
Menggunakan Ollama dalam ServBay
ServBay mengintegrasikan keupayaan AI tempatan yang hebat ke dalam persekitaran pembangunan anda, membolehkan anda menjalankan pelbagai model bahasa besar sumber terbuka (LLM) dengan mudah melalui Ollama di macOS. Dokumen ini akan membimbing anda untuk mengaktifkan, mengkonfigurasi, mengurus Ollama serta model-modelnya, dan mula menggunakannya.
Gambaran Umum
Ollama ialah alat popular yang memudahkan proses memuat turun, menyediakan, dan menjalankan model bahasa besar secara tempatan di komputer anda. ServBay mengintegrasikan Ollama sebagai pakej perisian kendiri, menawarkan antara muka pengurusan grafik agar pembangun dapat:
- Mulakan, hentikan, atau hidupkan semula perkhidmatan Ollama dengan satu klik.
- Konfigurasi pelbagai parameter Ollama melalui antara muka grafik.
- Lihat, muat turun dan urus model LLM yang disokong.
- Membangunkan, menguji dan bereksperimen dengan aplikasi AI secara tempatan tanpa kebergantungan kepada perkhidmatan awan.
Prasyarat
- ServBay telah dipasang dan berjalan pada sistem macOS anda.
Mengaktif & Mengurus Perkhidmatan Ollama
Anda boleh mengurus pakej Ollama dengan mudah melalui antara muka utama ServBay.
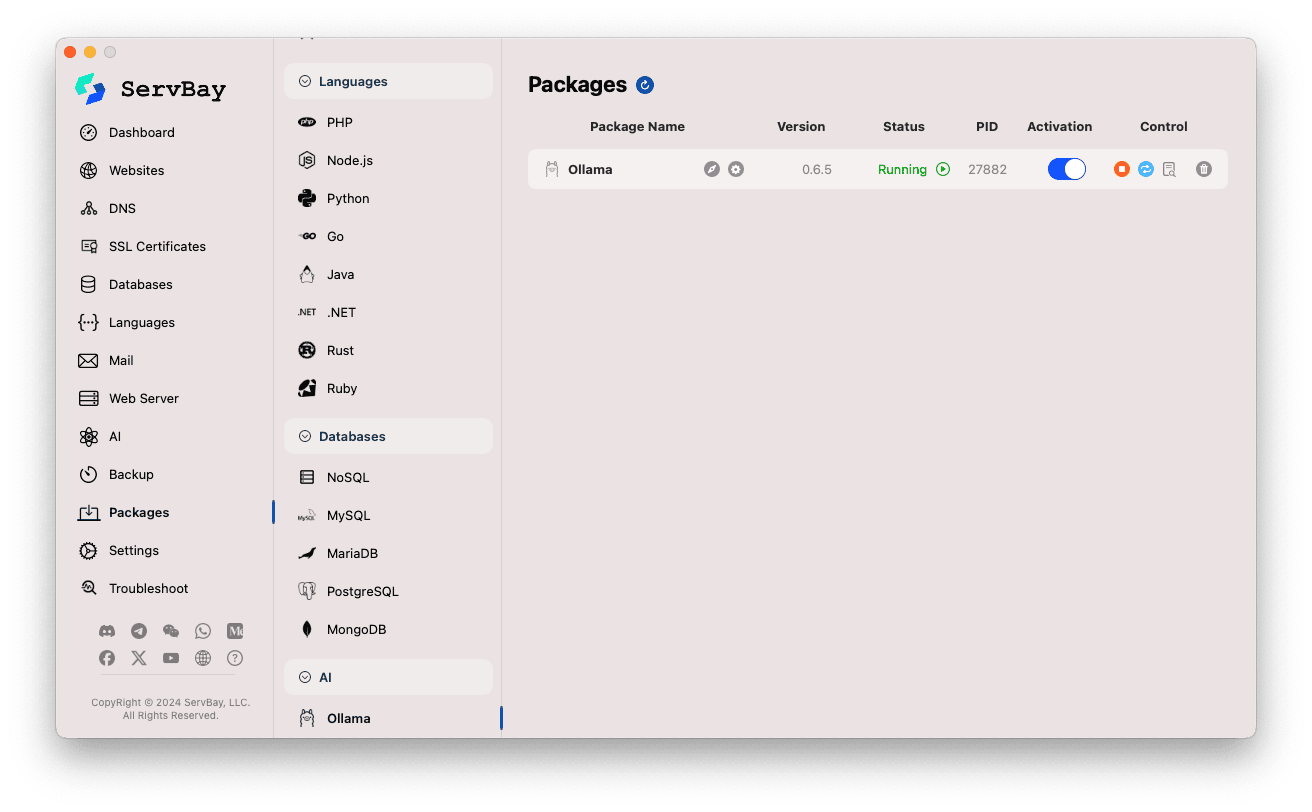
Akses Pakej Ollama:
- Buka aplikasi ServBay.
