนี้เท่านั้นที่เข้าถึงได้) - Bind Port: กำหนดพอร์ตที่ Ollama รับฟังค่าเริ่มต้นคือ
11434 - ตัวเลือกเปิด-ปิด (boolean switch):
Debug: เปิดโหมดดีบั๊กFlash Attention: เปิดใช้งานการเพิ่มประสิทธิภาพ Flash Attention (อาจต้องรองรับฮาร์ดแวร์)No History: ปิดการเก็บประวัติสนทนาNo Prune: ไม่ทำความสะอาดโมเดลที่ไม่ได้ใช้งานโดยอัตโนมัติSchedule Spread: เกี่ยวกับกลยุทธ์แบ่งการทำงานMulti-user Cache: การแคชสำหรับผู้ใช้หลายคน
- K/V Cache Type: ระบุประเภทแคชคีย์/ค่า มีผลกับประสิทธิภาพและการใช้หน่วยความจำ
- ตัวเลือกสำหรับ GPU:
GPU Overhead: การตั้งค่าค่าใช้จ่ายบน GPUKeepalive: ระยะเวลาที่รักษา GPU ให้ทำงานต่อเนื่อง
- การโหลดโมเดลและคิว:
Load Timeout: เวลา timeout สำหรับโหลดโมเดลMax loaded models: จำนวนสูงสุดของโมเดลที่โหลดในหน่วยความจำได้พร้อมกันMax Queue: ความยาวคิวสูงสุดของคำขอParallel Num.: จำนวนคำขอที่จะประมวลผลพร้อมกัน
- LLM Library: ระบุเส้นทางไฟล์ไลบรารี LLM ที่ต้องการใช้
- Models folder: โฟลเดอร์ในเครื่องที่ Ollama ใช้สำหรับดาวน์โหลดและเก็บโมเดล (
/Applications/ServBay/db/ollama/modelsโดยค่าเริ่มต้น) คลิกไอคอนโฟลเดอร์เพื่อเปิดใน Finder ได้โดยตรง - origins: กำหนดต้นทางที่อนุญาตให้เรียกใช้งาน Ollama API (CORS) ค่าเริ่มต้นรวมแอดเดรสท้องถิ่น (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1เป็นต้น) หากต้องให้ web app จากโดเมนอื่นเข้าถึง Ollama ให้เพิ่มต้นทางที่ต้องการที่นี่
บันทึกการตั้งค่า: เมื่อปรับแต่งค่าต่าง ๆ เสร็จแล้ว กดปุ่ม
Saveที่มุมขวาล่างเพื่อบันทึก
การจัดการโมเดลของ Ollama
ServBay ทำให้กระบวนการค้นหา ดาวน์โหลด และจัดการโมเดลง่ายขึ้นกว่าที่เคย
เข้าสู่หน้าจัดการโมเดล:
- เปิดแอปพลิเคชัน ServBay
- ในแถบข้างซ้าย คลิก
AI - แล้วเลือก
Models (Ollama)
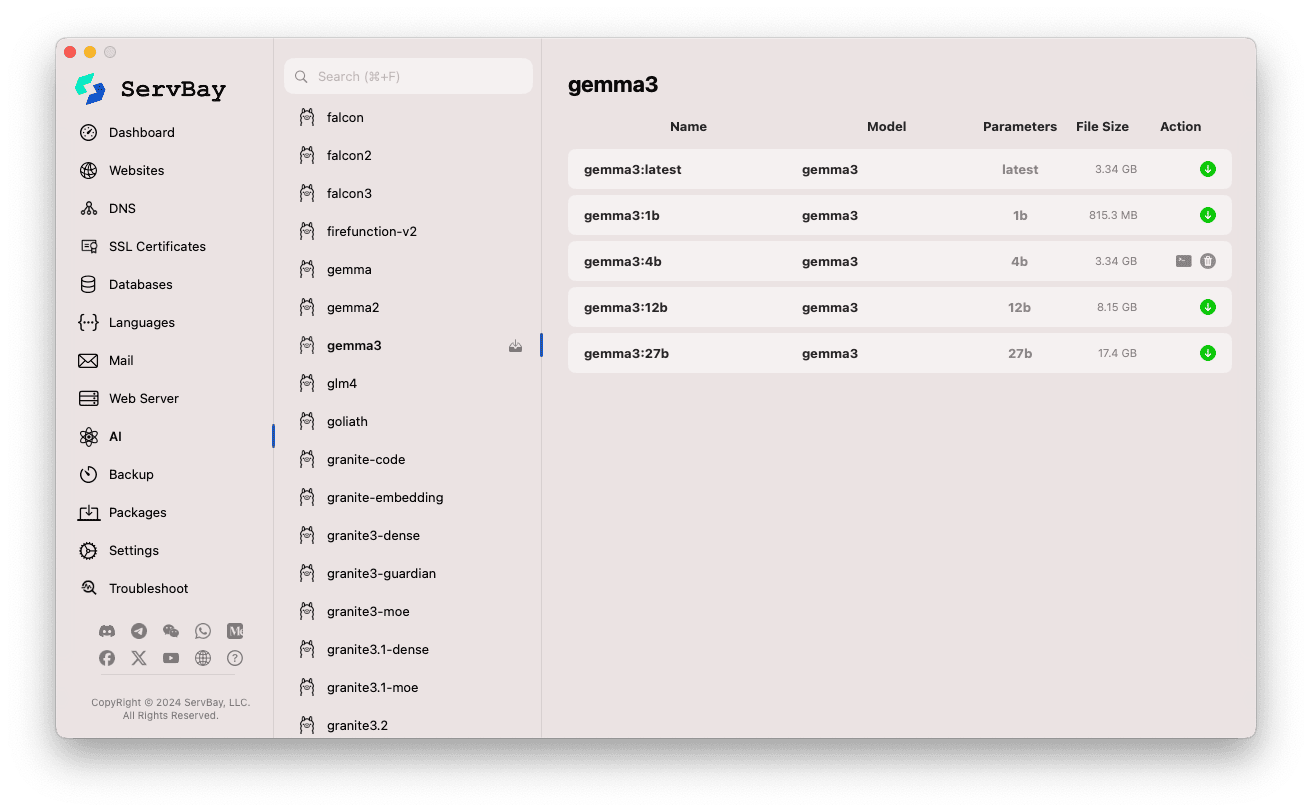
เรียกดูและดาวน์โหลดโมเดล:
- ด้านซ้ายจะแสดงรายการโมเดลที่ Ollama รองรับ (เช่น
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistralเป็นต้น) คลิกชื่อโมเดล (เช่นgemma3) - ด้านขวาจะปรากฏเวอร์ชันหรือรุ่นย่อยต่าง ๆ ของโมเดลดังกล่าว แยกตามขนาดพารามิเตอร์ (
