
Sử dụng Ollama trong ServBay
ServBay tích hợp sức mạnh AI cục bộ vào môi trường phát triển của bạn, cho phép bạn dễ dàng chạy nhiều mô hình ngôn ngữ lớn mã nguồn mở (LLM) trên macOS thông qua Ollama. Tài liệu này hướng dẫn bạn cách bật, cấu hình, quản lý Ollama và các mô hình của nó trong ServBay, cũng như bắt đầu sử dụng.
Tổng quan
Ollama là một công cụ phổ biến giúp đơn giản hóa việc tải, thiết lập, và vận hành mô hình ngôn ngữ lớn ngay trên máy tính cá nhân. ServBay tích hợp Ollama như một gói phần mềm độc lập, cung cấp giao diện đồ họa trực quan để các nhà phát triển có thể:
- Khởi động, dừng hoặc khởi động lại dịch vụ Ollama chỉ với một cú nhấp chuột.
- Cấu hình các tham số của Ollama dễ dàng thông qua giao diện đồ họa.
- Duyệt, tải về và quản lý các mô hình LLM được hỗ trợ.
- Phát triển, kiểm thử và thử nghiệm ứng dụng AI tại chỗ – không cần phụ thuộc dịch vụ đám mây.
Điều kiện tiên quyết
- Đã cài đặt và chạy ServBay trên hệ điều hành macOS của bạn.
Bật và quản lý dịch vụ Ollama
Bạn có thể dễ dàng quản lý gói phần mềm Ollama thông qua giao diện chính của ServBay.
Truy cập gói Ollama:
- Mở ứng dụng ServBay.
- Trong thanh điều hướng bên trái, nhấn vào
Packages(Gói phần mềm). - Từ danh sách mở rộng, tìm và nhấn vào nhóm
AI. - Chọn
Ollama.
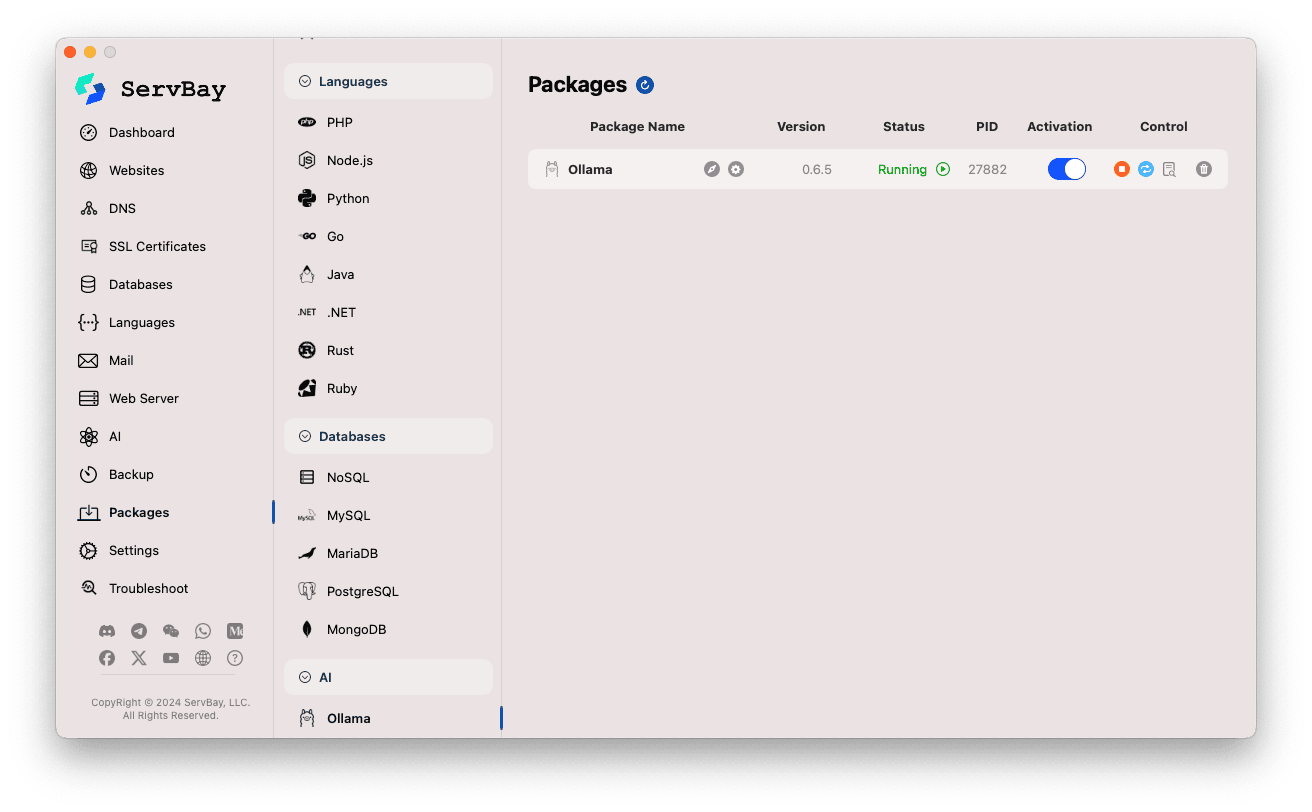
Quản lý dịch vụ Ollama:
- Ở phần bên phải, bạn sẽ thấy trạng thái của gói Ollama, bao gồm phiên bản (ví dụ
0.6.5), trạng thái hoạt động (RunninghoặcStopped), ID tiến trình (PID). - Sử dụng các nút điều khiển bên phải:
- Khởi động/Dừng: Nút hình tròn màu cam để bật hoặc tắt dịch vụ Ollama.