- Pada bar navigasi sebelah kiri, klik
Pakej(Packages). - Dalam senarai yang terbuka, cari dan klik kategori
AI. - Klik
Ollama.
Urus Perkhidmatan Ollama:
- Di kawasan sebelah kanan, anda akan melihat maklumat status pakej Ollama termasuk nombor versi (contoh
0.6.5), status operasi (RunningatauStopped), dan ID proses (PID). - Gunakan butang kawalan di sebelah kanan:
- Mula/Henti: Butang bulat oren digunakan untuk memulakan atau menghentikan perkhidmatan Ollama.
- Hidup Semula: Butang segar semula biru digunakan untuk menghidupkan semula perkhidmatan.
- Konfigurasi: Butang gear kuning untuk ke halaman konfigurasi Ollama.
- Padam: Butang tong sampah merah untuk nyahpasang pakej Ollama (gunakan dengan cermat).
- Maklumat lanjut: Butang maklumat kelabu mungkin menawarkan maklumat tambahan atau akses log.
- Di kawasan sebelah kanan, anda akan melihat maklumat status pakej Ollama termasuk nombor versi (contoh
Mengkonfigurasi Ollama
ServBay menyediakan antara muka grafik untuk melaraskan parameter operasi Ollama mengikut keperluan anda.
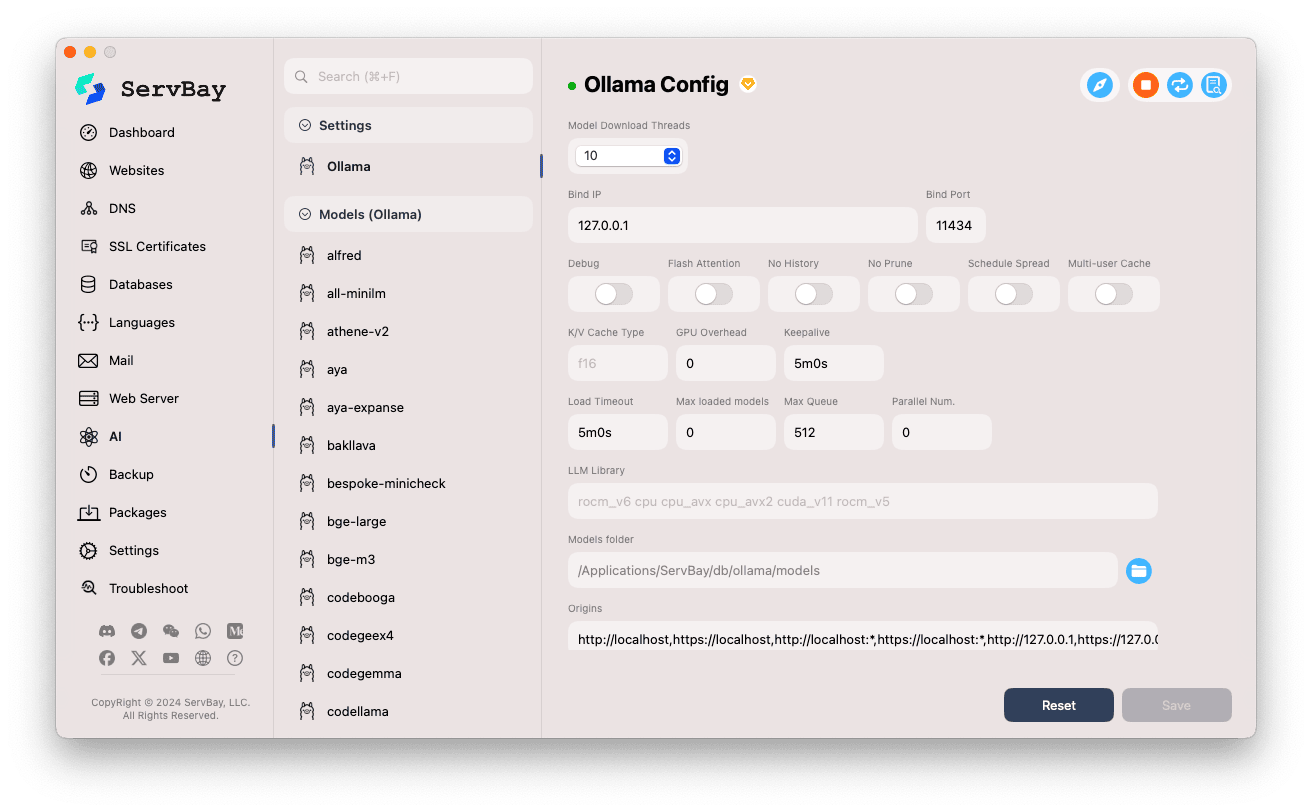
Akses Halaman Konfigurasi:
- Buka aplikasi ServBay.