latest,1b,4b,12b,27bฯลฯ) - ในแต่ละบรรทัดจะแสดงชื่อโมเดล โมเดลฐาน ขนาดพารามิเตอร์ และขนาดไฟล์
- กดปุ่มลูกศรดาวน์โหลดสีเขียวที่ขวาสุดเพื่อเริ่มดาวน์โหลดโมเดลนั้น ๆ สถานะความคืบหน้าจะแสดงที่หน้าจอ ดาวน์โหลดพร้อมกันได้มากขึ้นโดยตั้งค่าจำนวนเธรดในเมนูตั้งค่า
- โมเดลที่ดาวน์โหลดเสร็จแล้ว ปุ่มดาวน์โหลดจะเป็นสีเทาหรือไม่สามารถกดได้
- ด้านซ้ายจะแสดงรายการโมเดลที่ Ollama รองรับ (เช่น
จัดการโมเดลที่ดาวน์โหลดแล้ว:
- โมเดลที่มีอยู่ในเครื่องจะแสดงสถานะชัดเจน (เช่น ปุ่มดาวน์โหลดเป็นสีเทาหรือขึ้นปุ่มลบ)
- คลิกปุ่มถังขยะ เพื่อลบไฟล์โมเดลที่ไม่ต้องการออกจากเครื่องและคืนพื้นที่ดิสก์
การใช้งาน Ollama API
เมื่อ Ollama เริ่มทำงาน บริการ REST API จะพร้อมใช้ตาม Bind IP และ Bind Port ที่ตั้งค่าไว้ (ปกติคือ 127.0.0.1:11434) คุณสามารถใช้ HTTP client ใด ๆ (เช่น curl Postman หรือไลบรารีในภาษาโปรแกรม) สื่อสารกับโมเดลที่ดาวน์โหลดมาได้ทันที
TIP
ServBay ให้บริการโดเมนที่รองรับ SSL/TLS (HTTPS) โดยตรง คือ https://ollama.servbay.host
คุณจึงสามารถเข้าถึง API ของ Ollama ด้วยโดเมนนี้ได้ทันที ไม่ต้องจำเป็นต้องใช้รูปแบบ IP:พอร์ต
ตัวอย่าง: ใช้ curl สื่อสารกับโมเดล gemma3:latest
ให้แน่ใจว่าคุณได้ดาวน์โหลดโมเดล gemma3:latest ผ่าน ServBay และ Ollama กำลังทำงานอยู่
bash
# ใช้ https ที่ ServBay ให้บริการ
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# หรือแบบเดิม IP:พอร์ต
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'คำอธิบายคำสั่ง:
http://127.0.0.1:11434/api/generate: endpoint API สำหรับสร้างข้อความ (text generation) ของ Ollama-d '{...}': ส่ง POST body ที่ประกอบด้วย JSON ข้อมูล"model": "gemma3:latest": กำหนดชื่อโมเดลที่จะใช้ (ต้องดาวน์โหลดมาแล้ว)"prompt": "Why is the sky blue?": คำถามหรือ prompt ที่ต้องการให้โมเดลตอบ"stream": false: ถ้าเป็นfalseผลลัพธ์จะตอบกลับทีเดียว เมื่อโมเดลประมวลผลเสร็จ ถ้าtrueจะตอบกลับแบบสตรีม (ทยอยส่ง token)
ผลลัพธ์ที่คาดหวัง:
คุณจะเห็นการตอบกลับเป็น JSON ในหน้าคอนโซล โดยฟิลด์ response จะเป็นคำตอบของโมเดลต่อคำถาม "Why is the sky blue?"