- Khởi động lại: Nút làm mới màu xanh nước biển để khởi động lại dịch vụ.
- Cấu hình: Nút hình bánh răng màu vàng dẫn đến trang cài đặt Ollama.
- Gỡ cài đặt: Nút thùng rác màu đỏ để xóa gói Ollama (cẩn trọng khi sử dụng).
- Thông tin thêm: Nút thông tin màu xám có thể cung cấp thêm thông tin hoặc truy cập nhật ký.
- Ở phần bên phải, bạn sẽ thấy trạng thái của gói Ollama, bao gồm phiên bản (ví dụ
Cấu hình Ollama
ServBay cung cấp giao diện đồ họa để điều chỉnh các tham số hoạt động của Ollama nhằm phù hợp với nhu cầu sử dụng.
Truy cập giao diện cấu hình:
- Mở ứng dụng ServBay.
- Trong thanh điều hướng bên trái, nhấn vào
AI. - Từ danh sách mở rộng, hãy chọn nhóm
Settings(Cài đặt). - Chọn
Ollama.
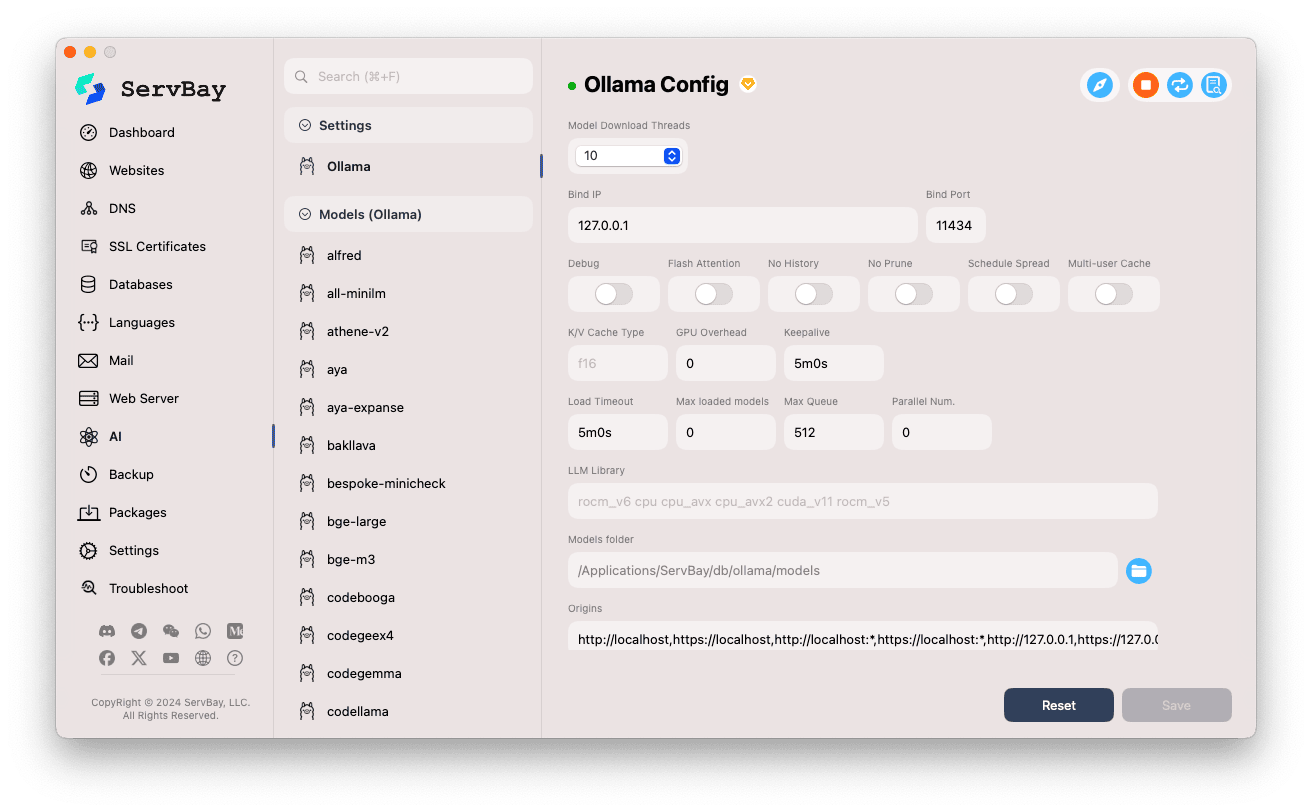
Điều chỉnh các thông số cấu hình:
- Model Download Threads: Thiết lập số luồng tải mô hình song song, giúp tải nhanh hơn.
- Bind IP: Địa chỉ IP mà dịch vụ Ollama sẽ lắng nghe (mặc định là
127.0.0.1, chỉ cho phép truy cập cục bộ). - Bind Port: Cổng mà Ollama sử dụng (mặc định
11434). - Các tùy chọn bật/tắt:
Debug: Kích hoạt chế độ gỡ lỗi.Flash Attention: Có thể bật tối ưu Flash Attention (cần phần cứng hỗ trợ).No History: Không lưu lại lịch sử hội thoại.No Prune: Ngăn tự động dọn dẹp mô hình không sử dụng.Schedule Spread: Liên quan đến chiến lược lên lịch.Multi-user Cache: Liên quan đến bộ nhớ đệm đa người dùng.