- Pada bar navigasi sebelah kiri, klik
AI. - Dalam senarai yang terbuka, cari dan klik kategori
Tetapan (Settings). - Klik
Ollama.
Laraskan Pilihan Konfigurasi:
- Model Download Threads: Tetapkan bilangan threads untuk muat turun model serentak bagi mempercepat proses.
- Bind IP: Alamat IP tempat Ollama akan mendengar sambungan. Lalai ialah
127.0.0.1(hanya boleh diakses tempatan). - Bind Port: Port yang digunakan oleh Ollama. Lalai ialah
11434. - Pilihan Suis Boolean:
Debug: Aktifkan mod nyahpepijat.Flash Attention: Aktifkan pengoptimuman Flash Attention jika disokong perkakasan.No History: Tidak menyimpan sejarah sesi.No Prune: Tidak membersihkan model tidak digunakan secara automatik.Schedule Spread: Berkaitan polisi penjadualan.Multi-user Cache: Berkaitan cache untuk multi-pengguna.
- K/V Cache Type: Jenis cache Key/Value, memberi kesan kepada prestasi dan penggunaan memori.
- Berkaitan GPU:
GPU Overhead: Konfigurasi beban kerja GPU.Keepalive: Tempoh GPU kekal aktif.
- Pemuatan Model & Barisan:
Load Timeout: Masa tamat untuk pemuatan model.Max loaded models: Bilangan model maksimum yang dimuat dalam memori serentak.Max Queue: Panjang maksimum barisan permintaan.Parallel Num.: Bilangan permintaan diproses secara selari.
- LLM Library: Tentukan laluan pustaka LLM yang ingin digunakan.
- Models folder: Direktori tempatan di mana Ollama memuat turun dan menyimpan model. Lalai ialah
/Applications/ServBay/db/ollama/models. Anda boleh klik ikon folder untuk membukanya dalam Finder. - origins: Konfigurasi sumber yang dibenarkan untuk akses API Ollama (tetapan CORS). Lalai menyertakan alamat tempatan yang biasa (
http://localhost,https://localhost,http://127.0.0.1,https://127.0.0.1dll.). Tambah domain di sini jika ingin mengakses API dari aplikasi web di domain lain.
Simpan Konfigurasi: Selepas mengubah suai konfigurasi, klik butang
Savedi bawah kanan untuk mengaktifkan perubahan.
Mengurus Model Ollama
ServBay memudahkan penemuan, muat turun, dan pengurusan model Ollama.