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... ข้อมูลเมตาอื่น ๆ
}หมายเหตุ CORS: หากต้องการเรียก Ollama API จากโค้ด JavaScript ในเบราว์เซอร์ โปรดตรวจสอบให้แน่ใจว่าแอป web ของคุณ (http://myapp.servbay.demo เป็นต้น) ถูกเพิ่มไว้ในรายการ origins ของ Ollama API มิฉะนั้น เบราว์เซอร์จะบล็อกคำขอตามนโยบาย CORS
กรณีการใช้งาน
การรัน Ollama ในเครื่องบน ServBay มีข้อดีมากมาย เช่น
- พัฒนา AI ในเครื่อง: ไม่ต้องพึ่งพา API ภายนอกหรือคลาวด์ สามารถพัฒนาและทดสอบแอปพลิเคชันที่ใช้ LLM ได้บนเครื่องตนเอง
- สร้างต้นแบบอย่างรวดเร็ว: ทดลองโมเดล open-source หลากหลายเพื่อพิสูจน์แนวคิดใหม่ ๆ ได้ทันใจ
- ใช้งานแบบออฟไลน์: แม้ไม่มีอินเทอร์เน็ตก็สื่อสารกับ LLM ได้
- ความเป็นส่วนตัวของข้อมูล: ข้อมูลและการประมวลผลทั้งหมดอยู่ในเครื่อง ไม่ต้องกังวลเรื่องการรั่วไหล
- คุ้มค่า: ไม่ต้องเสียค่าใช้บริการ AI บนคลาวด์ที่คิดตามปริมาณการใช้งาน
ข้อควรระวัง
- พื้นที่ดิสก์: ไฟล์โมเดล LLM ขนาดใหญ่มาก (หลาย GB ถึงหลายสิบ GB) ตรวจสอบให้แน่ใจว่าคุณมีพื้นที่ว่างเพียงพอ โมเดลจะเก็บที่
/Applications/ServBay/db/ollama/modelsเป็นค่าเริ่มต้น - ทรัพยากรระบบ: การรัน LLM ต้องใช้ CPU และ RAM มาก หาก Mac ของคุณมีกำลัง GPU ที่รองรับ Ollama อาจใช้ GPU ช่วยเร่งประสิทธิภาพ และกินทรัพยากร GPU เพิ่มเติมด้วย โปรดเลือกโมเดลที่เหมาะสมกับสเปกเครื่อง
- เวลาในการดาวน์โหลด: ระยะเวลาดาวน์โหลดขึ้นกับขนาดโมเดลและความเร็วอินเทอร์เน็ต
- ไฟร์วอลล์: หากตั้งค่า
Bind IPเป็น0.0.0.0เพื่อให้เครื่องอื่นในเครือข่ายเข้าถึง Ollama ได้ อย่าลืมปรับ firewall ของ macOS ให้อนุญาตการเชื่อมต่อที่พอร์ต11434
สรุป
ServBay ช่วยให้การติดตั้งและบริหารโมเดลภาษาใหญ่ในเครื่อง (LLM) บน macOS ง่ายขึ้นมากด้วยการรวม Ollama เข้าสู่ระบบ ให้คุณเริ่มบริการ ปรับตั้งค่า และดาวน์โหลดโมเดลผ่านหน้าจอกราฟิกได้ทันที เพิ่มประสิทธิภาพการพัฒนา AI ในเครื่องและต่อยอด ServBay ในฐานะแพลตฟอร์ม one-stop สำหรับนักพัฒนาอย่างแท้จริง