- K/V Cache Type: Loại cache Key/Value, ảnh hưởng đến hiệu suất và sử dụng bộ nhớ.
- Liên quan đến GPU:
GPU Overhead: Cấu hình mức chiếm dụng GPU.Keepalive: Thời gian giữ GPU hoạt động.
- Tải mô hình & xếp hàng:
Load Timeout: Thời gian chờ tải mô hình.Max loaded models: Số lượng mô hình tối đa được tải vào bộ nhớ cùng lúc.Max Queue: Độ dài tối đa của hàng đợi yêu cầu.Parallel Num.: Số lượng xử lý song song.
- LLM Library: Đường dẫn thư viện LLM nền tảng được sử dụng.
- Models folder: Thư mục lưu trữ mô hình cục bộ mà Ollama sử dụng để tải và lưu mô hình (mặc định
/Applications/ServBay/db/ollama/models). Bạn có thể nhấn biểu tượng thư mục để mở trong Finder. - origins: Cấu hình nguồn được phép truy cập API Ollama (thiết lập CORS). Mặc định bao gồm các địa chỉ cục bộ phổ biến (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1...). Nếu cần truy cập từ web app ở tên miền khác, hãy thêm nguồn tại đây.
Lưu cấu hình: Sau khi điều chỉnh, nhấn nút
Savedưới góc phải để áp dụng thay đổi.
Quản lý mô hình Ollama
ServBay đơn giản hóa việc tìm kiếm, tải và quản lý các mô hình Ollama.
Truy cập giao diện quản lý mô hình:
- Mở ứng dụng ServBay.
- Trong thanh điều hướng bên trái, nhấn vào
AI. - Từ danh sách mở rộng, chọn
Models (Ollama).