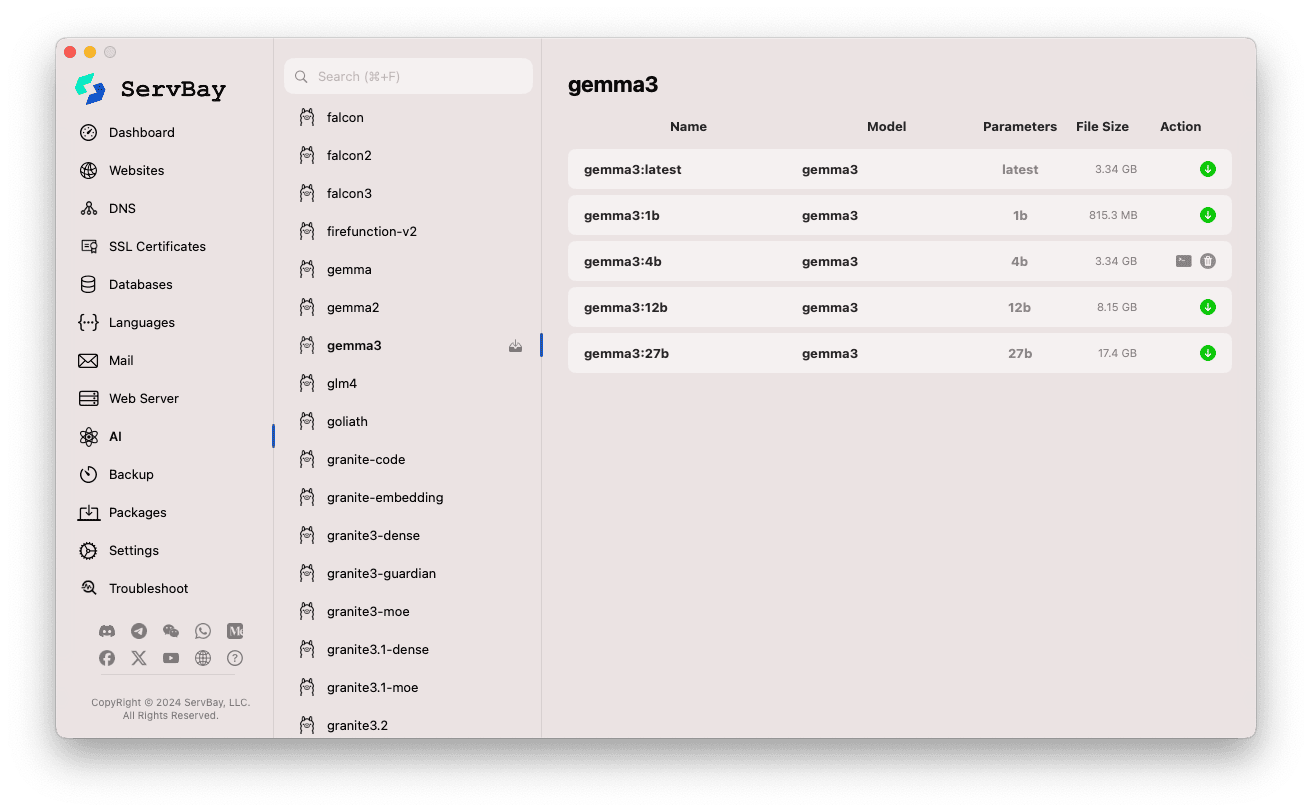
Akses Halaman Pengurusan Model:
- Buka aplikasi ServBay.
- Pada bar navigasi sebelah kiri, klik
AI. - Dalam senarai yang berkembang, cari dan klik
Models (Ollama).
Terokai & Muat Turun Model:
- Di sebelah kiri dipaparkan pelbagai perpustakaan model yang disokong oleh Ollama (cth.
deepseek-r1,deepseek-v3,qwen3,gemma,llama3,mistraldan lain-lain). Klik nama perpustakaan, misalnyagemma3. - Sebelah kanan akan memaparkan varian atau versi berbeza dalam perpustakaan itu, biasanya mengikut saiz parameter (
latest,1b,4b,12b,27bdan sebagainya). - Setiap baris menyenaraikan nama model, asas model, bilangan parameter, saiz fail.
- Klik butang anak panah muat turun hijau di paling kanan untuk memulakan muat turun model. Kemajuan muat turun akan dipaparkan. Anda boleh tingkatkan kelajuan dengan melaraskan
Model Download ThreadsdalamSettings. - Untuk model yang telah dimuat turun, butang tersebut akan menjadi kelabu atau tidak boleh diklik.
- Di sebelah kiri dipaparkan pelbagai perpustakaan model yang disokong oleh Ollama (cth.
Urus Model Dimuat turun:
- Model yang telah dimuat turun biasanya akan diberi penanda yang jelas dalam senarai (seperti butang download kelabu atau muncul butang padam).
- Anda boleh klik ikon padam (tong sampah) untuk memadam fail model tempatan dan melepaskan ruang cakera.
Menggunakan API Ollama
Setelah Ollama dimulakan, ia menyediakan perkhidmatan REST API pada Bind IP dan Bind Port yang anda tetapkan (lalai: 127.0.0.1:11434). Anda boleh berinteraksi dengan model yang telah dimuat turun menggunakan mana-mana klien HTTP seperti curl, Postman, atau pustaka bahasa pengaturcaraan.
TIP
ServBay menawarkan domain yang mudah digunakan, dienkripsi SSL/TLS serta menyokong capaian HTTPS: https://ollama.servbay.host
Anda boleh menggunakan nama domain https://ollama.servbay.host sebagai ganti IP:port untuk mengakses API Ollama.
Contoh: Berinteraksi dengan model gemma3:latest dimuat turun menggunakan curl
Pastikan anda telah memuat turun model gemma3:latest melalui ServBay dan perkhidmatan Ollama sedang berjalan.
bash
# Menggunakan https yang disediakan ServBay
curl https://ollama.servbay.host/api/generate -d '{
"model": "gemma3:latest",
"prompt": "Why is the sky blue?",
"stream": false
}'
# Atau melalui cara tradisional IP:Port
#curl http://127.0.0.1:11434/api/generate -d '{
# "model": "gemma3:latest",
# "prompt": "Why is the sky blue?",
# "stream": false
#}'Penjelasan Arahan:
http://127.0.0.1:11434/api/generate: Endpoint API Ollama untuk penjanaan teks.-d '{...}': Menghantar tubuh permintaan POST, mengandungi data JSON."model": "gemma3:latest": Nama model yang ingin digunakan (mesti telah dimuat turun)."prompt": "Why is the sky blue?": Soalan atau arahan yang ingin dihantar kepada model."stream": false: Jikafalse, balasan dikembalikan penuh sekali gus. Jikatrue, token dijana secara streaming.
Output Dijangka:
Anda akan melihat respons JSON dalam terminal dengan medan response yang mengandungi jawapan model kepada "Why is the sky blue?".
json
{
"model": "gemma3:latest",
"created_at": "2024-...",
"response": "L angit kelihatan biru kerana fenomena dipanggil Rayleigh scattering...",
"done": true,
// ... metadata lain
}Perhatian CORS: Jika anda ingin mengakses API Ollama dari kod JavaScript dalam pelayar, pastikan alamat asal aplikasi web anda (cth http://myapp.servbay.demo) telah ditambah ke senarai origins dalam konfigurasi Ollama. Jika tidak, permintaan anda mungkin disekat oleh pelayar kerana polisi CORS.
Senario Penggunaan
Menjalankan Ollama secara tempatan dalam ServBay memberi banyak kelebihan:
- Pembangunan AI Tempatan: Bangunkan dan uji aplikasi berasaskan LLM tanpa perlu bergantung kepada API luaran atau awan.
- Reka Bentuk Prototip Pantas: Cuba pelbagai model sumber terbuka secara fleksibel untuk menguji idea dengan cepat.
- Penggunaan Luar Talian: Boleh digunakan walaupun tanpa sambungan internet.
- Privasi Data: Semua data dan interaksi kekal di komputer anda, tanpa perlu bimbang ia dihantar ke pihak ketiga.
- Penjimatan Kos: Elakkan kos perkhidmatan AI awan berdasarkan penggunaan.
Perhatian
- Ruang Cakera: Fail model bahasa besar biasanya sangat besar (beberapa GB hingga puluhan GB). Pastikan cakera keras anda mempunyai ruang mencukupi. Model secara lalai disimpan di
/Applications/ServBay/db/ollama/models. - Sumber Sistem: Menjalankan LLM memerlukan banyak CPU, RAM, dan mungkin GPU anda. Jika Mac anda mempunyai GPU serasi, Ollama boleh mempercepat prestasi tetapi ini juga menggunakan sumber GPU. Pastikan spesifikasi Mac anda cukup untuk model yang ingin dijalankan.
- Masa Muat Turun: Muat turun model mengambil masa bergantung kepada saiz fail dan kelajuan rangkaian anda.
- Firewall: Jika anda menetapkan
Bind IPke0.0.0.0untuk membenarkan akses daripada peranti lain dalam rangkaian, pastikan firewall macOS membenarkan sambungan masuk ke port yang digunakan Ollama (11434).
Ringkasan
Dengan mengintegrasikan Ollama, ServBay sangat memudahkan proses deployment dan pengurusan model bahasa besar secara tempatan di macOS. Melalui antara muka grafik yang intuitif, pembangun boleh mudah memulakan servis, laras tetapan, muat turun model, serta memulakan pembangunan dan eksperimen aplikasi AI secara tempatan—seterusnya meningkatkan nilai ServBay sebagai persekitaran pembangunan tempatan serba lengkap.