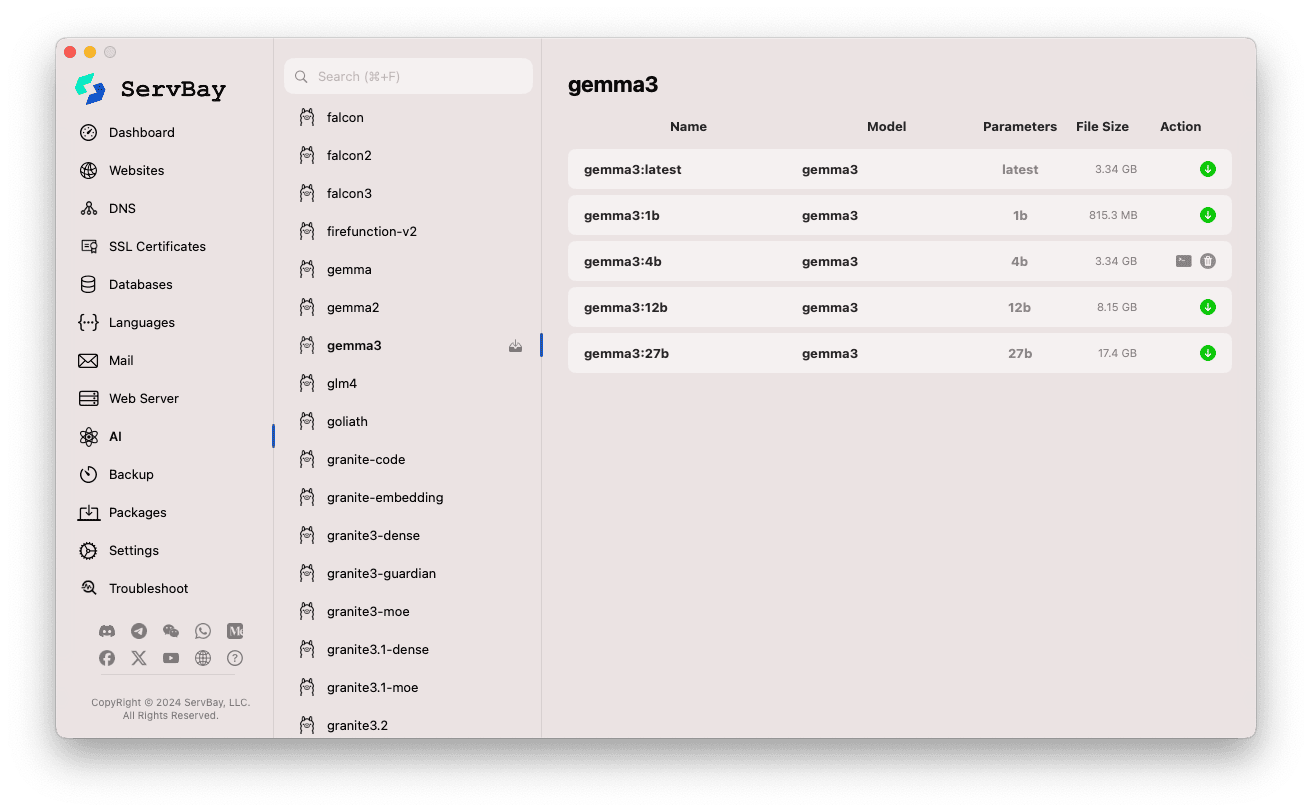
Duyệt và tải xuống mô hình:
- Cột trái liệt kê nhiều thư viện mô hình được Ollama hỗ trợ (như
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistral, ...). Chọn tên thư viện (ví dụgemma3). - Phía bên phải hiển thị các biến thể hoặc phiên bản khác nhau của thư viện đó, thường phân biệt bởi số tham số (
latest,1b,4b,12b,27b...). - Mỗi dòng hiển thị tên mô hình, mô hình cơ sở, số tham số, dung lượng file.
- Nhấn nút mũi tên màu xanh lá ở cạnh phải để tải xuống mô hình tương ứng. Tiến trình tải sẽ hiện trên giao diện. Có thể tăng tốc bằng cách tăng số luồng tải trong mục
Model Download Threads. - Khi mô hình đã được tải, nút tải sẽ chuyển xám hoặc không còn tác dụng.
- Cột trái liệt kê nhiều thư viện mô hình được Ollama hỗ trợ (như
Quản lý mô hình đã tải:
- Các mô hình đã tải thường sẽ được đánh dấu (ví dụ nút tải chuyển xám hoặc xuất hiện nút xóa).
- Bạn có thể nhấn biểu tượng thùng rác tương ứng để xóa file mô hình cục bộ nhằm giải phóng không gian đĩa.
Sử dụng Ollama API
Sau khi bật Ollama, dịch vụ REST API sẽ có sẵn trên Bind IP và Bind Port đã cấu hình (mặc định là 127.0.0.1:11434). Bạn có thể sử dụng bất kỳ HTTP client nào (như curl, Postman hoặc thư viện lập trình) để tương tác với mô hình vừa tải về.
TIP
ServBay cung cấp sẵn một tên miền hỗ trợ SSL/TLS, cho phép truy cập HTTPS: https://ollama.servbay.host
Bạn có thể sử dụng tên miền https://ollama.servbay.host thay vì cách truy cập qua IP:cổng để làm việc với API Ollama.
Ví dụ: Sử dụng curl để tương tác với mô hình gemma3:latest đã tải
Đảm bảo bạn đã tải xong mô hình gemma3:latest qua ServBay và dịch vụ Ollama đang chạy.
bash
# Sử dụng tên miền HTTPS của ServBay
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# Hoặc dùng phương thức truyền thống qua IP:cổng
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'Giải thích các tham số lệnh:
http://127.0.0.1:11434/api/generate: Địa chỉ endpoint API tạo văn bản của Ollama.-d '{...}': Gửi body POST chứa dữ liệu JSON."model": "gemma3:latest": Tên mô hình cần dùng (đã tải sẵn)."prompt": "Why is the sky blue?": Câu hỏi hoặc nội dung bạn muốn mô hình trả lời."stream": false: Đặtfalseđể nhận một lần toàn bộ kết quả;truesẽ trả về các token dần dần.
Kết quả mong đợi:
Bạn sẽ thấy phản hồi JSON trên terminal, trường response chứa câu trả lời của mô hình cho "Why is the sky blue?".
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "The sky appears blue because of a phenomenon called Rayleigh scattering...",
"done": true,
// ... các metadata khác
}Lưu ý về CORS: Nếu bạn truy cập API Ollama từ mã JavaScript trên trình duyệt, hãy đảm bảo địa chỉ nguồn (ví dụ http://myapp.servbay.demo) đã được thêm vào danh sách origins trong phần cấu hình Ollama, nếu không, trình duyệt sẽ chặn yêu cầu do chính sách CORS.
Các trường hợp ứng dụng
Chạy Ollama tại chỗ với ServBay đem lại nhiều lợi ích vượt trội:
- Phát triển AI cục bộ: Không cần dựa vào API hay dịch vụ đám mây bên ngoài, có thể phát triển và kiểm thử ứng dụng dựa trên LLM trực tiếp trên máy tính.
- Thiết kế nguyên mẫu nhanh: Dễ dàng thử nghiệm các mô hình mã nguồn mở khác nhau để kiểm chứng ý tưởng.
- Hoạt động ngoại tuyến: Có thể tương tác với LLM kể cả khi mất kết nối Internet.
- Bảo mật dữ liệu: Mọi dữ liệu và giao tiếp đều lưu trên máy cá nhân, bảo vệ quyền riêng tư tối đa.
- Hiệu quả chi phí: Không tốn phí sử dụng dịch vụ AI đám mây theo thời lượng.
Lưu ý
- Dung lượng đĩa: Các mô hình ngôn ngữ lớn thường có dung lượng rất lớn (vài GB đến hàng chục GB). Hãy đảm bảo máy bạn còn đủ không gian trống. Mặc định, mô hình được lưu ở
/Applications/ServBay/db/ollama/models. - Tài nguyên hệ thống: Việc chạy LLM tiêu tốn CPU, RAM rất nhiều. Nếu Mac của bạn có GPU tương thích, Ollama có thể tận dụng GPU để tăng tốc – điều này cũng tốn GPU. Hãy đảm bảo cấu hình máy phù hợp với mô hình bạn muốn chạy.
- Thời gian tải xuống: Việc tải mô hình có thể mất thời gian, tùy thuộc vào tốc độ mạng và kích thước file.
- Tường lửa: Nếu bạn đổi
Bind IPthành0.0.0.0cho phép thiết bị khác trong LAN truy cập, đảm bảo tường lửa macOS cho phép truy cập vào cổng Ollama (11434).
Tổng kết
Nhờ tích hợp Ollama, ServBay đã cực kỳ đơn giản hóa quy trình triển khai và quản lý các mô hình ngôn ngữ lớn tại chỗ trên macOS. Với giao diện trực quan, bạn dễ dàng khởi động dịch vụ, tùy chỉnh cấu hình, tải mô hình, đồng thời bắt đầu phát triển, thử nghiệm các giải pháp AI cục bộ chỉ trong vài bước, qua đó nâng tầm giá trị của ServBay như một môi trường phát triển all-in-one tại chỗ.
